前段时间笔者的客户遇到了一个主从延迟导致的业务故障,故障的原因本来是较为简单易查的,但是由于客户环境的安全、保密性要求,监控和指标只能间接获知,信息比较片段化与迟缓。
不过这反而致使整个排查过程变得更加有分享和借鉴价值。在这里分享给大家希望可以让大家避免踩坑。
当时涉及到了主从延迟,慢查询,cursor的不当使用等mongodb问题,本文将从这几个方面全面复盘整个故障的排查过程,其中包含了如下内容:
● 背景(简单介绍背景情况)● 临时应对与考量(该情况下快速恢复业务的选择)
● 深究与排查
● 主从延迟分析与排查,并通过部分mongo源码佐证推断
● 通过慢查询定位异常业务
● 根据迟来的监控指标确认cursor的异常并分析
● 验证与总结
背景
9月初我们的某客户反馈,部署在其私有云中的Teambition系统存在异常。该客户通过调用系统的开放API包装了一层业务向内部提供,此时两个连续接口调用之间出现了数据一致性异常,导致包装的上层业务无法正常使用,而此时Teambition系统本身业务使用均正常。
接到反馈后我们与对方同步了其包装的业务逻辑,大体为:
● 调用接口A(可简单认为insert了一条数据a)● 调用接口B(可简单认为insert了一条数据b,但在insert之前检查了接口A返回的数据a的_id)
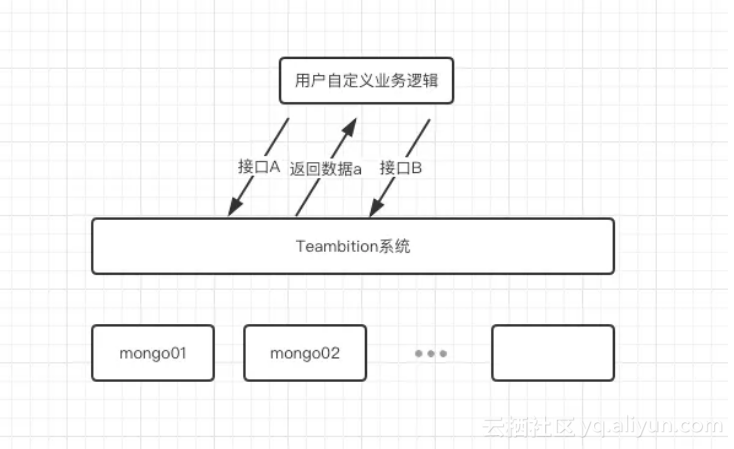
现象为在第二步的过程中,无法查找到第一步中”新建的任务_id”。考虑到该客户使用的是MongoDB复制集架构,并且第二个接口的query使用了SecondaryPreferred,由于此时我们无法连接到数据库查看指标也无法查看到客户处该mongodb集群的监控信息,根据已有信息初步判断故障原因可能为“主从延迟”导致的数据一致性问题。
临时应对与考量
我们知道MongoDB的主从同步为异步同步,主从节点之间延迟在所难免,但是正常情况下延迟时间大多为毫秒级别,大多不会影响到正常业务。此时的现象透露着一个信息,该MongoDB集群存在异常,但是由于第一时间无法获取集群状态,具体的异常暂时无从得知。
由于该上层业务重要性较高,摆在面前的首要情况是恢复该业务的可用性,综合考虑后,得出了如下的几种处理方式:
● 取消SecondaryPreferred,以保证调用接口正常● 不调整接口B的逻辑,在上层调用接口A和B之间加一层保护,通过业务的手段避免在短时间内进行连续的调用,通过业务形态的微调拉长A与B接口调用之间的时间轴,如:先交由用户配置所需字段,在提交时再进行任务_id的判断与绑定。
● 解决主从延迟。
在上述三种方案中,我们选择了方案1“取消SecondaryPreferred”来作为应急处理方案。原因如下:
● MongoDB的读写分离并不是真正意义上的将读写压力完全分离,Primary上的写最终还是以oplog的形式在从上进行了回放,读写分离的效果有限,所以在判断集群整体压力处于合理范围内,我们考虑取消
● 方案2需要客户包装上层业务进行修改,而客户的接口调用场景极多,故而放弃。(虽然放弃该方案,但是需要提醒的是,在任何涉及到数据一致性要求的业务场景都需要充分考虑到异常和可能性,在业务层尽可能的规避。这也是为什么有主从延迟的时候Teambition系统本身并未)
● 由于短时间内我们无法查看客户处mongodb集群的状态与监控指标,方案3实现周期长于前两者,故而放弃。
在我们将SecondaryPreferred的配置取消后,上层业务恢复了正常。我们也辗转获得了客户处mongodb集群的部分监控信息、状态等。
梳理后总结为:
● 流量稳定无暴增● QPS处于低位运行,且业务场景读远大与写
● Connections连接数稳定,并无暴增暴减
● Resident Memory稳定,且整体eviction状态良好
● Cache Activitiy稳定无暴增
● 主从延迟不稳定,有时飙升至5s
● 存在local.oplog.rs的slow query
在此,我们对故障的排查进行一次复盘。
首先从最直观的问题进行入手,观察到 db.printSlaveReplicationInfo()返回的结果和客户处集群的可视化监控显示主从延迟不稳定,会不时飙升至5s,如:
