- 本文是原理介绍
- 这里是如何使用传送门
- 这里是源码地址
V1.0.0功能列表 |
是否支持 |
|---|---|
| 接口自定义 | 支持 |
| 缓存策略 | 支持 |
| 外部cookie注入 | 支持 |
| 推送周期设定 | 支持 |
| 强制推送 | 支持 |
| 自定义埋点事件 | 支持 |
| 独立运行 | 支持 |
| 多线程写入 | 支持 |
| 后台线程服务 | 支持 |
注:代码已经经过线上项目验证, 横向Google统计对比,统计数据无丢失,性能稳定.
项目背景
统计数据 是BI做大数据,智能推荐,千人千面,机器学习的 数据源和依据.
在这个app都是千人千面,智能推荐,ab流量测试的时代, 一个可以根据BI部门的需求, 可以自有定制的 数据统计上报, 就显得非常重要.
目前, 市面上 做统计的第三方平台有很多, 比如最出名的Google的GTM统计,友盟统计等等.
但是 这些统计, 第一点,就是上传的频率,比较固定, 难以满足要求不同的频次需求. 第二点,需要统计到的字段和规则都是死板的,无法定制.
目前GitHub上, 没有一个 自定义的 统计SDK 思路和源码.
我想,在这里分享下,我的思路和代码.
这里有几个要点
- 统计分类:统计分为屏幕值,事件两种,后续可能扩展.
- 统计规则: 支持简单Google统计方式,支持自定义字段.
- 推送方式:每两分钟上传到服务器,
- 作为sdk,可以单独集成,独立运行.
这是一个什么样的统计SDK?
做统计SDK的方式有这两种
1.用AOP的处理方式, 在方法内,插入统计代码. 这种方式虽然在.java文件里 没有代码侵入,但是可定制行不高,只适合简单的 统计需求.
2.用普通的方法样式,使用GTM.event(xxx)方式,代码侵入极高, 但是可以实现高度自定义.
现阶段, 我会采用第二种方式,为了数据的精确要求,采用侵入式.
后续, 我会继续思考,更好的实现方式. 也请大家一起分享自己的思路.
因为统计规则业务定制性很强,无法对传送数据进行统一的抽象管理, 该项目就不单独发布到jcenter,
如果需要,可以参考源码思路, 自己修改源码,修改数据载体,实现需求即可.
JJEvent设计初衷为:一个统计SDK, 可以单独发布到仓库,单独被项目依赖而不产生冲突,拥有自己的数据存储,网络请求.
1.上传规则
这些都是可以自定义的,修改源码即可
固定周期进行上传: 比如每2分钟,进行一次数据上传.数据为 触发推送的时间节点 之前的数据.用于大部分统计.
固定条数进行上传: 比如每100条,进行一次数据上传.数据为 触发 触发100条推送开始 之前的数据.用于大部分统计.
- 实时上传:每次点击就进行push操作.数据为 触发推送的时间节点 之前的数据.用于特定统计.
2.统计分类
这里, 可以根据BI的业务需求而定, 大家可以在此基础上修改.
1.PV(PageView) 屏幕事件
- sn(screen) 屏幕名称 遵循旧策略(Android/好价/好价详情页/title).
- ltp 屏幕加载方式 下拉刷新=1、翻页=2、标签切换=3、局部弹屏4、筛选刷新=5.
- ecp 自定义事件 ,json map存储.
2.Event 点击事件
- ec(event category) 事件类别
- ea(event action) 事件操作
- el(event lable) 事件标签
- ecp 自定义事件 ,json map存储.
3.expose曝光 事件
- url 曝光url
- ecp 自定义事件 ,json map存储.
4. 其他事件
支持自定义扩展
SDK抽象过程
面向对象语言的特点: 就是要面向对象编程,面向接口编程.当你在抽象的过程中,只关注某个对象是什么,然后他拥有什么属性,什么功能即可.不需要考虑其中的实现.这也就是Java乃至面向对象语言,为啥这么多类的原因,这其中有单一职责原则,接口分隔原则.
