代码下载链接 苏宁百万级商品爬虫
目录
- 思路讲解 类别爬取
- 思路讲解 类别页数爬取
- 商品爬取
3.1 思路讲解 商品爬取1
3.2 思路讲解 商品爬取2
3.3 代码讲解 商品爬取 - 索引讲解
4.1 代码讲解 索引建立
4.2 代码讲解 索引查询
声明
本系列文章+代码案例时对爬虫的内容学习概括,希望更多的人知道如何使用c#进行简单爬虫项目的开发,并不存在恶意工具部分电商网站的观念。分享的的代码中对网页爬取都做了休眠等待(200-500)毫秒的限制,希望大家不要恶意使用。
学习回顾
首先简单概述一下自己的学习计划,在爬虫这个模块的学习过程中。可以了解到很多的知识,例如
- Xpath语法(网页解析),css(网页解析),正则表达式(文本处理或网页解析)
- .net 第三方爬虫类库 html agility pack +第三方爬虫框架(用的相对较少) 学习的时候还是趋向于写一些底层的东西
- 异步多线程,主要用在苏宁百万数据爬取时。多线程爬取,多线程存储。
- Lucene索引和分词 简单使用,并未深入。主要时对爬取的百万数据建立索引库,做一个简单的查询。
运行环境+技术选型
- ide 使用 vs 2017
- 数据库 sqlserver 2008r2 或mysql
- 语言 c#
一、开发预估周期和安排
1、开发周期
因为工作时无聊想到的东西,所以在不耽误工作的情况下,编码周期为1个礼拜。
2、程序模块抽象描述
数据库相关
- 实体
- 数据库访问层
- 业务逻辑层
网页爬取
- 分析器(包含取数据功能)
- 服务层(取分析器数据,调用业务逻辑层方法,将数据入库)
索引
- 分词帮助(盘古分词器)
- 索引帮助
界面描述
采用winform程序的形式,分首页+4个子页面
首页是对主要功能的概述,添加4个按钮,每个按钮触发新的页面,按钮分别为:
- 数据初始化(进行数据初始化功能)
