1、前言
学习Python二个多月啦,周末时开始兴趣学习爬虫,虽然有点概念,但是也折腾了大半天,下面就开始简要记录一下吧。
2、需要的准备
- Python:需要基本的python语法基础
- requests:专业用于请求处理,requests库学习文档中文版
- lxml:其实可以用pythonth自带的正则表达式库re,但是为了更加简单入门,用 lxml 中的 etree 进行网页数据定位爬取。
通过pip安装 requests 和 lxml 库,在终端输入:
pip install requests
pip install lxml
注:如果是安装到Python3就用pip3 install
下载过程成功的输出:
Collecting lxml
Cache entry deserialization failed, entry ignored
Downloading https://files.pythonhosted.org/packages/00/fd/5e65f293e366a63198dade275b886e5d24752367c2e67e3993023b0d58ef/lxml-4.2.3-cp36-cp36m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (8.7MB)
100% |████████████████████████████████| 8.7MB 821kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.3
- 注:
如果安装过程遇到任何问题,请谷歌吧,如果网上找不到答案,也不要问我!找不到答案我直播吃翔!!!
3、实践过程
为了这过程有点兴趣,我找了一个美图的网站,爬虫了一波图片~
实践爬虫的网站链接:https://www点aitaotu点com(注意,这不是打广告!)
- 下载页面html内容:
page = 'https://www点aitaotu点com/guonei/36350.html'
data = requests.get(page).text
dom = etree.HTML(data)
- 解析(定位)元素:
title_path = '//*[@id="photos"]/h1/text()'
totalpage_path = '//*[@id="picnum"]/span[2]/text()'
image_path = '//*[@id="big-pic"]/p/a/img'
这里的xpath怎么获取,就是网页里面,打开开发者检查元素工具,在safari和chrome都有这个功能:

20180710-html-show-element.png
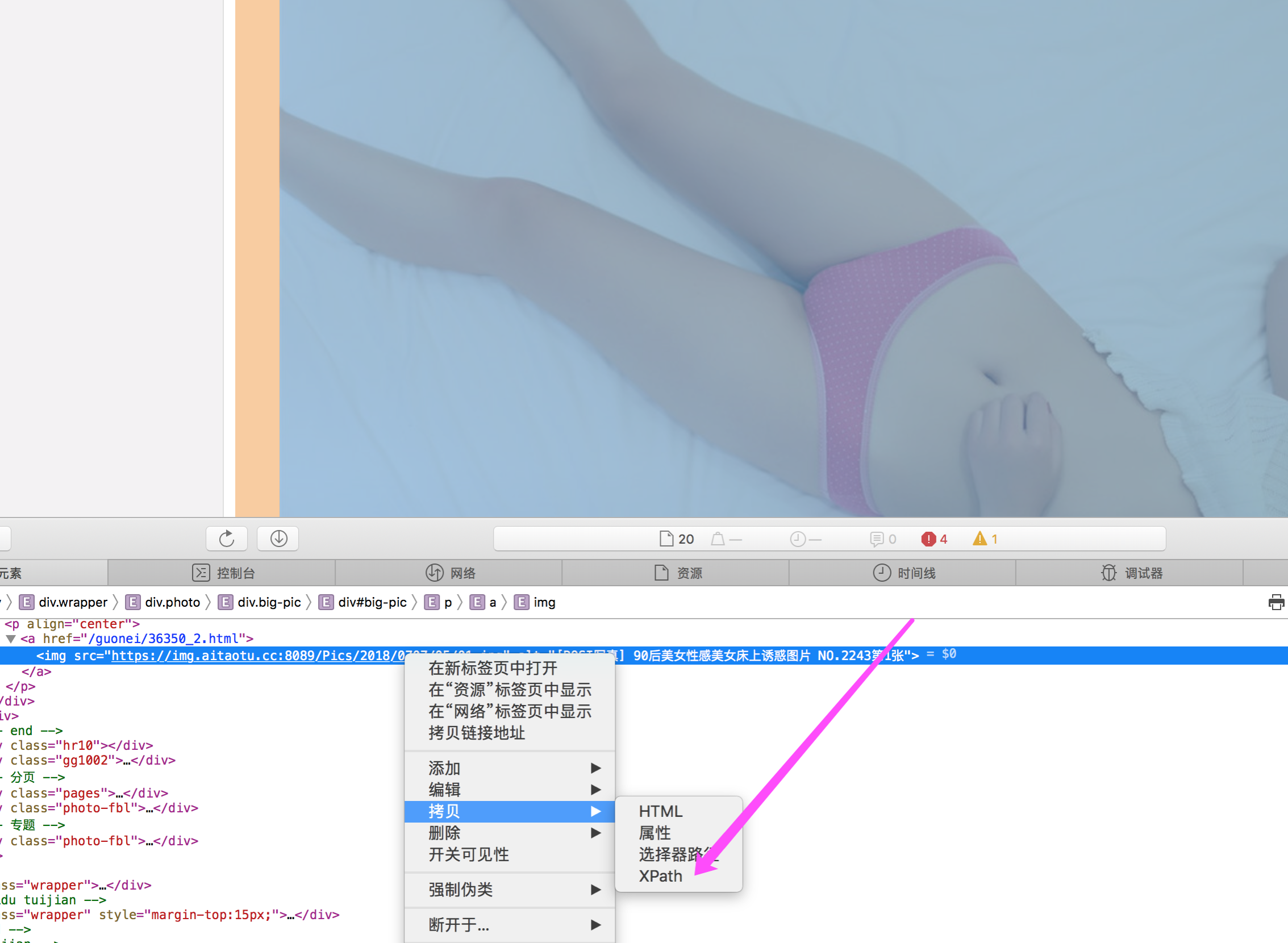
20180710-html-copy-xpath.png
- 获取元素内容:
title = dom.xpath(title_path)[0]
total = dom.xpath(totalpage_path)[0]
image_url = dom.xpath(image_path)[0]
img_src = image_url.xpath('./@src')[0]
img_alt = image_url.xpath('./@alt')[0]
这里解析就不解析了,其实通过PyCharm IDE可能实时查看每个对象的属性,可以更清晰的了解解析的元素结构,帮助理解,这里就暂时不说IDE的方法啦,大家有兴趣可以试试,也是很简单的~
最后拿到图片链接,就是下载图片然后保存输出到电脑啊!(文章尾附完整代码!)
总结
爬虫入门就这样结束啦!学习了python后,发现语法很简单,代码很轻松就完成!不到100行!!!
python通过各种库,解决了编程语言自身的庞大,完成了自己是胶水语言的特点!
通过这次实践,其实,有很多细节东西,只有自己做了才知道,比较说保存图片的路径,找到当前目录,怎么分目录保存,目录文件操作,这些都是自己之前实践了一个django工具学习过来的。所以,现在经历多了,才知道,什么时候学习都不晚,有些东西,真的是不知道什么时候你会用上,真的,自己早知道这个道理几年,就不像年轻时那么想,这东西怎么可能会用上,不学!!!果然是年轻坑爹!!!学会老,学到老吧!
代码
#!/usr/local/bin/python3
#coding=utf-8
import os
import requests