模块之间的依赖,应该最大程度的依赖抽象.
要想完整的把整个过程抽象清楚,需要对整个流程有个最大的认知.
判断逻辑,技术选型
思考:肯定会想到这些东西,只不过想到的过程可能不同,而且每个设计者,想法都不会一样,实现过程也不一样.
首先需要一个配置类Constant ,对常量,开关进行管理.
一个sdk有事件统计,那么必须要有一个Event类来进行屏幕值,事件两种统计动作.
统计事件发生后, 需要一个持久化过程DbHelper,即需要一个数据库支持存取.
如何推送呢? 需要建立一个后台服务JJService,对数据进行推送.
用什么推送呢?肯定需要网络啊, 需要一个网络模块NetHelper从数据库中拿数据,进行推送.
推送的是什么呢? 需要建一个任务Task,让task承载推送的过程.
如何将模块进行连接,统一管理?
SDK整体架构
1.统计客户端SDK架构图
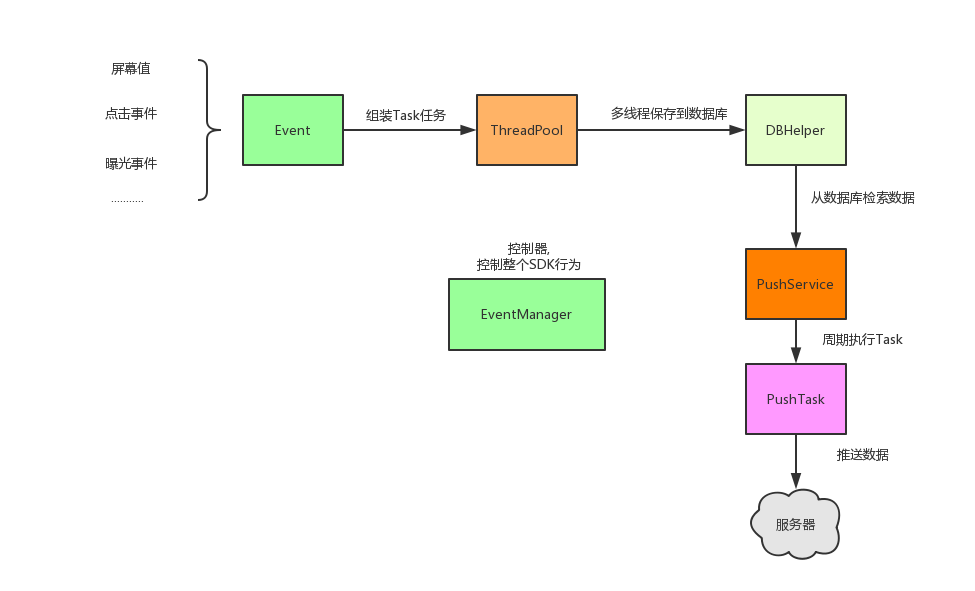
2.服务端数据收集采用的是
- openresty实现客户端日志上报接口
- flume实现日志采集发送kafka
- 最终落地到硬盘
3. 大数据端
经过抓取数据库数据快照 ,进行数据清洗,然后提供给机器学习,或者千人千面.
模块建设
这里如果有兴趣,请配合源代码.
