一、URLError(URL错误异常)
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。这种情况下,异常同样会带有"reason"属性,它是一个tuple(可以理解为不可变的数组),包含了一个错误号和一个错误信息。看下面的示例
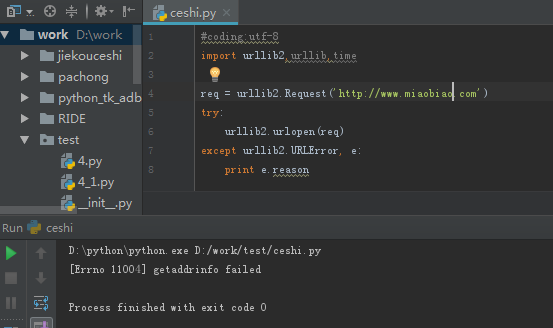
从程序中可以看到输出为:[Errno 11004] getaddrinfo failed,也就是说,错误号是11004,内容是getaddrinfo failed
二、HTTPError(HTTPError状态错误)
服务器上每一个HTTP 应答对象response包含一个数字"状态码"。有时状态码指出服务器无法完成请求。默认的处理器会为你处理一部分这种应答。例如:假如response是一个"重定向",需要客户端从别的地址获取文档,urllib2将为你处理。其他不能处理的,urlopen会产生一个HTTPError。典型的错误包含"404"(页面无法找到),"403"(请求禁止),和"401"(带验证请求)。HTTP状态码表示HTTP协议所返回的响应的状态。比如客户端向服务器发送请求,如果成功地获得请求的资源,则返回的状态码为200,表示响应成功。如果请求的资源不存在, 则通常返回404错误。 HTTP状态码通常分为5种类型,分别以1~5五个数字开头,由3位整数组成,如:200代表请求成功、304代表请求的资源未更新、400 代表非法请求,详情见HTTP状态码解析
HTTPError实例产生后会有一个整型'code'属性,是服务器发送的相关错误号。
Error Codes错误码:因为默认的处理器处理了重定向(300以外号码),并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。BaseHTTPServer.BaseHTTPRequestHandler.response是一个很有用的应答号码字典,显示了HTTP协议使用的所有的应答号。当一个错误号产生后,服务器返回一个HTTP错误号,和一个错误页面。你可以使用HTTPError实例作为页面返回的应答对象response。这表示和错误属性一样,它同样包含了read,geturl,和info方法。
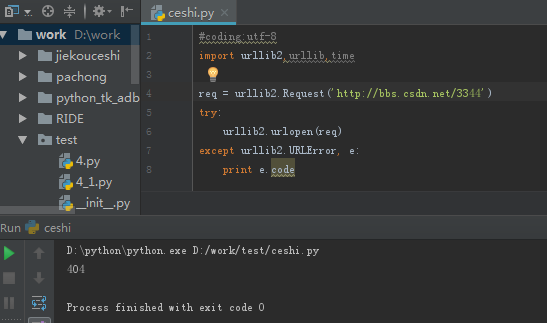
从程序中可以看到输出了404的错误码,也就说没有找到这个页面。
三、HTTP异常处理方式
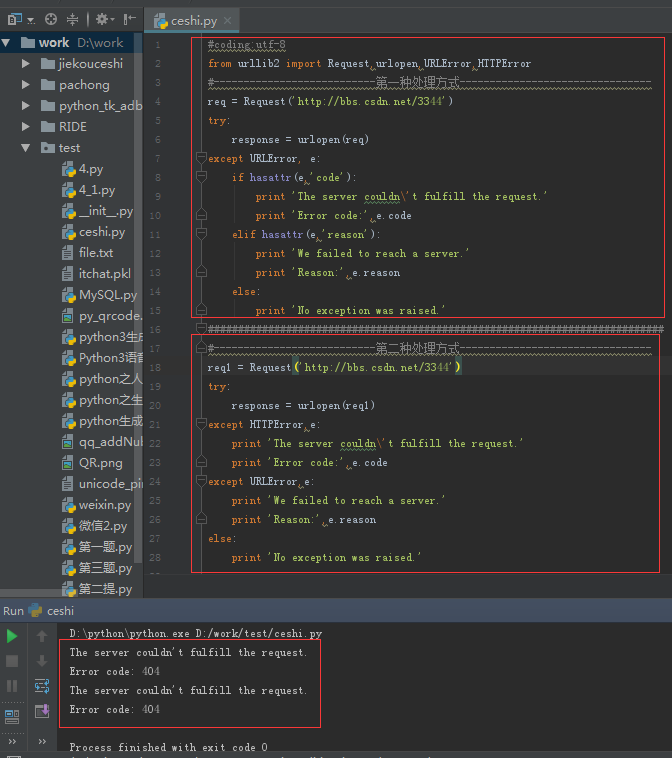
从示例中可以看到,两种方式都能输出异常:其中第二种中HTTPError必须写在URLError异常前,因HTTPError是URLError的子类,如果URLError在前面它会捕捉到所有的URLError(包括HTTPError )。


