Advice for applying machine learning
本周主要学习如何提升算法效率,以及如何判断学习算法在什么时候表现的很糟糕和如何debug我们的学习算法。为了让学习算法表现更好,我们还会学习如何解决处理偏态数据(skewed data)。
以下内容部分参考我爱公开课-Advice for applying machine learning
一、内容概要
- Evaluating a learning algorithm
- Deciding what to try next(决定接下来该试着做什么)
- Evaluating a Hypothesis (评估假设)
- Model Selection and Train/Validation/Test sets (模型选择和训练/验证/测试集划分)
- Bias vs. Variance
- Diagnosing(诊断) Bias vs. Variance
- Regularization and Bias/Variance
- Learning Curves(学习曲线)
- Deciding what to do next Revisited
- Buiding a Spam Classifier
- Priorizing what to work on
- Error Analysis
- Handling Skewed Data(处理偏斜数据)
- Error Metrics for Skewed Classes(不对称分类的错误评估)
- Trading Off Precision and Recall(精度与召回率的权衡)
- Using Large Data Sets
- Data For Machine Learning
二、重点&难点
1. Evaluating a Learning Algorithm
1) Deciding what to try next
一般来说我们训练学习算法遇到瓶颈的时候一般会从下面几种方法中选择一种或几种改进方法,但是随意选择一个可能会浪费我们的时间,所以接下来将会介绍Machine Learning Diagnostic来帮助我们选择更好的改进措施。

2)Evaluating a Hypothesis
这个其实就是将原来的训练数据集认为的再次分为Training set (70%)和Testing Set (30%),先对Training set 进行训练得到权重,然后将权重带入Testing Set ,最后算出误差testError,从而来判断学习算法的准确度。
testError的计算方法依计算类型不同而不同:

3)Model Selection and Train/Validation/Test Sets
上面提到了检查testError来判断假设的准确度,但是并不是误差越小,假设就越准确。
所以进一步优化的方法是将原来的数据划分为
- Training Set(占60%左右)
- Cross validation Set(20%)
- Testing Set(20%)

下面开始进行模型选择,我们事先假设右下图10个多项式(d表示多项式的最高项次幂数)。
-
- 以Training Set为数据计算出10个不同的\(h_θ(x)\)的θ参数