- 商品类别(对商品类别的爬取和更新)
- 商品内容(对商品内容的爬取和更新)
- 建立索引(使用Lucene+分词器建立索引)
- 查询产品
三、开发中可能遇到的问题
- 因为之前都是对单页面的爬取,或者是对某些分页数据爬取,都只是一个小demo。所以在设计程序结构的过程中一定会存在问题。当我已经完成项目后,重新回顾自己的代码也觉得好多地方存在可以修改的地方。
- 对很多技术的生疏,异步多线程在工作中不长使用,没有踩过坑,所以一定会跌的很惨。xpath,正则这些语法的遗忘
- 界面设计可能会很丑,不美观
四、功能设计图
在新建解决方案后,我首先建立一个demo项目,这个项目只是用来做效果图,用来让自己对所做的程序有个大概的布局。
首页设计图:
首页是对功能的详细抽象描述,所以定义三个模块,每个模块再放置自己的内容。
“初始化数据”只是一个按钮,点击弹出提示框,点击确认清理所有产品数据
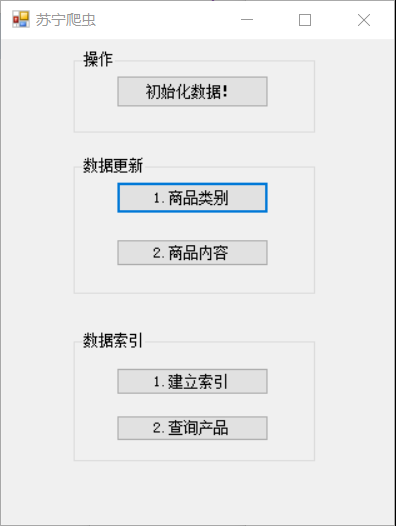
首页.png
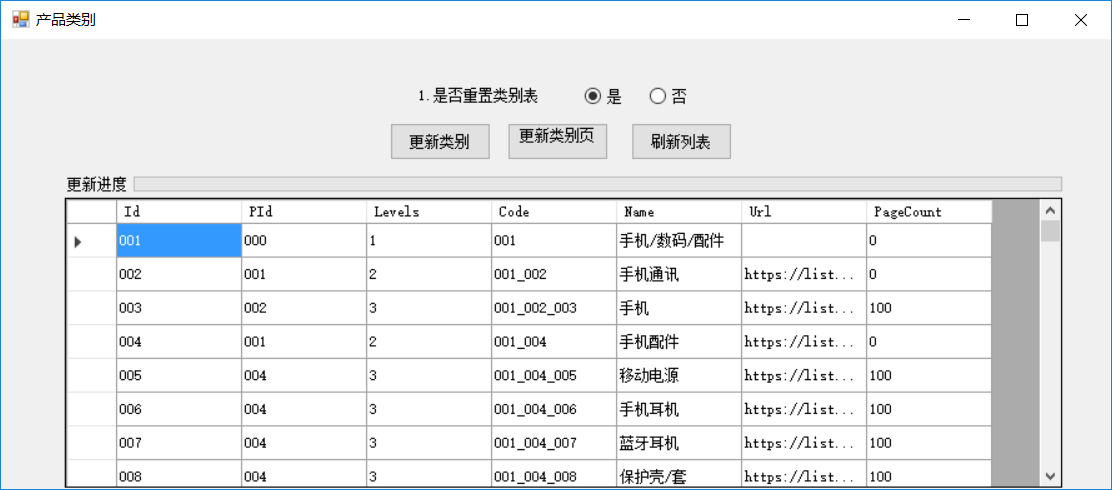
商品类别设计图.png
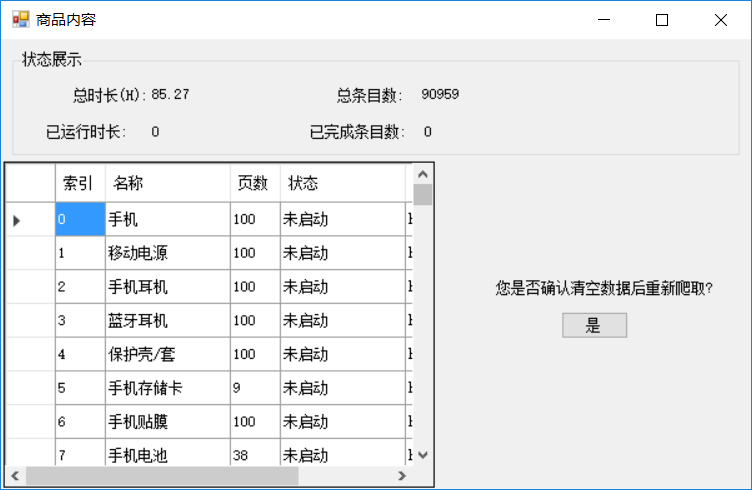
商品内容设计图.png
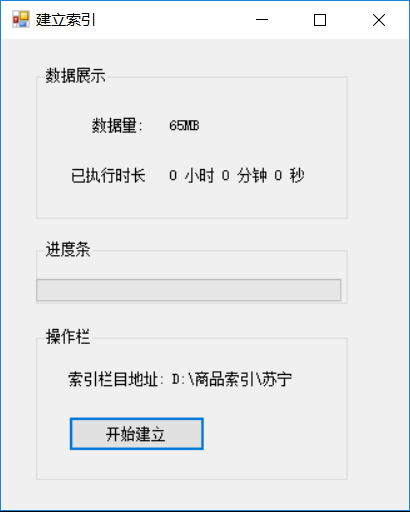
建立索引设计图.png
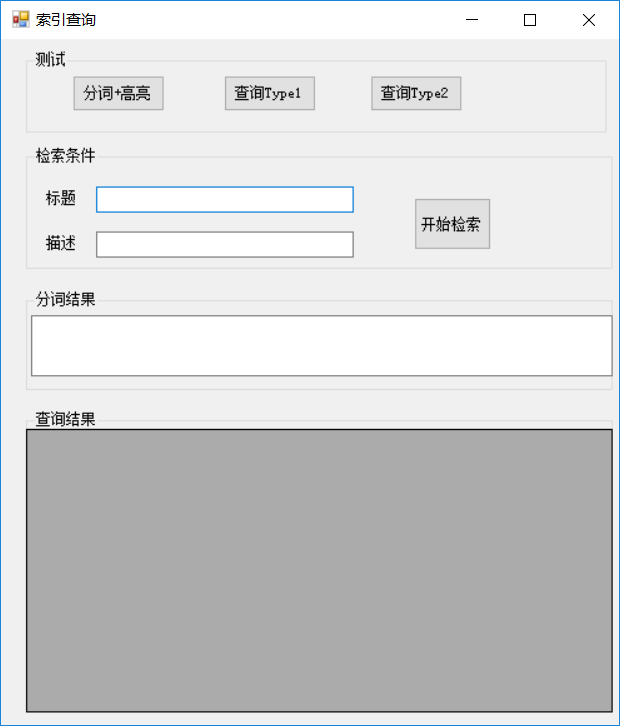
查询产品设计图.png
五、程序准备:
对商品进行爬取,首先要知道有多少类别,不同类别数据性展示是否为不同形式。如果为不同形式,那就要区分爬取,如果相同,那就更加方便。
产品有那么多属性,取哪些字段,百万的数据量应该如何存储,同样的百万数量应该如果查询,这都是在前期应该考虑好的问题。不然等开始编码再修改就很麻烦