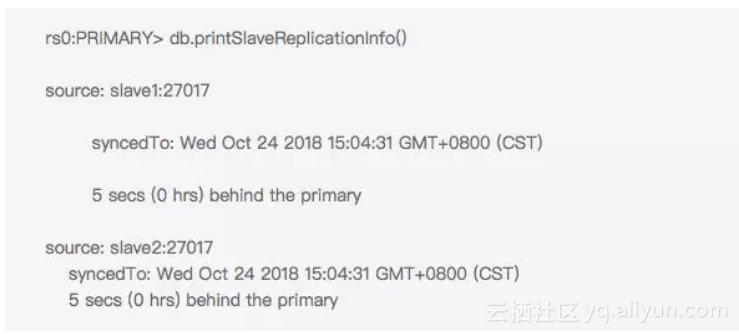
主从复制延迟是一个非常严重且影响业务的指标,此处显示的5s的时间在有读写分离的场景中已经可以认为是非常影响业务的。
不过我们也需要额外注意,该值不为0并不能100%代表系统存在主从延迟问题。我们先来看看db.printSlaveReplicationInfo()的结果是如何获取的。
在mongodb源码中定义了这样的计算方式

我们可以看到,基准时间是primary节点的optimeDate(将其定义为startOptimeDate),各个从节点的延迟是按照startOptimeDate – st(也就是各个从节点的optimeDate)进行计算(不包括arbiter)。
看起来该值的计算并没有什么问题,但是在某类场景下,db.printSlaveReplicationInfo()的返回值(即主从延迟)并没有那么贴切。如:
● 集群正处于写操作极为空闲的阶段● 在ISODate(“2018-10-24T07:00:05Z”)进行了一个写操作a(insert/update/delete)
● 而后在ISODate(“2018-10-24T07:00:30Z”)才进行了下一个写操作b
● 此时我们正好在1ms后于primary节点中执行了db.printSlaveReplicationInfo()
● 此时primary的optimeDate为ISODate(“2018-10-24T07:00:30Z”),而由于我们执行该命令的时候各个从节点完成同步,所以各个从节点的optimeDate为ISODate(“2018-10-24T07:00:05Z”)。于是乎我们得到了这样的返回
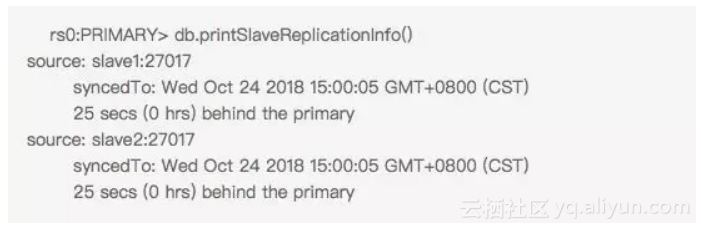
看起来从节点落后了主节点25秒的时间,十分严重。但是由于场景的特殊性,此时落后的是1个写操作,并且因为执行时间的原因,该写操作后续很快也完成了同步。此时的25secs对于集群来说影响甚微。
回归到此次故障的场景,虽然db.printSlaveReplicationInfo()存在不准确的可能,但是以当时的pqs情况来判断,应该是真实出现了主从延迟。
接下来尝试分析为何会出现主从延迟,从之前梳理的集群状态来看,除去主从延迟和local.oplog.rs的slow query,其他指标均十分健康(并不是)。
一般主从延迟有以下几种可能原因:
● 集群节点间网络延迟(客户网络工程师反馈节点间网络正常,该可能排除)● 从节点的磁盘性能不足(客户在当时并未提供io和吞吐情况,不过按照当时的低位qps,不应当会有磁盘性能问题,暂时排除)
● 主节点有大量并发写导致从节点无法及时追上(当时qps处于低位,replWriter为默认线程数,不应存在瓶颈,暂时排除)
● 主节点上存在某些异常的慢查询,影响了从节点上producer thread拉取oplog的效率,从而导致延迟(最有可能)
接下来我们将目光聚焦到了local.oplog.rs的慢查询上。
主要的慢查询主要的条件为如下,大多为getmore。
![]()
可以看到上述慢查询有几个特点:
● 是针对oplog.rs的慢查询● 类型为getmore
● 体现了若干游标定义
从上面的特点我们可以判断这类语句不会是正常业务场景,也不是A或B接口触发的,回顾下整个服务体系中会对oplog.rs有如此查询的为trace oplog的场景,来源于一个从mongodb同步数据到elasticsearch的应用。该应用会实时trace oplog 并进行同步。检查了下服务代码,部分如下:

我们知道oplog是没有严格意义上的索引,所以这类游标在第一次建立的时候会比较耗时,持续trace到最后的末尾的时候会处于tailabled和awaitData状态,此时实时trace数据的getmore就应该处于相对稳定的快速状态。
而当时系统内大量的getmore成为了slow query,考虑到当时整体qps情况,我们 对slow query和代码进行仔细的查看。发现了端倪:
slow query内getmore存在这个属性。

而代码中游标加入了这个属性

当时只是感觉到该服务使用游标的方式存在不妥,还未能完整与现象关联起来,记得上文中提到当时的整体常用监控指标都十分“健康”(这里埋下了一个伏笔),此时从客户处有获知了另一个监控指标–cursor数,客户告知当时主节点cursor总数为7200k+个。
至此,我们大体推断出了根因。
● 同步业务代码在建立cursor时,使用了tailable,awaitData,且noCursorTimeout的定义,致使cursor在业务没有主动close的情况下,将永久存在。(并且此时cursor监听在primary节点中,后续我们新增了hidden member用于该业务的请求)。● 此前该业务出现过异常,从而导致服务不断异常与重启,累积了7200k+个notimeout的cursor,而每个cursor是有额外内存的消耗,从而导致主节点内存被无效的cursor占用(此处占用的内存不是wt cache,而是剩余的ram,所以此时监控的wt cache的相关指标都是正常的),但是每个请求除了利用wt cache外还是会产生外部ram的消耗,如connection,结果集临时存储等。此时从节点producer thread来拉取oplog的效率降低,进一步造成了主从延迟的产生。
在初步获取到了结论后,我们开始进行相应的验证。
验证1:大量cursor导致wt cache外的ram资源紧张,进而造成主从延迟。
为了释放cursor我们将节点实例重启并关闭同步服务,持续观察后,确认主从延迟情况不再出现恢复正常。将SecondaryPreferred重新启用,业务也一切正常。
验证2:在tailable,awaitData和noCursorTimeout定义下,服务异常重启会导致cursor不被释放,进而造成cursor堆积。
由于该服务采用pm2进行服务运行态管理,我们不断向其发送异常关闭的signal,pm2在其error后不断重启。期间观察db.serverStatus().metrics.cursor状态,发现db.serverStatus().metrics.cursor.open.noTimeout值持续上升堆积。确认了cursor堆积的原因。
让我们来梳理下这次故障的前因后果。
● 同步服务中不当的使用了noCursorTimeout的cursor。● 该服务异常重启多次造成了primary中cursor的堆积。
● cursor的堆积造成了异常的内存消耗(wt cache外的内存),进而影响到了从节点producer thread的效率,从而导致了主从延迟的产生。
● 而上层业务将A、B2个接口的调用包装后的场景由于SecondaryPreferred的原因,导致B接口异常,最终影响了业务的正常对外服务。
至此,这个问题算是完整落下帷幕,总结一下踩的坑以及如何避免
● 使用cursor时候不要使用noCursorTimeout能力,为cursor设置合理的timeout,由应用来控制timeout后的重试机制。以此来保证cursor的合理利用。● 由于该集群环境的监控以及状态无法直接查看只能通过客户转述,这个过程遗漏了很多信息也造成了很多时间的浪费,在有可能的情况下,mongodb的使用者还是需要对mongodb的全面指标进行监控,魔鬼往往隐藏在细节中。
● 避免对local库内表的操作,如果有骚操作的需求,必须明白自己在做什么,同时将骚操作安排在隐藏节点中进行(如果此次最初我们的业务使用的是隐藏节点,该问题就不会直接影响到业务)且新版本可以使用changestream来满足类似trace oplog的需求。
● db.printSlaveReplicationInfo()所体现的主从延迟并不一定真的代表延迟,但是该监控指标任何时候都需要提起120%的关注度。
● 合理利用读写分离,MongoDB的读写分离并不是真正意义上的将读写压力完全分离,需要明确业务对于数据一致性的需求,一致性要求强的场景避免SecondaryPreferred或者通过业务形态的调整避免该问题。
原文发布时间为:2018-11-7
本文作者:周李洋