-
- 将上一步中求出的θ参数分别代入验证数据集,并找出误差最小的一项,假设是\(θ^{(4)}\)
-
- 最后将\(θ^{(4)}\)带入测试集,评估最后的整体误差
2. Bias vs. Variance
1) Diagnosing(诊断) Bias vs. Variance
首先要能区分bias和variance的区别,祭上神图:
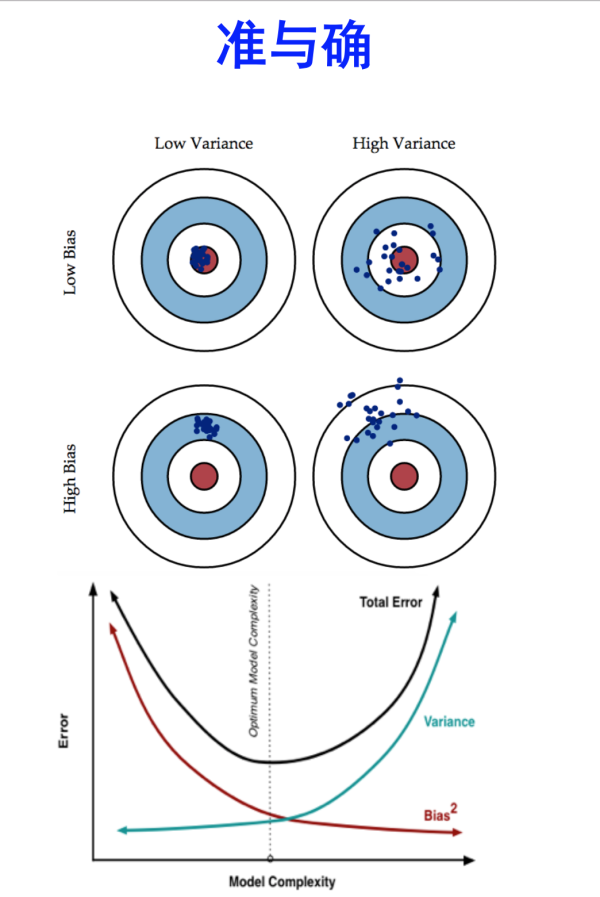
上图很好的诠释了二者的区别,更具体的可参见机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
高偏差(high bias):\(J_{train}(θ)\)和\(J_{CV}(θ)\)都很大,并且二者的值接近
高方差(high variance):\(J_{train}(θ)\)小, \(J_{CV}(θ)\)远大于\(J_{train}(θ)\)
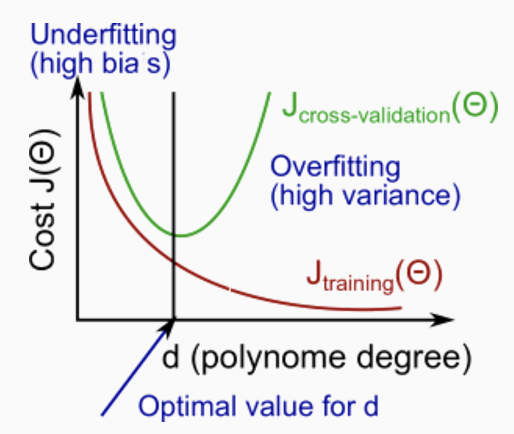
示意图如下:
2) Regularization and Bias/Variance
对于过拟合问题,正则化是个非常有效的解决方案,下面是一个之前提到过的正则化线性回归的例子:
\[h_θ(x) = θ_0 + θ_1x + θ_2x^2 +…… +θ_nx^n\]
\[ J(θ) = \frac{1}{2m}\sum_{i=1}^{m}(h_θ(x^{(i)})-y^{(i)})^2+\frac{λ}{2m}\sum_{j=1}^{m}θ_j^2\]
但是如何选择λ的值呢?this is a question!方法和上面的模式选择类似(见下图)

然后可以画出如下的关于λ的偏差、方差图
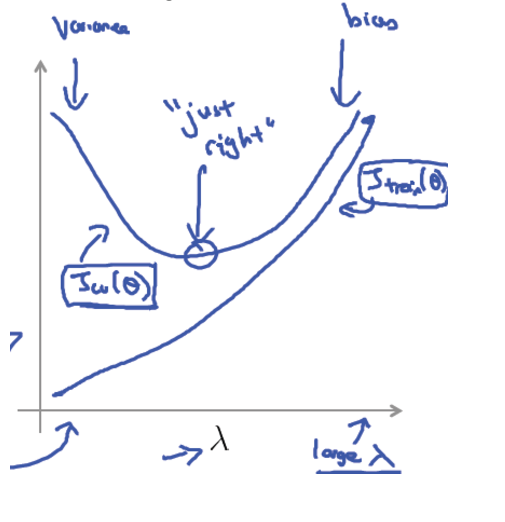
总结一下步骤就是:
- 1.创建一组λ的值,如λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24});
- 2.创建一组不同degrees的\(h_θ(x)\),即x的最高次幂不同
- 3.for λs in λ:
for hs in h:
学习得到一组θ - 4.计算\(J_{CV}(θ)\)
- 5.选取验证集误差最小的一组参数
- 6.将上面求得的最佳θ和λ代入测试集求出\(J_{test}(θ)\)
3) Learning Curves
- 高偏差欠拟合问题的学习曲线:
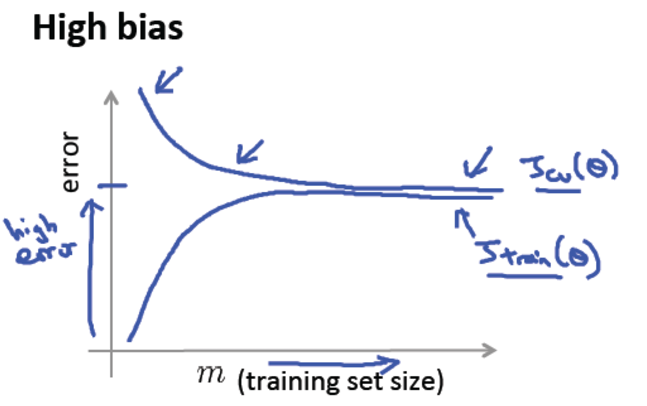
我们发现,如果一个学习算法是高偏差的,那么它的训练误差和验证集误差在一定的训练样本数目之后都很高,而且不会随着样本数目的增大而改变,所以对于高偏差欠拟合的问题,增加训练样本数目不是一个好的解决办法
- 高方差过拟合问题的学习曲线:
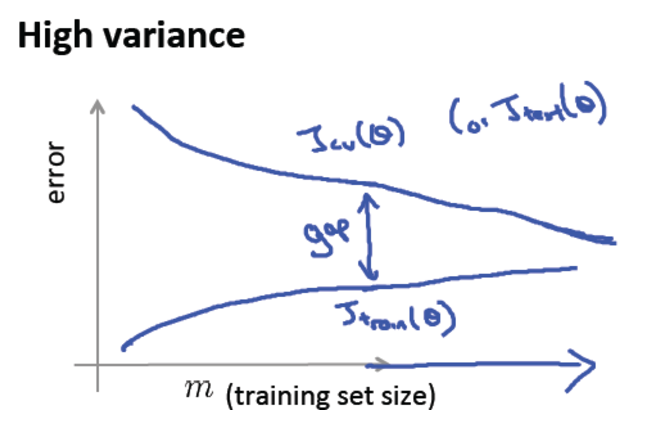
我们发现,如果一个学习算法是高方差的,那么它的训练误差和验证集误差在一定的训练样本数目之后虽然有差异,但是会随着样本数目的增大而减小她们之间的gap,所以对于高方差过拟合的问题,增加训练样本数目是解决方法之一。