from lxml import etree
def downloadImages(url):
data = requests.get(page).text
dom = etree.HTML(data)
title_path = '//*[@id="photos"]/h1/text()'
totalpage_path = '//*[@id="picnum"]/span[2]/text()'
image_path = '//*[@id="big-pic"]/p/a/img'
title = dom.xpath(title_path)[0]
total = dom.xpath(totalpage_path)[0]
image_url = dom.xpath(image_path)[0]
img_src = image_url.xpath('./@src')[0]
img_alt = image_url.xpath('./@alt')[0]
print(title, total, img_src, img_alt)
cwd = os.getcwd()
save_path = os.path.join(cwd, 'images/' + title)
if not os.path.exists(save_path):
os.makedirs(save_path)
print(u'保存图片的路径:', save_path)
img_path = os.path.dirname(img_src)
img_name = os.path.basename(img_src)
img_format = img_name.split('.')[1]
print(img_path, img_name)
for i in range(1, int(total) + 1):
new_img_url = '%s/%02d.%s' % (img_path, i, img_format)
save_img_path = '%s/%02d.%s' % (save_path, i, img_format)
# 下载图片
image = requests.get(new_img_url)
# 命名并保存图片
with open(save_img_path, 'wb') as f:
f.write(image.content)
if __name__ == '__main__':
url = 'https://www.aitaotu.com/'
# download list
list = ['guonei/36350.html', 'guonei/36352.html', 'guonei/36351.html', 'guonei/36357.html', 'guonei/36250.html',
'guonei/36341.html', 'guonei/36334.html', 'guonei/36306.html', 'guonei/35969.html', 'guonei/35219.html',
'guonei/36290.html', 'guonei/36277.html', 'guonei/36263.html', 'gangtai/36303.html', 'gangtai/36226.html',
'guonei/35260.html', 'guonei/35247.html', 'guonei/36257.html', 'guonei/36221.html', 'guonei/21647.html',
'guonei/21499.html', 'guonei/36319.html', 'guonei/34903.html', 'guonei/14148.html', 'guonei/33780.html',
'guonei/14338.html', 'guonei/14550.html', 'guonei/14818.html', 'guonei/16820.html', 'guonei/18388.html',
'guonei/13447.html', 'guonei/25912.html', 'guonei/13991.html', 'guonei/8246.html', 'guonei/36171.html'
]
print(u'准备下载:%d套图', len(list))
for type in list:
page = url + type
downloadImages(page)
print(u'下载完成啦!')
