传统的方式是在想要的图片上鼠标点击右键另存为,或者用截图的方式保存图片,其实我们还可以通过使用简单的Python语言实现图片的下载并保存到本地,下面让我们看看如何实现吧
一、确定图片的URL地址及获取URL网页页面的信息
#coding:utf-8
fromurllib.requestimporturlopen #导入urlopen
defgetHtml(url):
page = urlopen(url)
html = page.read() #读取URL
returnhtml
html = getHtml("http://g.hiphotos.baidu.com/image/pic/item/8694a4c27d1ed21bd85def25a46eddc450da3f5e.jpg") #访问URL地址
print(html)
二、通过正则表达筛选想要的页面数据
www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
www.jianshu.com/p/6bc77094374a
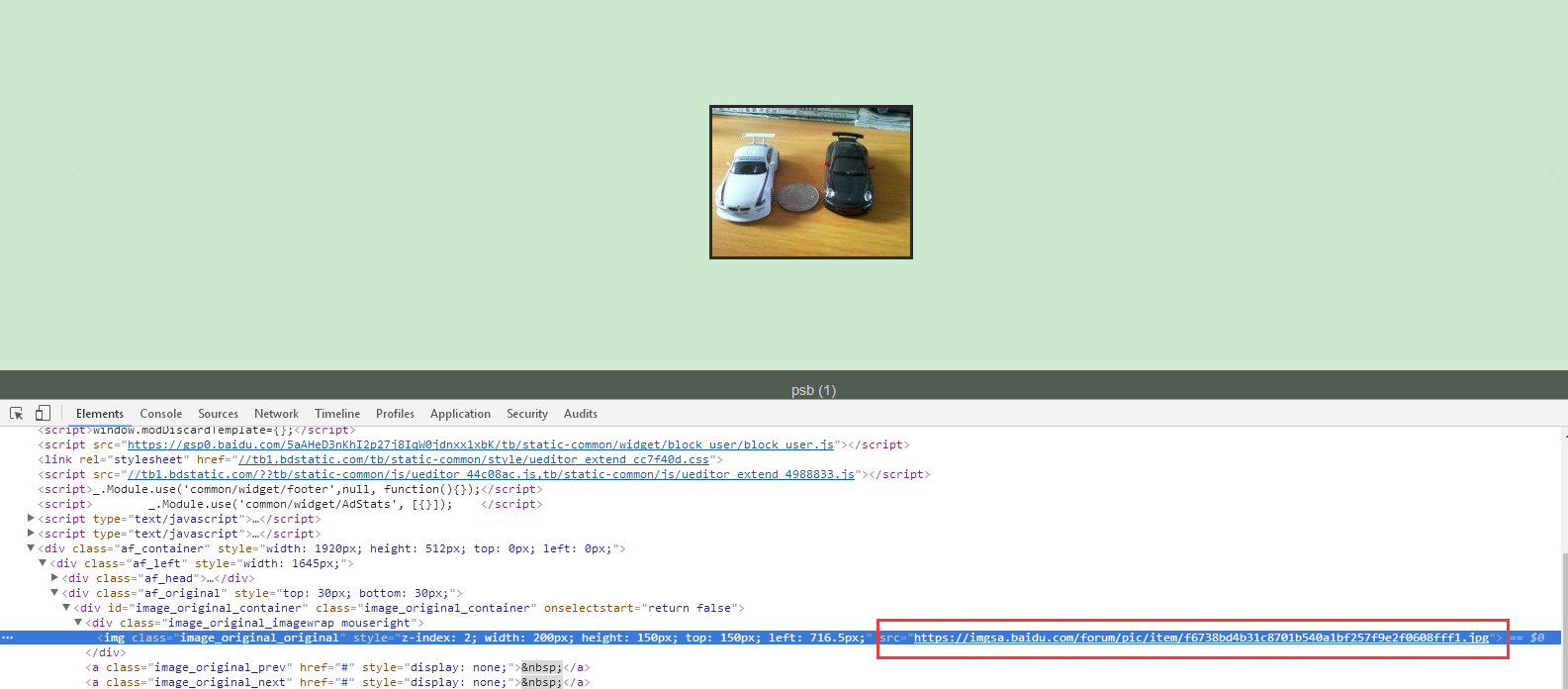
通过审查页面元素,可以找到图片的地址,如下:src=”https://imgsa.baidu.com/forum/pic/item/f6738bd4b31c8701b540a1bf257f9e2f0608fff1.jpg”
修改后代码如下:
#coding:utf-8
fromurllib.requestimporturlopen
importre
defgetHtml(url):
page = urlopen(url)
html = page.read()
returnhtml
defgetImg():
reg =r'src="(.+?\.jpg)" pic_ext' #通过正则表达获取图片数据
img = re.compile(reg)
img_list = re.findall(img,html)
returnimg_list
html = getHtml("http://g.hiphotos.baidu.com/image/pic/item/8694a4c27d1ed21bd85def25a46eddc450da3f5e.jpg")
print(html)
三、将获取的数据保存到本地
通过for循环遍历并下载到本地,代码如下:
#coding:utf-8
fromurllib.requestimporturlopen
importre
importurllib
defgetHtml(url):
page = urlopen(url)
html = page.read()
returnhtml
defgetImg():
reg =r'src="(.+?\.jpg)" pic_ext'
img = re.compile(reg)
img_list = re.findall(img,html)
x =0
forimgurlinimg_list:
urllib.urlretrieve(imgurl,'%s.jpg'% x) #urllib.urlretrieve()方法,下载并保留到本地
x +=1
html = getHtml("http://g.hiphotos.baidu.com/image/pic/item/8694a4c27d1ed21bd85def25a46eddc450da3f5e.jpg")
print(html)
