项目说明
使用Python写网络爬虫之爬取百思不得姐视频并保存至文件示例
使用工具
Python2.7.X、pycharm
使用方法
在pycharm中创建一个爬取百思不得姐视频.py文件,并在当前目录下创建video文件夹来存放抓取的视频文件,撰写代码,运行代码,查看运行结果
操作原理
1.首先先了解正则表达式的使用方法,见:正则表达式
2.找到百思不得姐的视频主页URL:http://www.budejie.com/video/
通过火狐浏览器的fire bug工具分析,可以看出来,链接中class=j-r-list-c里就存在有对应的视频名称和视频链接;
然后,右击查看页面源码:
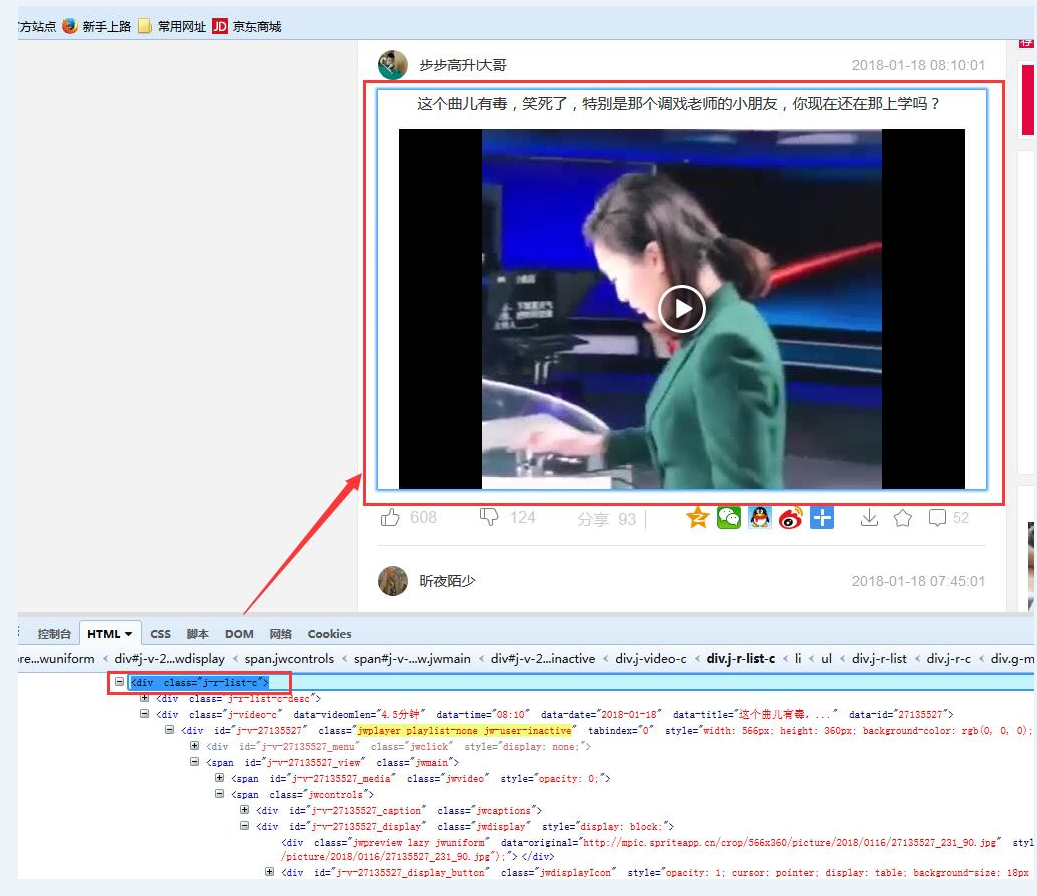
页面源码
下图为视频链接地址
