
概述
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
离线数据同步在大数据分析,数据备份,数据同步等应用场景中都会被用到,所以本文特别介绍阿里开源的这款神器:DataX!
准备工作
-
环境准备:Linux服务器一台,安装有JDK8,maven和python 2.6+;
-
下载源码:https://github.com/alibaba/DataX.git
-
解压后编译源码:
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
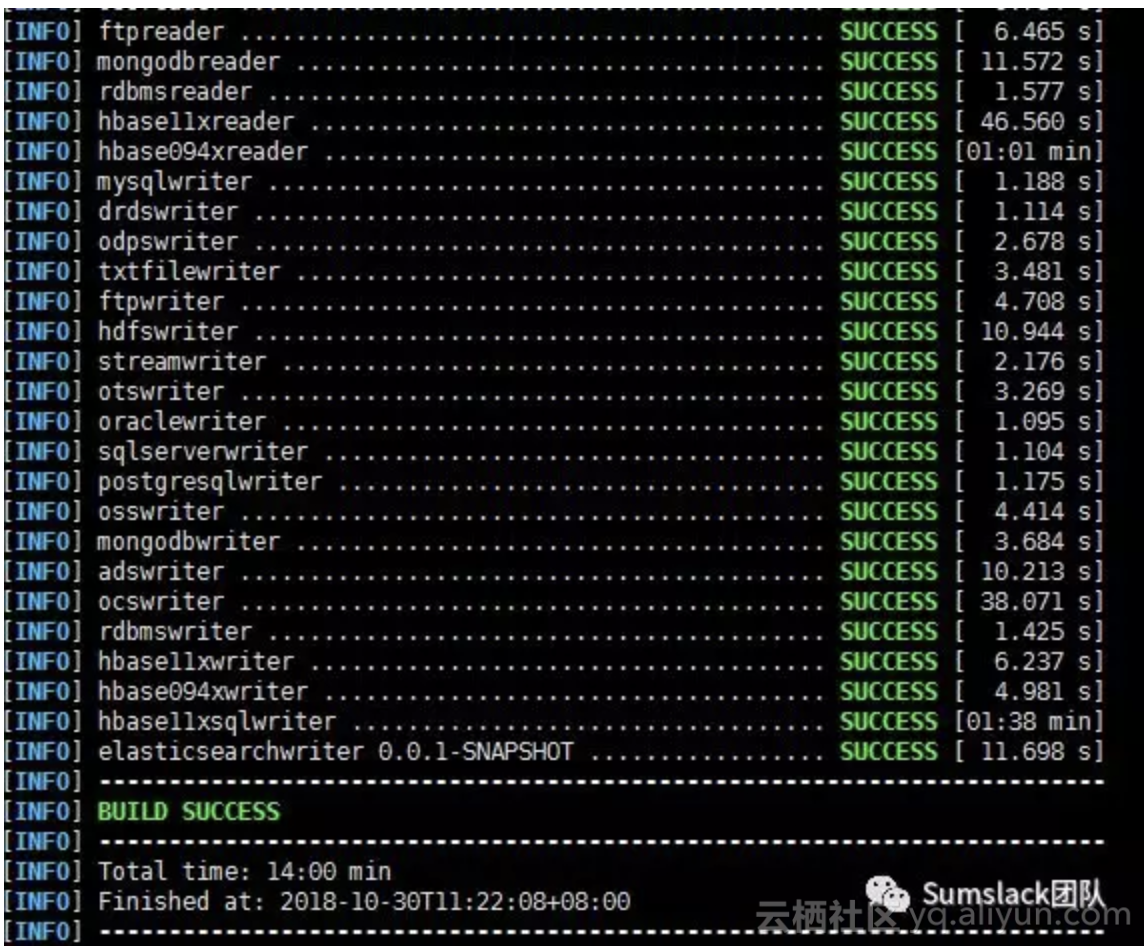
出现以下信息,表示编译成功(编译时间稍长,由于DataX支持的数据源很多,对应的依赖包也比较多,所以可能需要20min左右编译时间,具体视下载速度和机器性能而定):
常见错误:
-
在第3步可能会出现无法编译tablestore-streamclient的错误,请到https://mvnrepository.com/artifact/com.aliyun.openservices/tablestore-streamclient/1.0.0 下载相应的包并放到maven相应路径下;
工具使用
成功编译DataX后,在cd target/datax/datax/目录下就会生成可执行文件,我们就可以来使用DataX同步各种格式的离线数据(具体看参考:https://github.com/alibaba/DataX/blob/master/userGuid.md),如下:
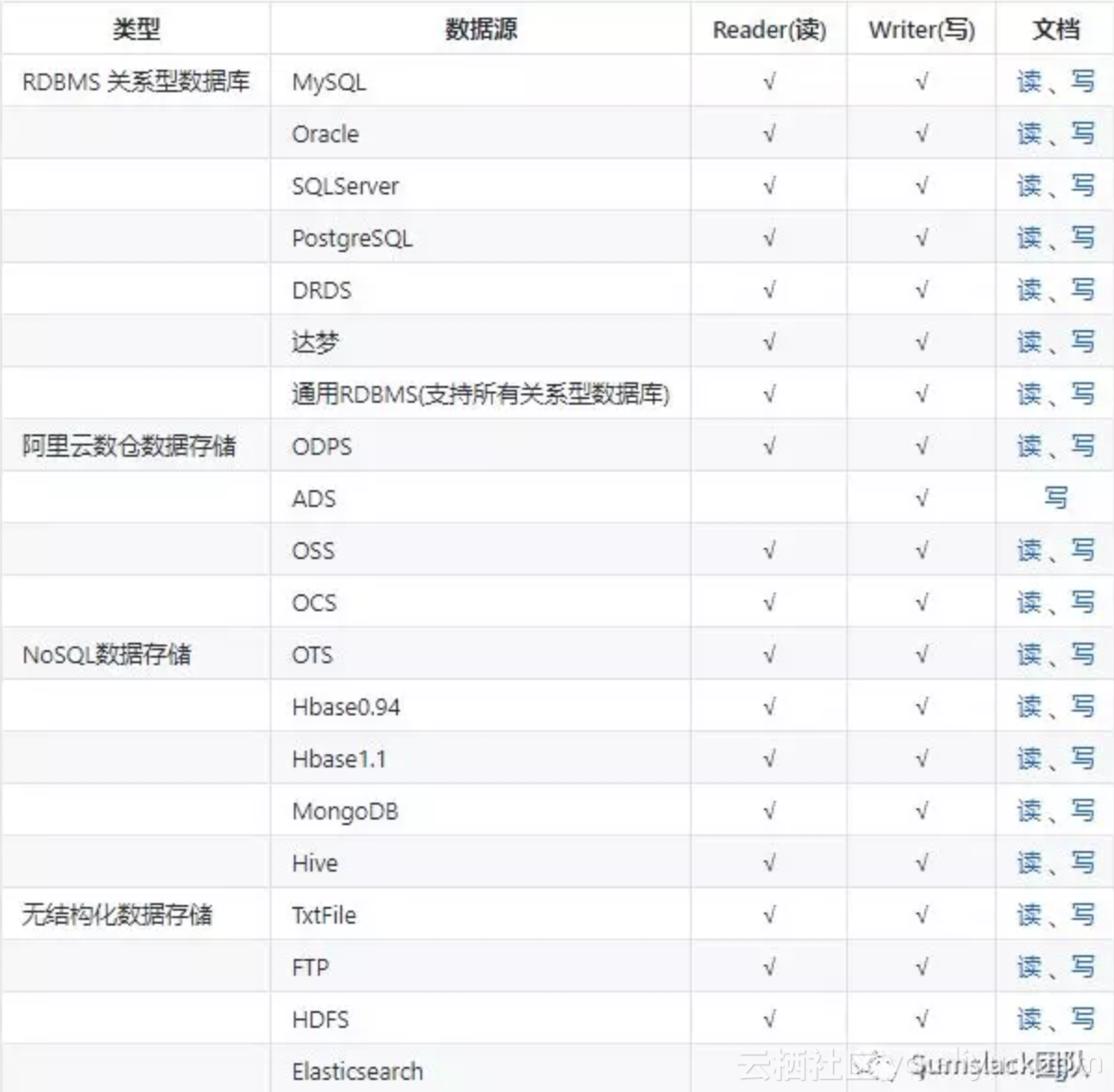
不在这个表格中的数据源格式你可以通过自定义插件编写,具体编码可参考:https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
比如我们实现一个最简单的任务,将JSON格式化数据输出到控制台:
-
切换目录:
cd target/datax/datax/bin,比如在我们的192.168.1.63的服务器,切换到目录:/home/data-transfer/datax/target/datax/datax/bin -
查看配置格式命令:
python datax.py -r streamreader -w streamwriter -
编写配置文件,stream2stream.json文件如下:
1{
2 "job": {
3 "content": [
4 {
5 "reader": {
6 "name": "streamreader",
7 "parameter": {
8 "sliceRecordCount": 10,
9 "column": [
10 {
11 "type": "long",
12 "value": "10"
13 },
14 {
15 "type": "string",
16 "value": "hello,你好,世界-DataX"
17 }
18 ]
19 }
20 },