4) Deciding what to do next Revisited
好了,说完了这么多与偏差/方差有关的问题,我们再次回到本章的开头的问题,
假设你实现了一个正则化的线性回归算法来预测房价,然而当你用它来测试一批新的房屋数据时,发现预测出来的数据是很不准确的,那么,下一步你该干啥?以下这些选项,分别针对的是高方差或高偏差的问题,你可以尝试用上述小节的一些方法来诊断你的学习算法,不过对于下述选项,需要你考虑一下是针对高偏差还是方差的问题,可以先思考一分钟再看答案:
获取更多的训练样本
尝试使用更少的特征的集合
尝试获得其他特征
尝试添加多项组合特征
尝试减小 λ
尝试增加 λ
答案:
获取更多的训练样本 - 解决高方差
尝试使用更少的特征的集合 - 解决高方差
尝试获得其他特征 - 解决高偏差
尝试添加多项组合特征 - 解决高偏差
尝试减小 λ - 解决高偏差
尝试增加 λ -解决高方差
3. Buiding a Spam Classifier
略,详情参考Coursera公开课笔记: 斯坦福大学机器学习第十一课“机器学习系统设计(Machine learning system design)”
4.Handling Skewed Data
1) Error Metrics for Skewed Classes
什么是不对称性分类(Skewed Classes)?
以癌症预测或者分类为例,我们训练了一个逻辑回归模型\(h_θ(x)\). 如果是癌症,y = 1, 其他则 y = 0。
我们将训练得到的模型运用到测试集上发现这个模型的错误率仅为1%(99%都分正确了),看起来貌似是一个非常好的结果?
但假如仅有0.5%的病人得了癌症。这个时候如果我们不用任何学习算法,对于测试集中的所有人都预测y = 0,即没有癌症,那么这个预测方法的错误率仅为0.5%,比我们废好大力训练的逻辑回归模型的还要好。这就是一个不对称分类的例子,对于这样的例子,仅仅考虑错误率是有风险的。
现在我们就来考虑一种标准的衡量方法:Precision/Recall(精确度和召回率)
首先对正例和负例做如下的定义:
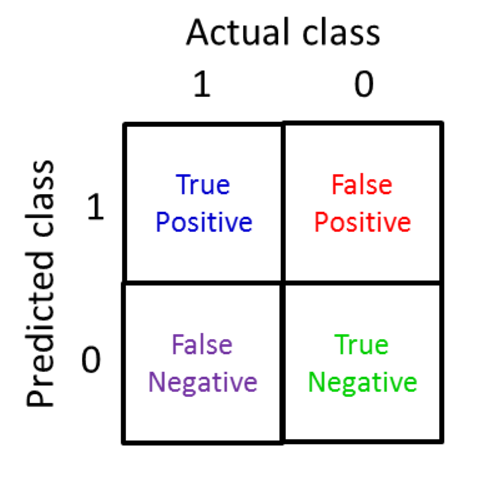
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
True/False: 指的是我们的算法预测分类的正负性
Postive/Negative: 指数据真实分类的正负性
计算公式如下:
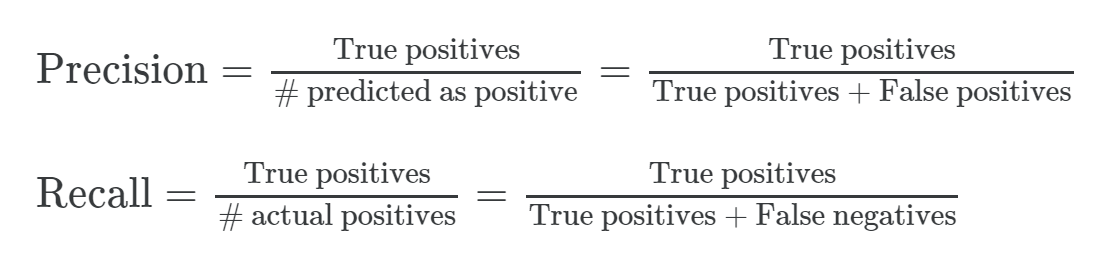
例题:
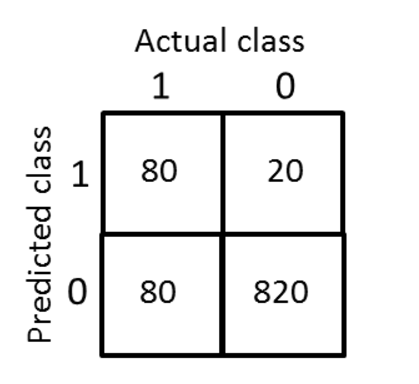
计算可得
\[Precision = \frac{80}{80+20} = 0.8\]
\[Recall = \frac{80}{80+80} = 0.5\]
Precision:预测中实际得癌症的病人数量(真正例)除以我们预测的得癌症的病人数量
Recall-预测中实际得癌症的病人数量(真正例)除以实际得癌症的病人数量
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
作者:祁鑫
