原文地址
译者观点:目前AI整体处于研究热点,很多领域离产业化还很远,比如本文中的主题如何制作聊天机器人,虽然各大厂都有不同涉足,但是涉及的领域有限,其实在各个细分领域都可以训练专用的聊天机器人。那么如何做就是个问题?本文介绍了通用的过程。我也只是碰到了,觉得不错,转发出来作为我的笔记,也供大家参考。
介绍
聊天机器人是“通过听觉或文本方法进行对话的计算机程序”。 Apple的Siri ,微软的Cortana , Google 智能 助理和亚马逊的Alexa是当今最受欢迎的四种会话代理商。 他们可以帮助您获取路线,查看体育比赛的分数,打电话给地址簿中的人,并可以订购170美元的玩具屋 。
这些产品都具有听觉界面,代理通过音频消息与您交谈。 在这篇文章中,我们将更多地关注在文本方面运行的聊天机器人。 Facebook长期以来一直在投资 FB Messenger机器人,这允许小型企业创建机器人来帮助提供客户支持和常见问题。 聊天机器人已经存在了相当长的时间(Siri在2011年发布),但直到最近,创建逼真有效的聊天机器人交互任务的方法才得以深入学习。
在这篇文章中,我们将研究如何使用深度学习模型在我的社交媒体对话中进行交流 。
问题空间
从较高的层面来看,聊天机器人的工作是确定它收到的任何给定消息的最佳响应。 这种“最佳”响应应该是(1)回答发送者的问题,(2)向发送者提供相关信息,(3)提出后续问题,或(4)以现实的方式继续对话。 这是一个非常高的订单。 聊天机器人需要理解发送者消息的意图,确定需要什么类型的响应消息(后续问题,直接响应等),并在形成响应时遵循正确的语法和词汇规则。
可以肯定地说,现代聊天机器人无法完成所有这些任务。 对于所有的进展,我们已经做了像这样的聊天机器人体验。
<iframe id="twitter-widget-2" scrolling="no" allowtransparency="true" allowfullscreen="true" class="twitter-tweet twitter-tweet-rendered" style="position: static; visibility: visible; display: block; width: 500px; height: 679.783px; padding: 0px; border: medium none; max-width: 100%; min-width: 220px; margin-top: 10px; margin-bottom: 10px;" data-tweet-id="765722701465948160" title="Twitter Tweet" frameborder="0"></iframe>
聊天机器人经常准备好了解我们的意图,无法正确获取信息,有时只是非常难以处理。 正如我们在本文中所看到的,深度学习是解决这一艰巨任务的最有效方法之一。
深度学习方法
使用深度学习的聊天机器人几乎都是序列到序列 (Seq2Seq) 模型的所有变体。 2014年,Ilya Sutskever,Oriol Vinyals和Quoc Le在该领域发表了一篇题为“用神经网络进行序列学习的序列”的论文 。 本文特别在机器翻译方面取得了很好的成果,但Seq2Seq模型已经发展成为包含各种NLP任务。