21 "writer": {
22 "name": "streamwriter",
23 "parameter": {
24 "encoding": "UTF-8",
25 "print": true
26 }
27 }
28 }
29 ],
30 "setting": {
31 "speed": {
32 "channel": 5
33 }
34 }
35 }
36}
-
运行脚本:
python datax.py ./stream2stream.json,执行后控制台输出: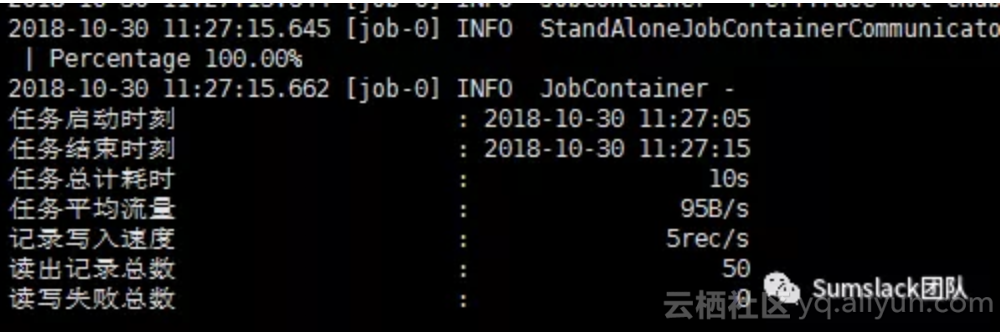
再比如mysql到mysql的离线数据同步,可使用:python datax.py -r mysqlreader -w mysqlwriter 获取配置文件模板;
更多的writer可参看plugins目录下的writer文件夹(官方默认包含的Writer,支持自定义可扩展):
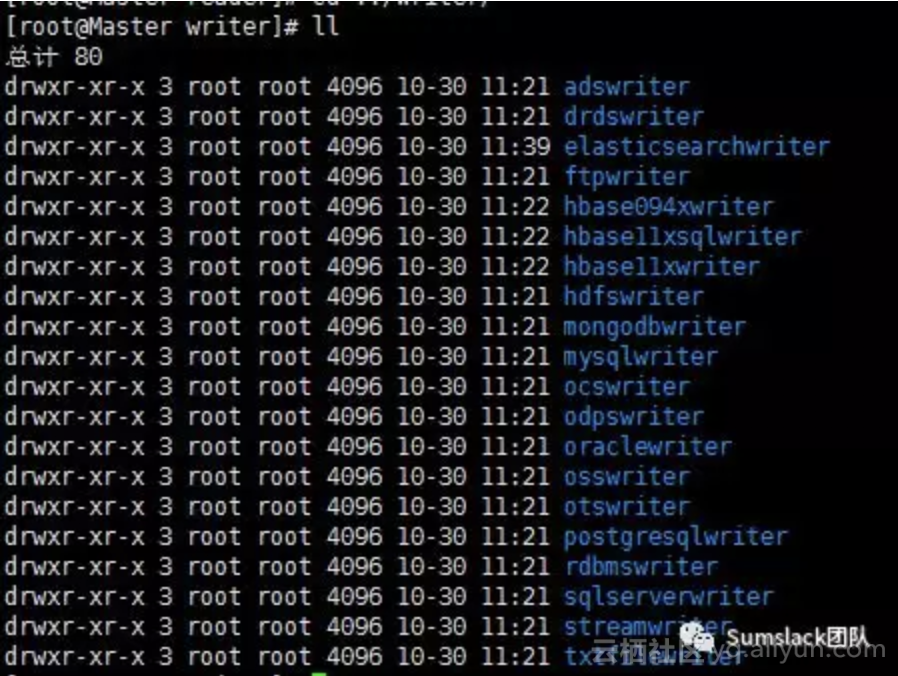
更多的reader可参看plugins目录下的reader文件夹(官方默认包含的Reader,支持自定义可扩展):
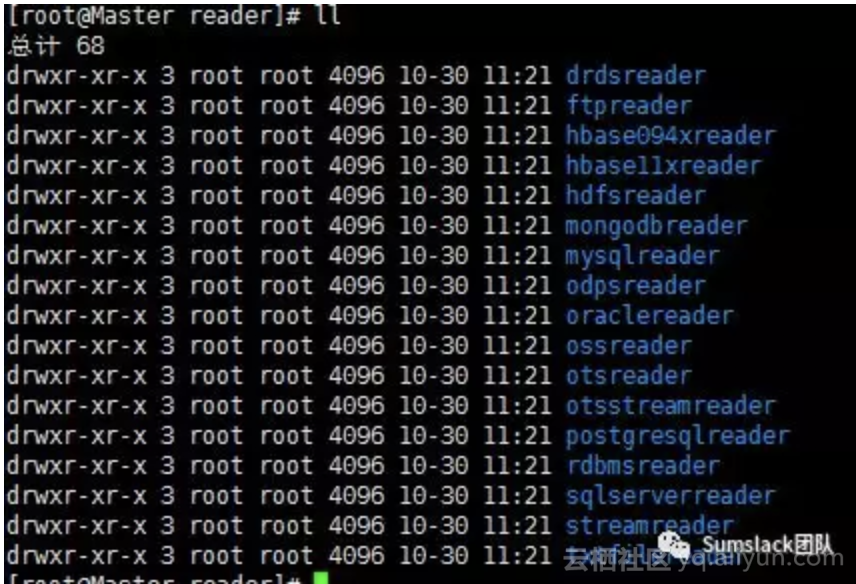
注:如果要使用离线增量同步数据,可指定配置文件中的where过滤;
文章转自:空山雪林 Sumslack团队
更多交流咨询欢迎加入“MaxCompute开发者社区”钉钉群,群号: 11782920,或扫描二维码入群。