1.JJEventManager管理模块
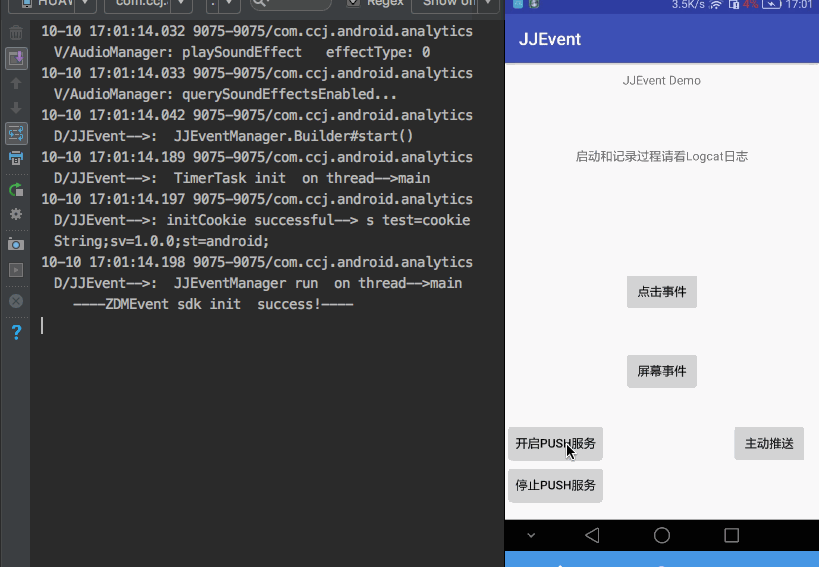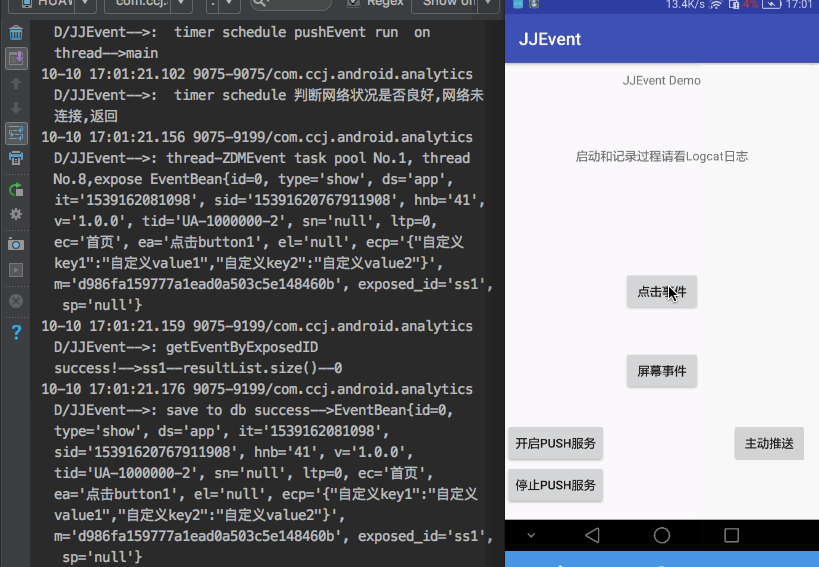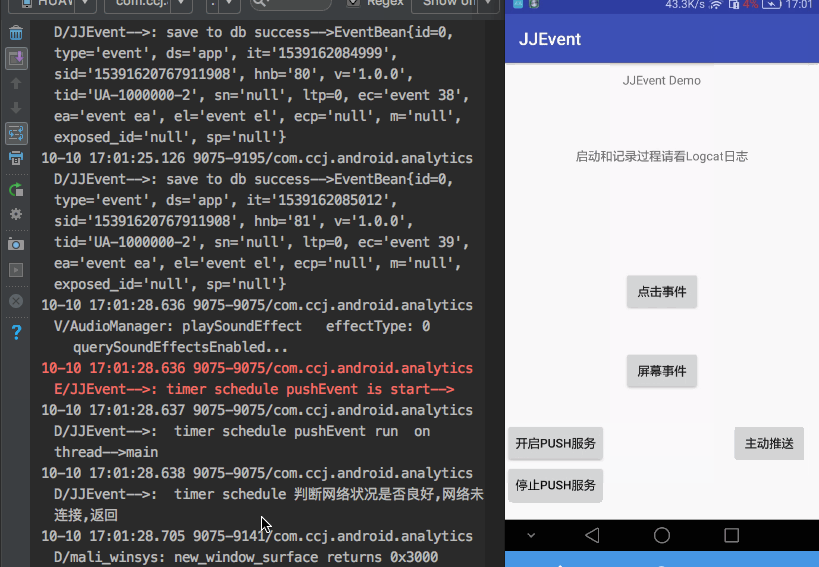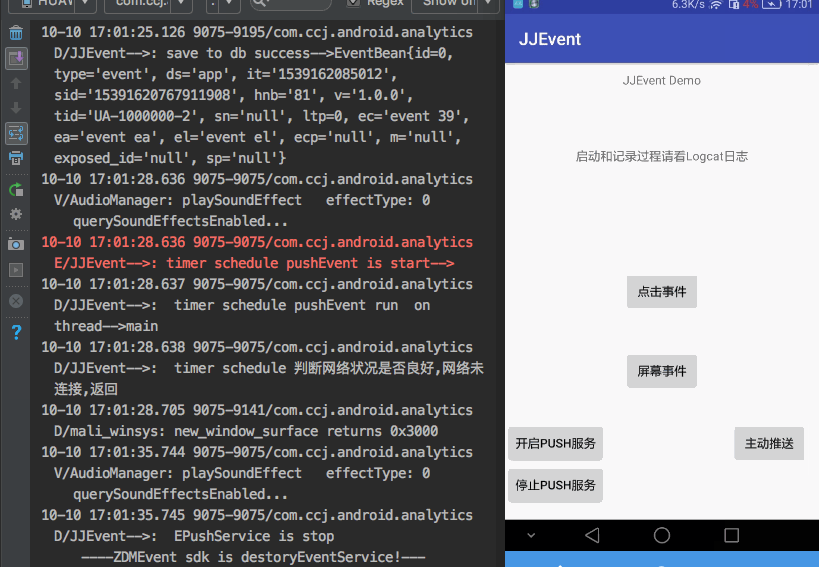
首先,sdk的生命周期是整个application的周期,所以我让sdk 持有application 上下文,不会存在内存泄漏.所以,我考虑将全局上下文放在这里管理.当其他位置需要的时候到JJEventManager .getContext() 取值.
作为管理类,需要拥有控制sdk完整生命周期的功能.即init(),cancelPush(),destroy()等方法.让各个模块的生命周期在这里管理.
然后考虑到,让用户可以动态配置各种参数,比如周期,是否是debug模式,主动推送周期等等.所以在内部使用buider模式,进行动态构建.
JJEventManager.Builder builder =new JJEventManager.Builder(this);
builder.setHostCookie("s test=cookie String;")//cookie
.setDebug(false)//是否是debug
.setSidPeriodMinutes(15)//sid改变周期
.setPushLimitMinutes(0.10)//多少分钟 push一次
.setPushLimitNum(100)//多少条 就主动进行push
.start();//开始
}
2.Event动作模块
动作类,统计只有两个动作,即两个方法screen (),event(),以及一些重载方法.
因为是公开类,所以要做到简洁,注释要到位..(导入项目中的jar包,没有Java document..因为doc生成在本地..云端没有)