链接:https://www.zhihu.com/question/19645541/answer/39732647
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2) Trading Off Precision and Recall(精度与召回率的权衡)
有了Precision和Recall这两个指标可以帮助我们很直观的看到我们的模型的效果如何,但是当两个指标一大一小时我们该如何评判呢?例如
- Precision1 = 0.85, Recall1 = 0.4
- Precision2 = 0.36, Recall2 = 0.90
这个时候再怎么评判呢?
首先我们假设已经训练得到了逻辑回归模型\(h_θ(x)\),,一种通常的判断正负类的方法是设定一个阈值,一般为0.5,即
- \(h_θ(x)≥0.5 ,则y=1\)
- \(h_θ(x)<0.5 ,则y=0\)
很显然我们知道阈值的大小的设定可以调节Precision和Recall,例如 - 当我们将阈值设为0.9,那么会导致高精度,低召回率(Higher precision, lower recall)
- 当我们将阈值设为0.3,那么会导致高召回率,低精确度(Higher recall, lower precision)
这些问题,可以归结到一张Precision Recall曲线,简称PR-Curve:
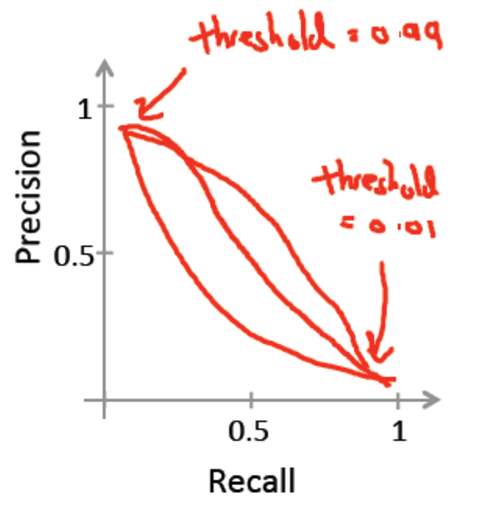
你可能会想到用 (Precision+Recall)/2(即二者的均值)来作为评价的指标,下面我们来举个例子看看这样行不行
| 算法 | Precision | Recall | (Precision+Recall)/2 |
|---|---|---|---|
| 算法1 | 0.5 | 0.4 | 0.45 |
| 算法2 | 0.7 | 0.1 | 0.4 |
| 算法3 | 0.02 | 1.0 | 0.51 |
按照上面的标准,算法3是最好的,但的确如此吗?直觉看上去算法一比较起来应该是最好的,虽然效果并不是特别理想。
现在我们引入标准的F值或者F1-score:
\[F1_{score} = 2\frac{P·R}{P+R}\]
| 算法 | Precision | Recall | \(2\frac{P·R}{P+R}\) |
|---|---|---|---|
| 算法1 | 0.5 | 0.4 | 0.44 |
| 算法2 | 0.7 | 0.1 | 0.175 |
| 算法3 | 0.02 | 1.0 | 0.039 |
现在看来的确是算法1要优秀一些。
F值是对精确度和召回率的一个很好的权衡,两种极端的情况也能很好的平衡:
- P=0 或 R=0时,F1 = 0
- P=1 且 R=1时,F1 = 1
5.Using Large Data Sets
1) Data For Machine Learning
这小节举了个实际的例子,就是有人用好几种不同的算法来预测同一个事件,在数据不是很大的时候准确率会有明显的差别,但是当数据足够大的时候,他们之间的准确率几乎是相等的,所以说大数据是很重要的。
MARSGGBO原创
2017-8-7