序列到序列模型在RNN和解码器RNN中编码(如果你在RNN上有点不稳定,请查看我以前的博客文章以进行复习)。 从高层次来看,编码器的工作是将信息封装在固定的表示中。 解码器将采用该表示,并生成最佳响应的文本的可变长度。
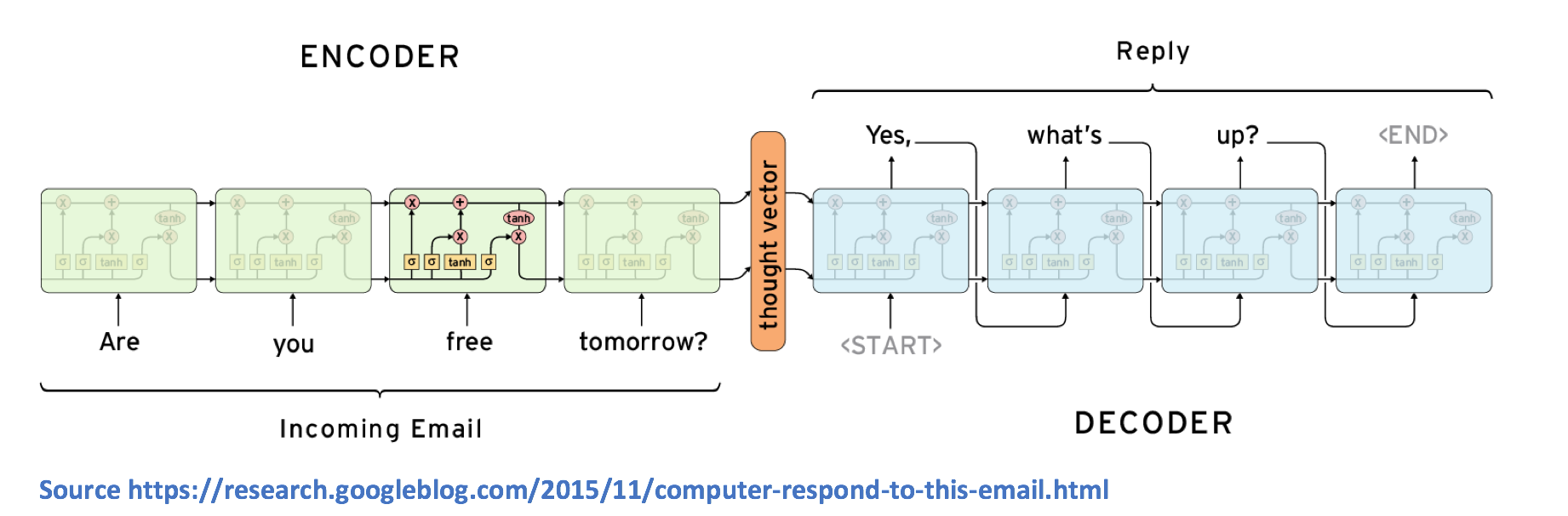
让我们更详细地看一下这个作品。 记住,RNN包含许多隐藏状态向量,每个向量代表前一个时间步骤的信息。 例如,第3个时间步的隐藏状态向量想要成为前3个字的函数。 通过该逻辑,编码器RNN的最终隐藏状态向量可以被认为是整个输入文本的非常准确的表示。
解码器是另一个RNN,它接收最终的隐藏状态。 我们来看看第一个细胞。 单元格的工作是接受向量表示,其词汇表中的哪个单词最适合输出响应。 从数学上讲,这意味着我们计算词汇表中每个单词的概率,并选择值的argmax。
第二个单元格想要成为矢量表示的函数,以及前一个单元格的输出。 LSTM的目标是估计以下条件概率。
[图片上传失败...(image-b3cc05-1532788409456)]
让我们解构这个等式意味着什么。 左侧是输出序列的概率,以给定的输入序列为条件。 右侧包含术语p(y t | v,y 1 ,...,y t-1 ),它是所有单词概率的向量,以矢量表示和前一时间步的输出为条件。 pi符号只是sigma(或求和)的乘法等价物。 右手侧可以缩小为p(y 1 | v)* p(y 2 | v,y 1 )* p(y 3 | v,y 1, y 2 )......等等。
在继续之前,我们先来看一个简单的例子吧。 我们来看一下输入文字。 鉴于“明天你有空吗?”,让我们考虑有多少人会回答这个问题。 大多数人都希望从“是”,“是的”,“否”等等开始。在我们完成网络训练之后,概率p(y 1 | v)希望成为一个看起来像以下。

我们需要计算的第二个概率p(y 2 | v,y 1 )想要成为该分布y 1的单词以及v的向量表示的函数。 Pi(产品)操作的结果想要给我们最可能的单词序列,我们将把它作为最终的答案。
序列模型最重要的特征之一是它提供的多功能性。 当您考虑传统的ML方法(线性回归,SVM)和深度学习方法(如CNN)时,这些模型需要固定大小的输入,并产生固定大小的输出。 必须知道输入的长度。 这是对机器翻译,语音识别和应答等任务的重大限制。 这些是我们不知道输入短语大小的任务,我们想考虑变量输出响应。 Seq2Seq型号具有这种灵活性。
自2014年以来,Seq2Seq模型已经有了很多改进,您可以访问本文的“有趣的论文”部分,以了解更多相关信息。
数据集选择
当我们考虑这样做时,我们需要训练模型。 对于序列到序列模型,我们需要大量的对话日志。 从高级别来看,该编码器解码器网络需要能够理解每个查询(编码器输入)所期望的响应类型(解码器输出)。 一些常见的数据集是康奈尔电影对话语料库 , Ubuntu语料库和微软社交媒体对话语料库 。
虽然大多数人互相训练和聊天,但他们或多或少只是一个有趣的应用程序。 有了这篇特别的帖子,我想看到我愿意。
来自哪里的数据?