由于是数据入口类,所有坚决不能存在崩溃的情况发生.
所以在相应的地方加上了try catch处理.
/**
* 统计入口
* Created by chenchangjun on 18/2/8.
*/
public final class JJEvent {
/**
* pageview 屏幕值
* @param sn screen 屏幕值,例`Android/主页/推荐`
* @param ltp 屏幕加载方式
*/
public static void screen(String sn, LTPType ltp) {
screen(sn, ltp, null);
}
/**
* pageview 屏幕值
* @param sn screen 屏幕值,例`Android/主页/推荐`
* @param ltp 屏幕加载方式
* @param ecp event custom Parameters 自定义参数Map<key,value>
*/
public static void screen(String sn, LTPType ltp, Map ecp) {
try {
ScreenTask screenTask =new ScreenTask(sn,ltp,ecp);
JJPoolExecutor.getInstance().execute(new FutureTask<Object>(screenTask,null));
} catch (Exception e) {
e.printStackTrace();
ELogger.logWrite(EConstant.TAG, "expose " + e.getMessage());
}
}
将处理细节交给其他类处理,这里我用了一个 Event包装类EventDecorator来做EventBean中统一的数据缓存,参数值处理.遵循单一职责原则.
注意:
在修改数据体EventBean来满足业务需求时, 请在EventDecorator的相关方法中进行修改.