代码就没有太多注释,因为很简单,就说一下运行方式吧,在终端:
python2:
python YellowImage.py
python3:
python3 YellowImage.py
最后的成果:
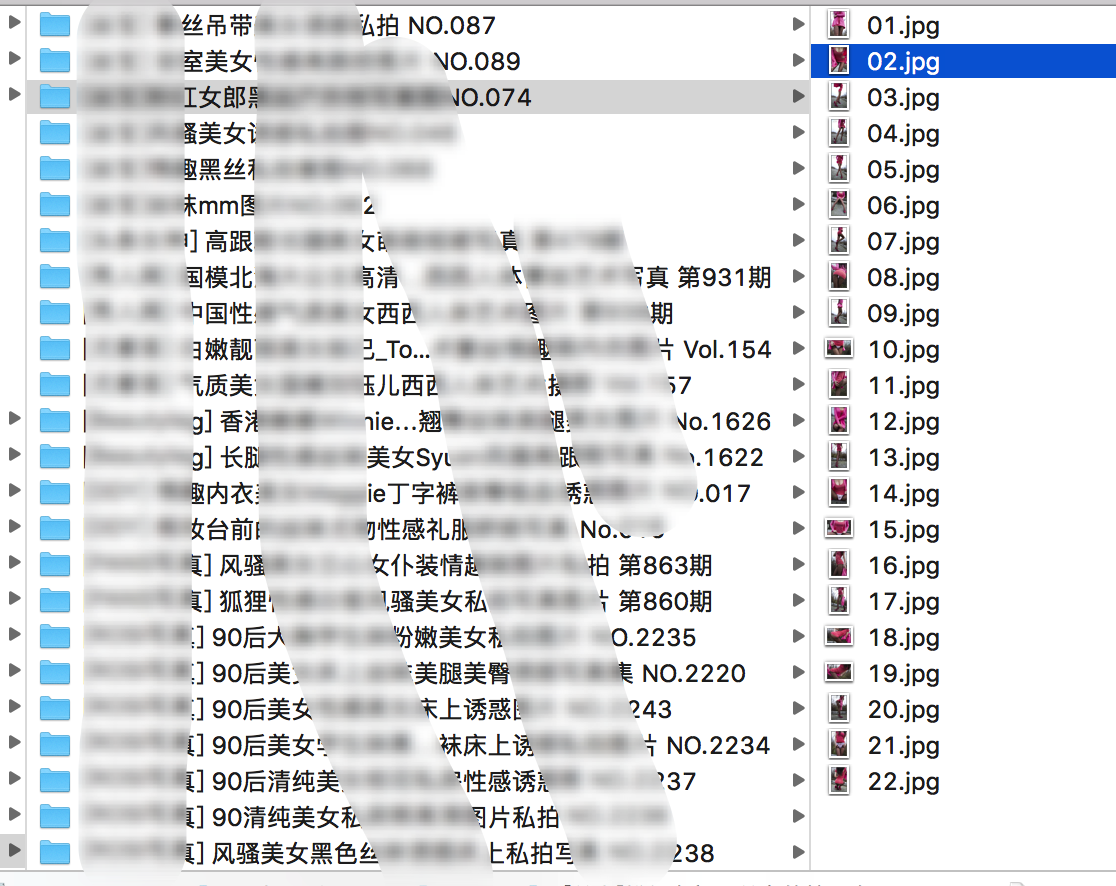
20180712-results.png
参考
- Python教程 - 廖雪峰的官方网站
- Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
- Beautiful Soup 4.2.0 文档
- 正则表达式30分钟入门教程
- 在线正则表达式测试
- lxml - Processing XML and HTML with Python
- Python lxml教程 | 卡瓦邦噶!
- 非结构化数据之lxml库 · 网络爬虫教程
- 如有疑问,欢迎在评论区一起讨论!
- 如有不正确的地方,欢迎指导!
注:本文首发于 iHTCboy's blog,如若转载,请注来源
