我们在写代码的过程中,免不了会对代码进行一些修修改改。但经常会出现改着改着,就不知道改完后与源文件的差异是怎样的。这里,我们就需要一个文本比对工具来进行文本比对。
有经验的程序员都知道,Windows下有个很好用的文本比对工具——BeyondCompare。但它是收费软件,很多正规的公司是不允许使用破解软件的。而且,它也只能在Windows下使用,没有Linux版本。
本文所介绍的文本比对方法,无需任何软件,只需一个Linux命令。学会这个命令,妈妈就再也不怕你不会文本比对了。
这个Linux命令就是diff命令。
diff是Unix系统的一个很重要的工具程序。它用来比较两个文本文件的差异,是代码版本管理的基石之一。
首先我们来看它的基本命令格式。
diff [OPTION]... FILES很简单吧。不过它的选项相当多,多到你怀疑人生。我们暂且不管那么多,先学一些最常用的,毕竟时间要花在刀刃上。
-b —— 忽略一行中的空字符的区别(例如“Hello World!” 与 “Hello World!!”认为是一样的)
-B —— 忽略空白行
-i —— 忽略大小写的不同
-r —— 如果diff后面接的目录时,会递归比较子目录中的文件不同
我们再来具体看看如何进行文本比较。
diff命令的输出格式有三种:
(1)正常格式(normal diff)
(2)上下文格式(context diff)
(3)合并格式(unified diff)
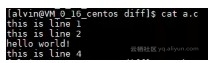
我们通过实例详细介绍这三种输出格式。比如我们现在有个文件a.c,它的内容如下:
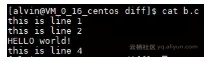
现在我们复制一份,命名为b.c,并将第3行小写的"hello"改为大写“HELLO",如下:
(1)正常格式
正常格式下我们无需加任何选项,直接如下比对就好:

执行完的结果如下:
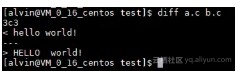
我们一行一行来解释上图的含义。
行一行:3c3
第一个3表示文件a.c中第3行有变化,后面的3表示a.c通过变化成为b.c中的第3行。中间的c就是具体的变化了。c表示改变(change),其它类型还有d删除(delete),a增加(addition)。
第二行:< hello world!
表示a.c文件中去除第3行的内容,其中小于号表示去除。
第三行:------
分隔线
第四行:> HELLO world!
表示b.c文件中增加第3行的内容,其中大于号表示增加。
(2)上下文格式
由于在正常格式下,提示信息比较少,我们无法快速定位所修改的地方,经常需要打开文件才知道修改细节。所以,为了给出更多的信息,引入了上下文格式。它的使用命令如下:
diff -c a.c b.c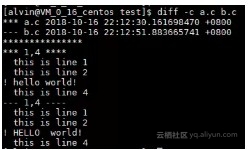
上图的输出结果的具体含义如下:
第1行和第2行表示修改前及修改后的文件及更新时间。下面的*** 1,4 ****表示a.c文件显示的从第1行开始到第4行为止的内容。hello world前的叹号(!)表示该行有改动,如果该行被删除,则为减号(-),如果该行被增加,则为加号(+)。后面几行的含义类似。
(3)合并格式
这种格式是正常格式与上下文格式的综合版,同时这种格式也是git diff所采用的格式。使用这种格式的命令是:
diff -u a.c b.c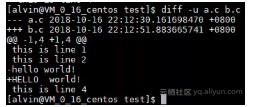
上图的输出结果详细含义如下:
第1行和第2行表示修改前及修改后的文件及更新时间。后面的-hello world!表示原文件a.c里的内容,+HELLO world!表示b.c里的内容。
除了以上三种格式外,还有另外一直更直观的方式——并排格式。这种显示格式的命令格式如下:
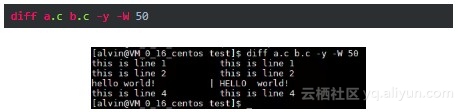
这种格式就是以并列的格式进行显示,也很直观明了。第3行里,有个“|”符号,表示这行有更改。另外,如果前面是“<”,表示后面文件比前面文件少了1行内容;如果是">",表示后面文件比前面文件多了1行内容。
原文发布时间为:2018-11-02
本文作者: 良许
本文来自云栖社区合作伙伴“ ”,了解相关信息可以关注“ ”。