好吧嗯,让我们看看我们如何做到这一点。 我们需要创建一个大型对话数据集,这些对话就是我在网上与人们进行的对话。 在社交媒体上,我一直在使用Facebook,Google Hangouts,SMS,LinkedIn,Twitter,Tinder和Slack与人们保持联系。
- Facebook:这是大部分培训数据的来源。 Facebook有一个很酷的功能 ,允许您下载所有Facebook数据的副本。 此下载内容包含您作为中学生编写的所有消息,照片以及全部大写,充满压力的状态。
- Google环聊:高中期间我肯定会在一群朋友身上使用它。 您可以按照这篇精彩博客文章中的说明提取聊天数据。
- 短信/短信:非常确定有一种方法可以获得所有先前聊天的存档(短信备份+是一个很好的应用程序),但我只是使用文本,所以不要认为这是值得的。
- LinkedIn:LinkedIn确实提供了一个工具来获取您的数据。
- Twitter:没有足够的私人消息对此有用。
- Tinder:嗯,是的,我只是说对话不是值得的数据集 ,
- Slack:刚刚开始使用它,只是有一些私人消息。
数据集创建
机器学习的很大一部分涉及数据集预处理。 来自每个来源的数据档案都有不同的格式,并包含我们并不真正需要的部分。
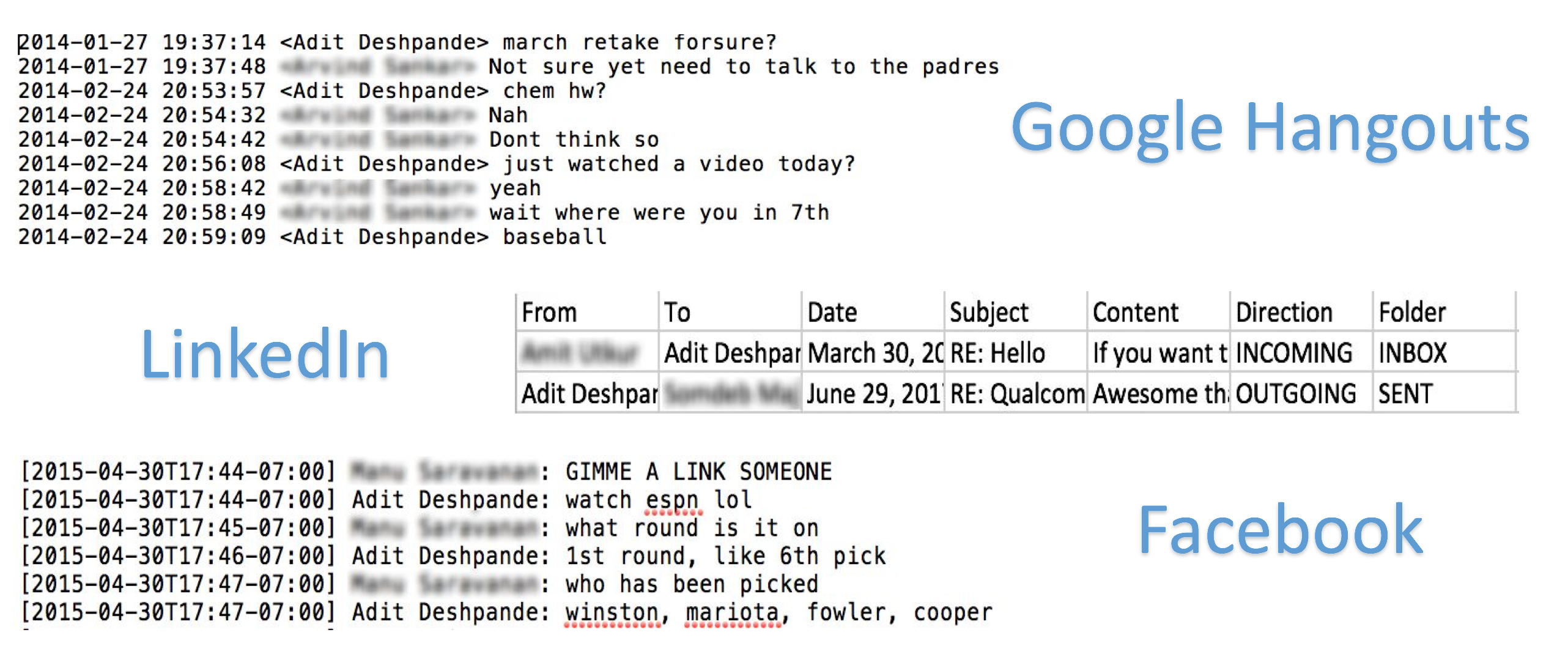
如您所见,环聊数据的格式与Facebook数据不同,LinkedIn消息采用CSV格式。 我们的目标是使用所有这些数据集,只需创建一个包含(FRIENDS_MESSAGE,YOUR_RESPONSE)形式的对的统一文件。