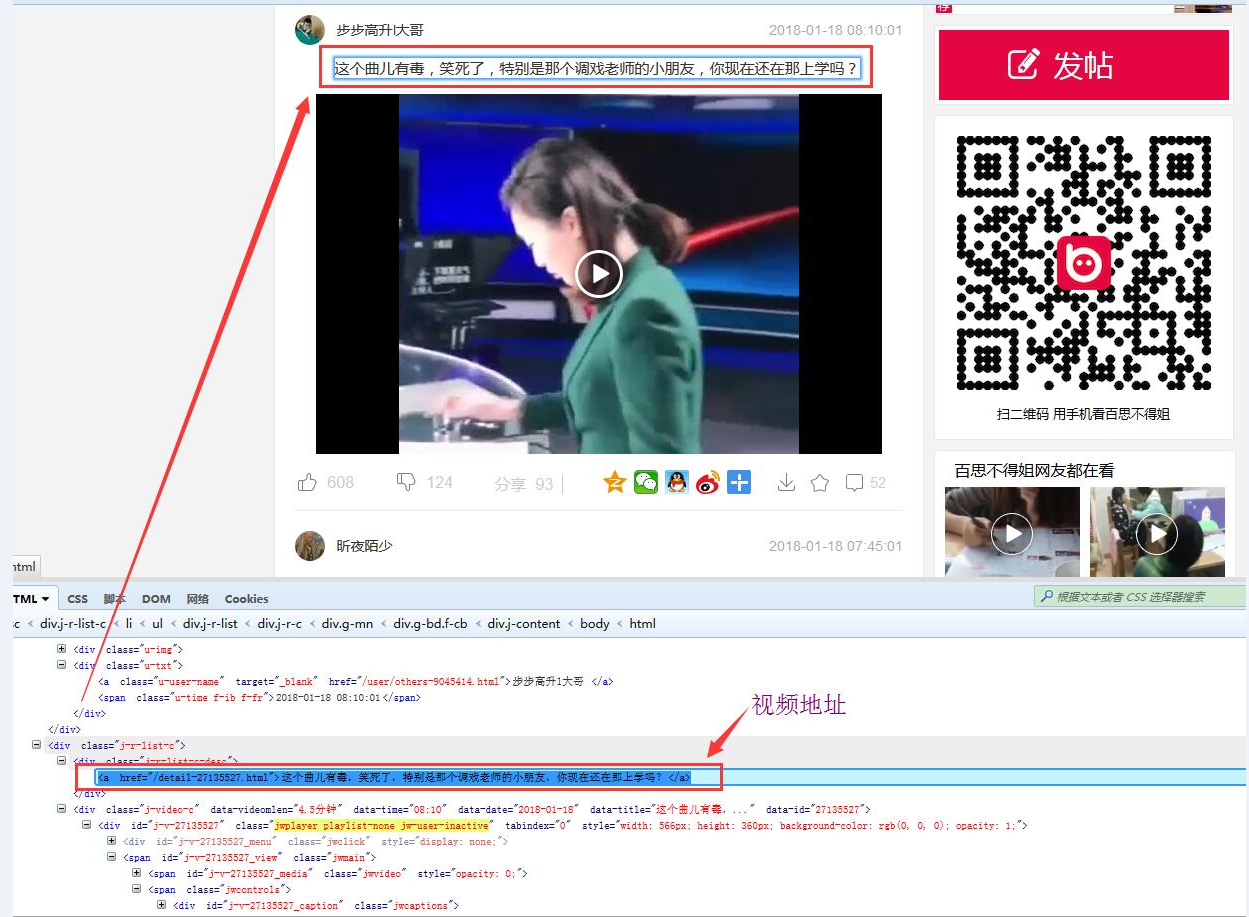
视频链接地址
程序代码:
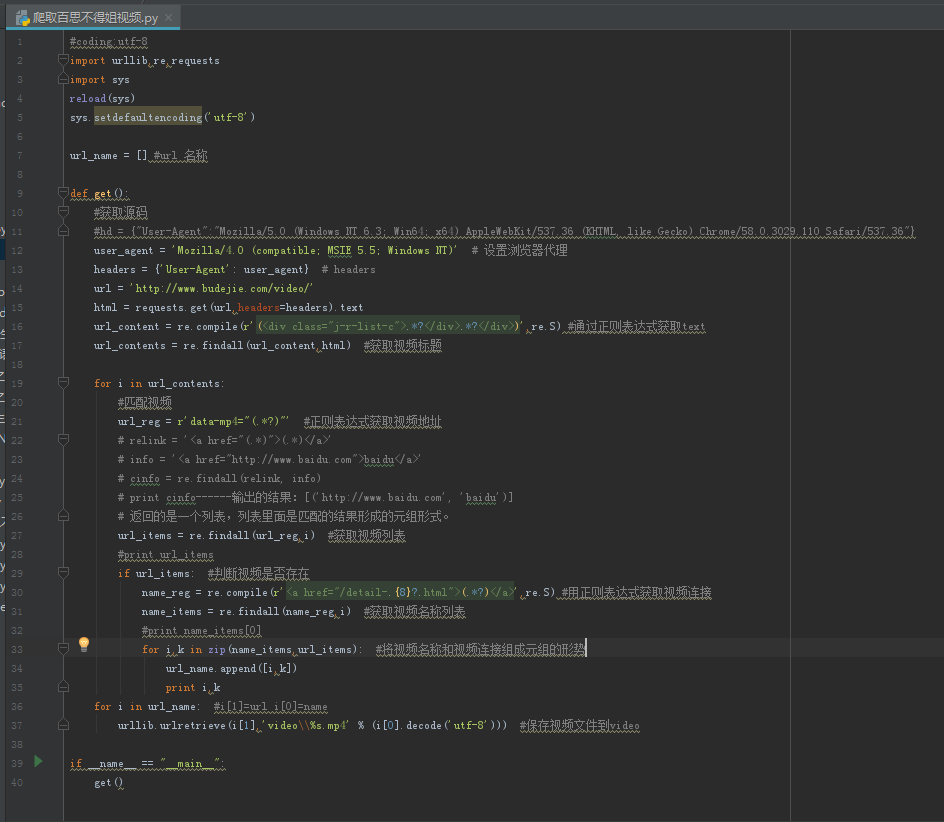
程序代码
运行结果:
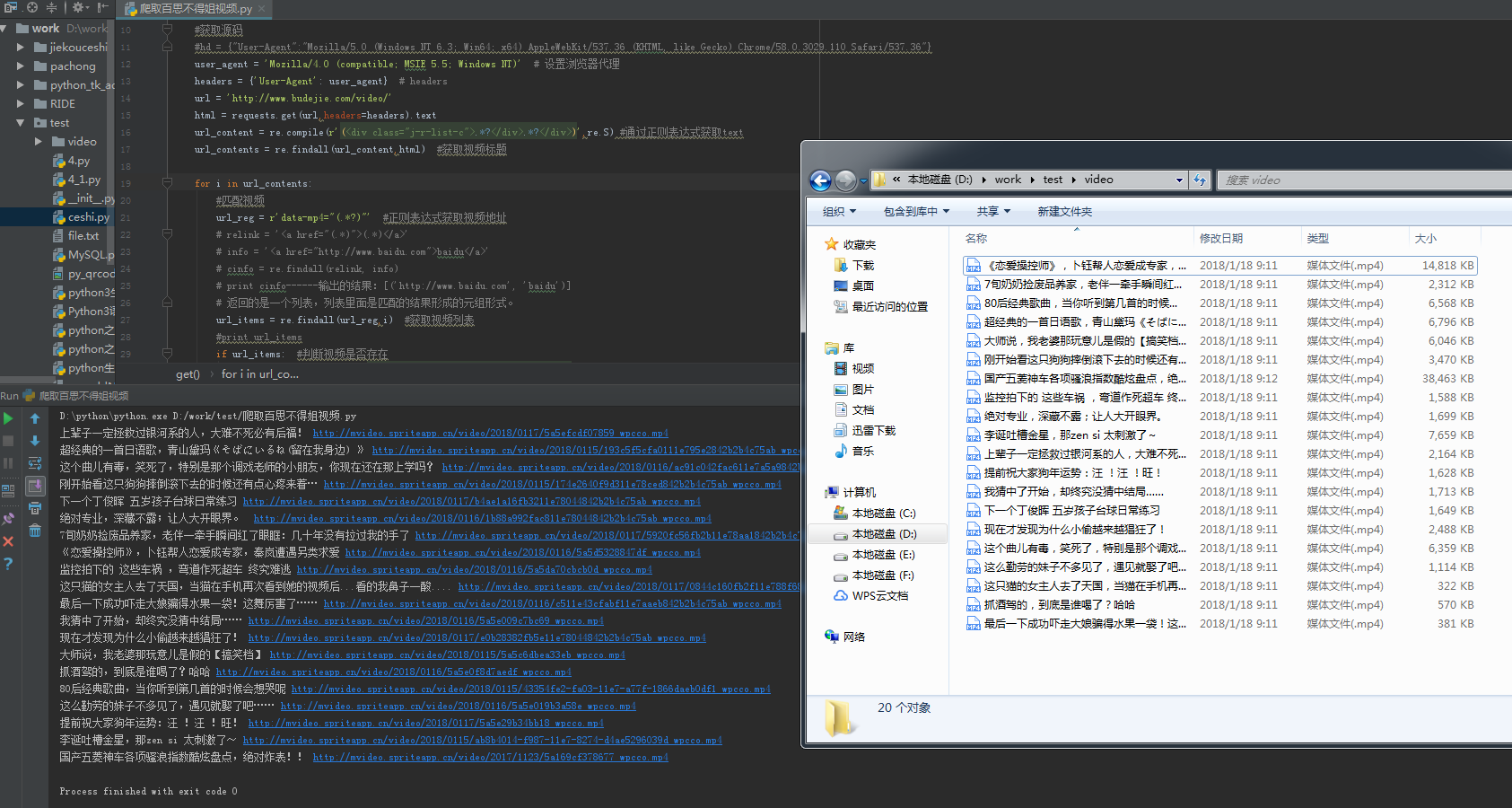
运行结果
可以看到,运行程序后在video文件夹中已经存放有爬取的视频名称和链接。



