hadoop简单介绍和简单实践视频教程 慕课网: https://www.imooc.com/video/7642
预备知识:
liunx基本操作
java开发基础知识
google的大数据技术:MapReduce,BigTables,GFS
革命性变化:
- 成本降低,能用pc机就不用大型机和高端存储。
- 软件容错,硬件故障视为常态,通过软件保证可靠性。
- 简化并行分布式计算,无需控制节点同步和数据交换。
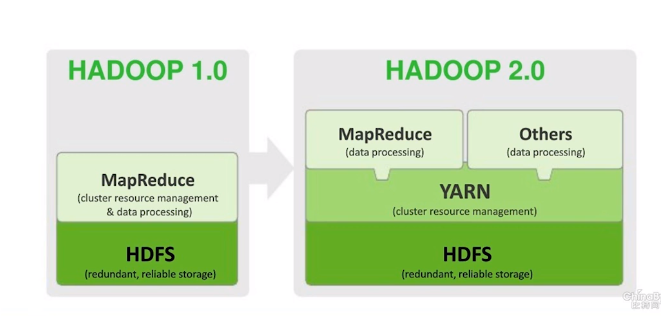
google分布式计算的开源实现 Hadoop ,由apache开发。
解决两个问题,分布式存储和分布式数据处理。
对应HDFS(分布式文件系统)和MapReduce(映射规约)

Hdoop优势:
- 高扩展
- 低成本
-
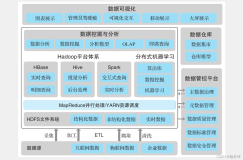
成熟的生态圈
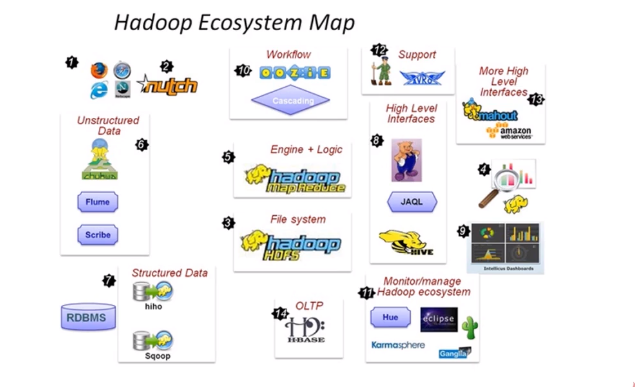
Hadoop 生态系统
Hive 小蜜蜂,牵引
Hbase
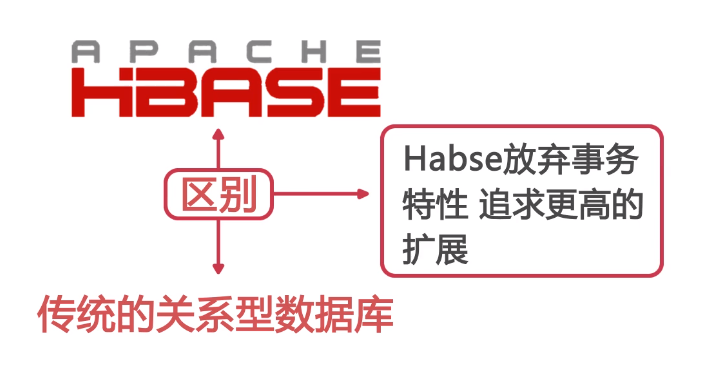
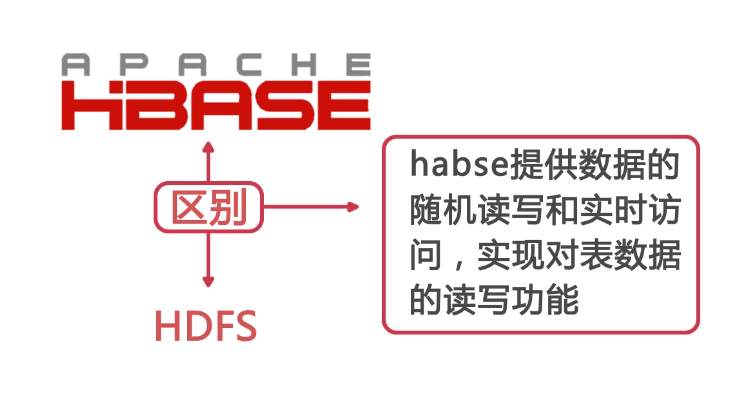
zookeeper
Hadoop安装
- 准备linux
租用云主机,比如阿里云。 - jdk环境
centos下有所不同
1、下载 : yum install java-1.7.0-openjdk
2、配置环境变量 vim /etc/profile
export JAVA_HOME=/jdk路径
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/lib:$JRE_HOME/lib:$PATH
3、让配置生效source /etc/profile
4、输入 java -version 进行测试
vim /etc/profile
配置环境变量
export JAVA_HOME=/jdk路径
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/lib:$JRE_HOME/lib:$PATH
让配置生效
source /etc/profile
- 配置Hadoop
wegt http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz

修改四个配置文件
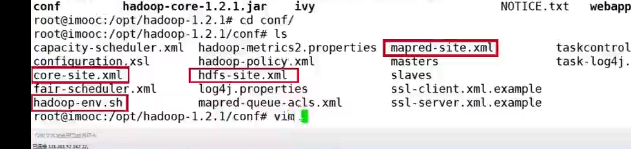
<!-- core-site.xml -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
hdfs-site.xml
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
HDFS



namenode

datenode
文件读取流程:
客户端发送请求给NameNode,NameNode告诉客户端数据在哪些DataNode,然后客户端找DataNode读取数据。

文件写入流程:
客户端先分拆分成块64M大小,然后客户端通知NameNode存储,NameNode找几个空闲的DataNode返回客户端,客户端写数据个某个DataNode,然后DataNode进行复制,复制完毕更新NameNode记录。
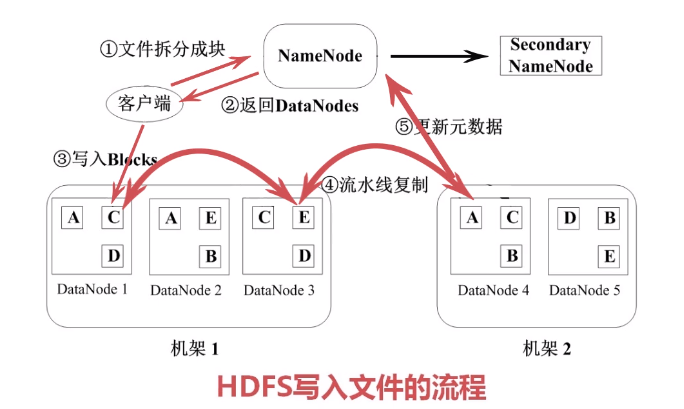
HDFS 特点
- 数据冗余,硬件容错
- 流式的数据访问(一次写入,多次读取,顺序写入)
- 适合存储大文件
HDFS使用
shell命令操作
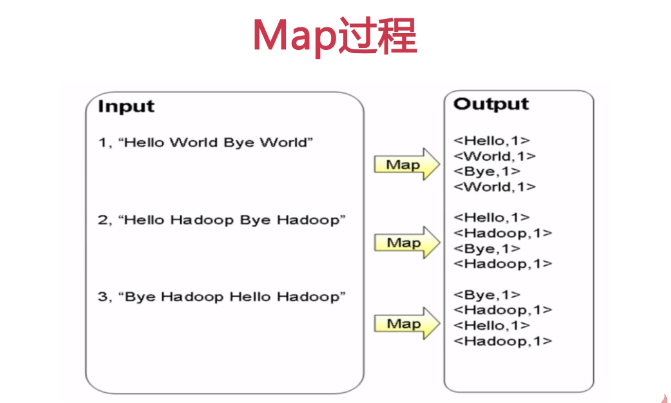
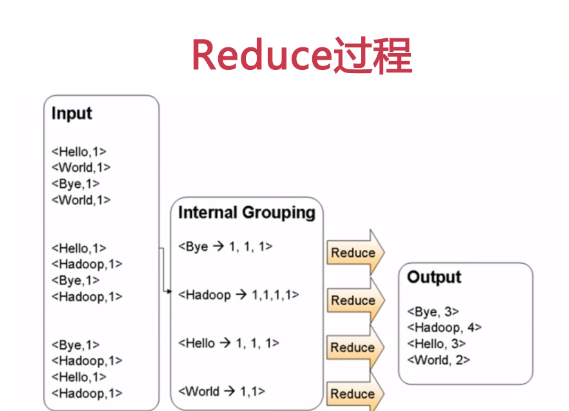
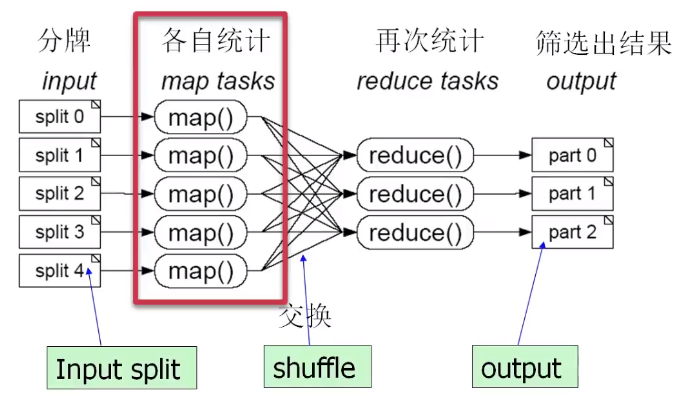
MapReduce 原理
分而治之思想
map 影视
reduce 归约
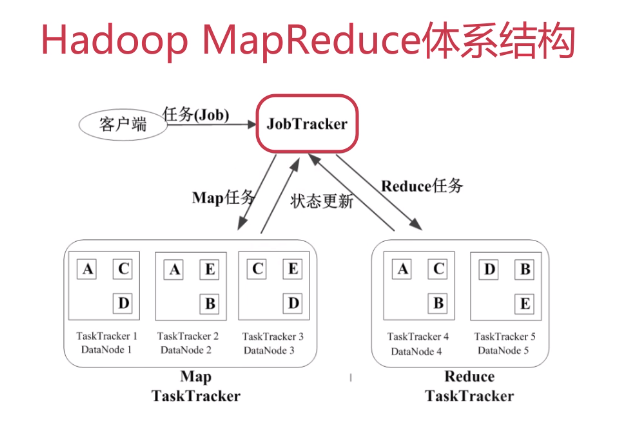
Job&Task
JobTracker
TaskTracker

image.png


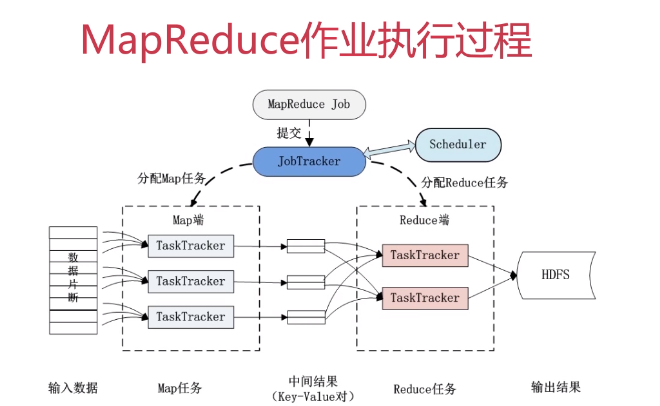
MapReduce容错机制:
- 重复执行
- 推测执行
helloword 入门 单词计数程序