为此,我写了一个Python脚本,你可以在这里查看 。 此脚本想要创建两个不同的文件。 一个人希望成为一个包含所有输入输出对的Numpy对象(conversationDictionary.npy)。 另一个是一个大文本文件(conversationData.txt),它以对话形式一个接一个地包含这些对。 通常,我会说私人谈话是个好主意互联网。 但这里是最终数据集外观的快照。

单词向量
LOL。 LMAO。 跆拳道。 这些都经常出现在我们的对话数据文件中。 虽然它们在社交媒体领域很常见,但它们并不在很多传统数据集中。 通常,我接近任何NLP任务时的第一直觉是简单地使用预先训练的向量,因为它们在大型语料库中进行大量迭代。 然而,鉴于我们有许多单词和首字母缩写词,而不是典型的预训练单词向量列表。
为了生成单词向量,我们使用Word2Vec模型的经典方法。 基本思想是模型创建单词出现在句子中的单词。 具有相似上下文的单词希望在向量空间中靠近放置。 一个Word2Vec模型被创建和训练,请查看我的一个好朋友Rohan Varma撰写的这篇精彩博文 。
我在这个Python脚本中训练了Word2Vec模型,它将单词向量保存在Numpy对象中。
****更新:我了解到Tensorflow Seq2Seq函数从头开始训练单词,所以我最终不会使用这些单词向量,但它仍然是一个好习惯** ******
使用Tensorflow创建Seq2Seq模型
现在我们已经创建了数据集并生成了我们的单词向量,我们可以继续编写Seq2Seq模型。 我在这个Python 脚本中创建并训练了模型。 我已尽力将代码尽我所能,所以希望你能跟进。 在Tensorflow的embedding_rnn_seq2seq()函数中读取模型的关键。 你可以在这里找到它的文档。
跟踪培训进度
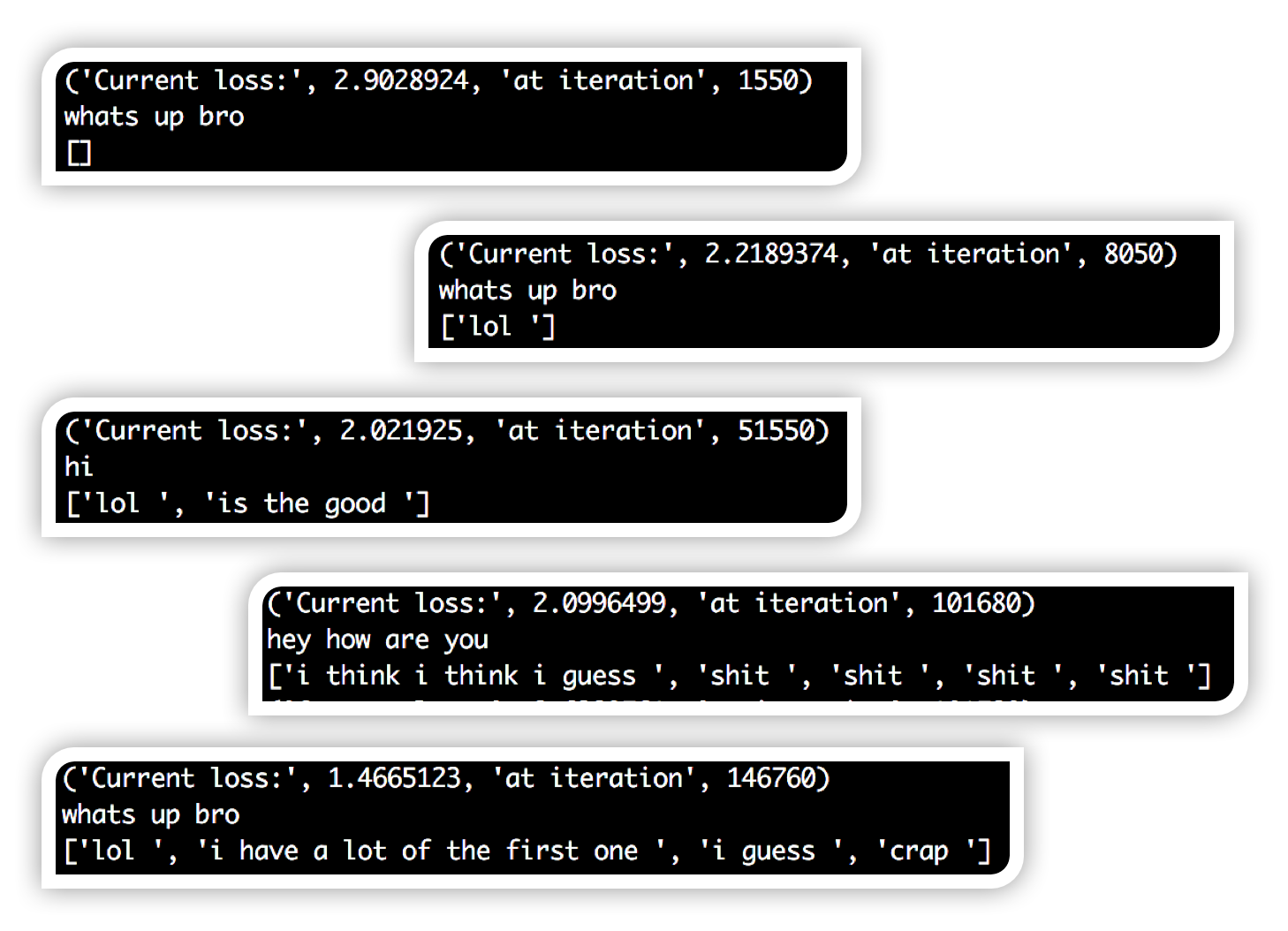
研究结果如下: 我在输入字符串上测试网络,并在输出中输出所有非填充和非EOS令牌。 首先,您可以看到响应主要是空白,因为网络输出填充和EOS令牌。 这是正常的,因为填充令牌是整个数据集中最常用的令牌。 然后,您可以看到网络开始为每个输入输出“lol”。 这很直观,因为'lol'经常被使用。 慢慢地,你开始看到更完整的想法和语法结构。 也可能是因为有点过度拟合。
设置Facebook Messenger Chatbot
现在我们有一个训练有素的Seq2Seq模型,让我们来看一个简单的FB messenger聊天机器人。 这个过程并不太难,因此完成教程需要不到30分钟。 基本的想法是我们使用一个简单的Express应用程序设置服务器,在Heroku上托管它,然后设置一个Facebook应用程序/页面连接到它。 除此之外不会涉及太多细节,因为我真的认为作者在逐步解释所有内容方面做得很好,但最后,你应该有一个像这样的Facebook应用程序。
[图片上传失败...(image-b9e0e3-1532788409455)]
你应该能够向你的机器人发送消息(这个初始行为只是回应它发送的所有内容)。
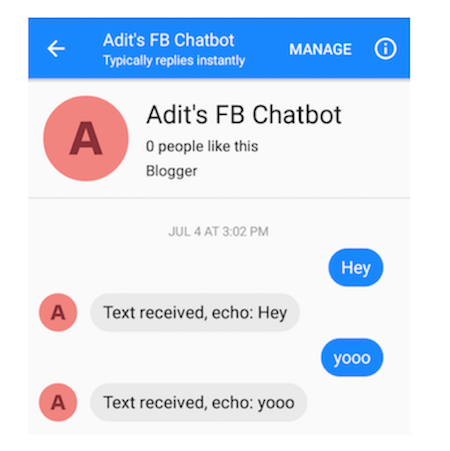
部署我们训练有素的Tensorflow模型
那么,现在是时候把所有东西放在一起了。 Tensoflow和Node(我不知道是否有官方支持的包装器),我决定使用Flask服务器部署我的模型,并让chatbot的Express应用程序与之交互。
你可以在这里查看Flask服务器代码和chatbot的index.js文件。
测试出来!
如果您想与此机器人聊天,请继续 按“发送消息”按钮 。 由于服务器需要启动,因此第一次响应可能需要一段时间。
更新6/13/18:FB用机器人更改了一些设置,所以我不确定Messenger机器人是否正常工作。 但是,您可以在命令提示符下使用CURL将POST请求发送到服务器。 基本上,转到您的终端/ Cmd提示符并输入:
curl -i -X POST -H'Content-Type:application / json'-d'{“message”:“在此插入你的消息”}'https://flask-server-seq2seq-chatbot.herokuapp.com/prediction
响应是发送我训练有素的聊天机器人会发送。
可能很难判断机器人是否真的像我一样说话(因为很多人没有和我在网上谈过LOL),但我会说它做得很好! 考虑到社交媒体标准,语法是可以接受的。 你可以选择一对好的结果,但它们非常荒谬。 天网绝对不是很快。
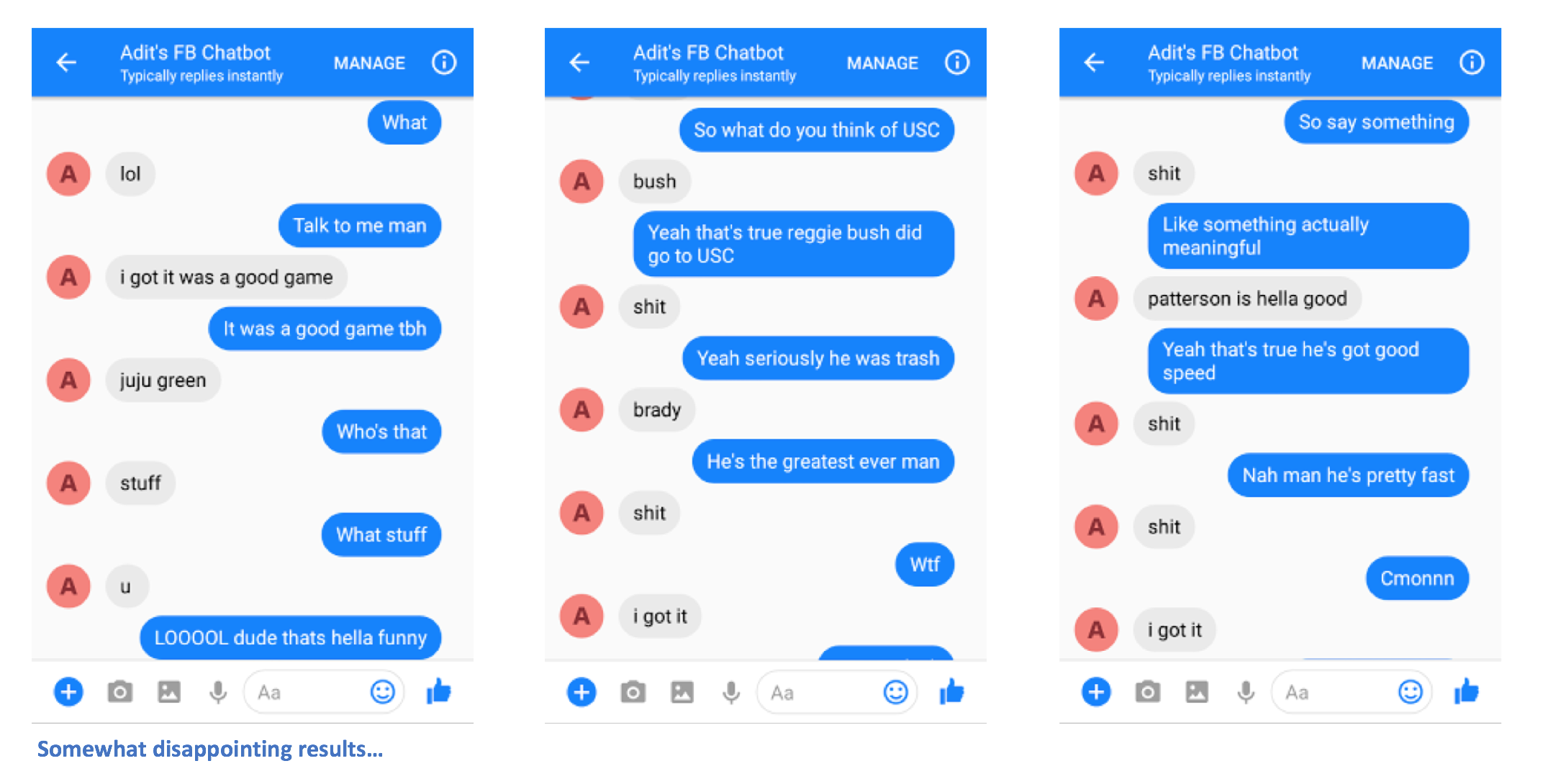
钢人队外接手Juju Smith-Schuster和负责金州勇士队的Draymond Green 。 有趣的组合。
好吧,让我们成为现实吧。 表现不是那么好。 让我们考虑一下如何改进它!
改善的方法
正如你可以通过与聊天机器人进行交互所说的那样,肯定有很大的改进空间。 在几条消息之后,它变得清晰起来。 chabtot不能连接在一起,而且一些答案是随机的和不连贯的。 以下是一些可以改善聊天机器人性能的方法。
- 合并其他数据集以帮助网络从更大的会话语料库中学习。 这将消除聊天机器人的一些“个性”,因为它现在严格训练我自己的谈话。 但是,我相信它会产生更真实的对话。
- 处理编码器消息与解码器消息无关的情况。 例如,一个会话结束,第二天开始新会话。 谈话的主题可能完全不相关。 这可能会影响模型的培训。
- 使用双向LSTM,注意机制和分组。
- 调整超参数,例如LSTM单元的数量,LSTM层的数量,优化器的选择,训练迭代的数量等。
您是否也想在评论中听到其他建议!
你如何建立自己的
如果您一直在跟随,那么您应该聊聊天。 让我们最后一次重复这些步骤。 GitHub repo README中提供了详细说明。
- 找到您与某人进行过对话的所有在线社交媒体网站,并下载您的数据副本。
- 使用CreateDataset.py或您自己的脚本提取所有(MESSAGE,RESPONSE)对。
- (可选)通过Word2Vec.py为我们的对话中显示的每个单词生成单词向量。
- 在Seq2Seq.py中创建,训练并保存序列到序列模型。
- 创建Facebook聊天机器人。
- 创建Flask服务器,部署保存的Seq2Seq模型。
- 在Express应用程序中编辑index.js文件,以便它可以与Flask服务器通信。