3.DBHelper模块
刚开始想用模板方法和继承来做,将CRUD的实现放在宿主中,
但是, 由于用户不太清楚sdk内部实现逻辑,用户维护sdk的成本太高.所以,我就重新裁剪了开源的XUtils中的dbUtils,然后修改类名,作为db服务.
4.ThreadPool模块
为了减少UI线程的压力, 有必要将数据操作放到子线程中. 考虑到数据量时大时小, 所以需要自定义一个线程池,来管理线程和县城任务.
这里, 最主要的就是 控制好线程的对共享变量的访问锁.保证线程的原子性和可见性.
将所有Event任务,作为一个Runable,放到阻塞队列中,让线程池队列执行.注意设置runable超时时间,异常处理.尽量保证数据录入成功.
要注意的是, Event任务 执行有快有慢, 所以,最终保存到数据库的时候, 并不是按照队列的顺序.
4.1 如何保证线程安全?
对于变量
比如int eventNum=1;
线程在执行过程中, 会将主内存区的变量,拷贝到线程内存中, 当修改完a后,再将a的值返回到主内存中.这个时候,如果两个线程同时修改该变量,第三个线程在访问的时候,很有可能a的值还没有改变.这个时候就会让a的改变不可见.所以,可以用线程安全变量AtomicInteger,或者原子性变量volatile,让他们咋发生改变的时候,立刻通知主内存中的变量.
对于方法
为了保证线程间访问方法互斥, 用synchronized对线程访问方法,进行同步.保证线程顺序执行.即要将所有共通操作,放到一个加载器方法中,用synchronized同步.
另外,避免线程滥用,性能浪费, 要仔细考量voliate,synchronized等字段的频次.
详情处理可见EventDecorator.java中的 变量处理.
4.2 sqlite数据库是否 线程安全?
目前, 统计sdk状态是
多个线程同时执行数据库操作,
Timer拥有自己的单线程 执行数据库读取.
要保证数据库使用的安全,一般可以采用如下几种模式
SQLite 采用单线程模型,用专门的线程/队列(同时只能有一个任务执行访问) 进行访问
SQLite 采用多线程模型,每个线程都使用各自的数据库连接 (即 sqlite3 *)
SQLite 采用串行模型,所有线程都共用同一个数据库连接。
在本SDK中,采用串行模式,在初始化过程中,SQLiteDatabase静态单例, 来保证线程安全.
项目经过测试部门,和线上检验,线程间访问正确,数据统计正确.
5.NetHelper模块
首先,net请求,我裁剪的是volley.
NetHelper应该采用的是静态或者单例,采用单例的原因是,他的生命周期和application同级.功能应该是 接受数据,然后推送数据,最后暴露告知结果.封装里面的请求转发逻辑.
NetHelper网络模块,应该有一个请求队列(避免请求数据错乱),,还应该提供针对不同EventType进行不同处理请求的方法,然后还需要一个统一的网络请求监听.
为了保证 推送不出现数据错乱,应该在上一次网络访问没有结束前,不能继续访问的锁,用锁isLoading来控制.
将 请求分发逻辑,是否正在请求,以及监听完全封装在里面.对外只暴露OnNetResponseListener.
按照上述逻辑,调用方式是这样的.简单实用.
ENetHelper.create(JJEventManager.getContext(), new OnNetResponseListener() {
@Override
public void onPushSuccess() {
//5*请求成功,返回值正确, 删除`cut_point_date`之前的数据
EDBHelper.deleteEventListByDate(cut_point_date);
}
@Override
public void onPushEorr(int errorCode) {
//.请求成功,返回值错误,根据接口返回值,进行处理.
}
@Override
public void onPushFailed() {
//请求失败;不做处理.
}
}).sendEvent(EConstant.EVENT_TYPE_DEFAULT, list);
6. EPushTask模块
Push的逻辑比较复杂,所以更需要这个类,专门来做push任务.
6.1 如何保证 数据 推送不会出现重复推送,或者缺少数据?
请看如下push的逻辑.
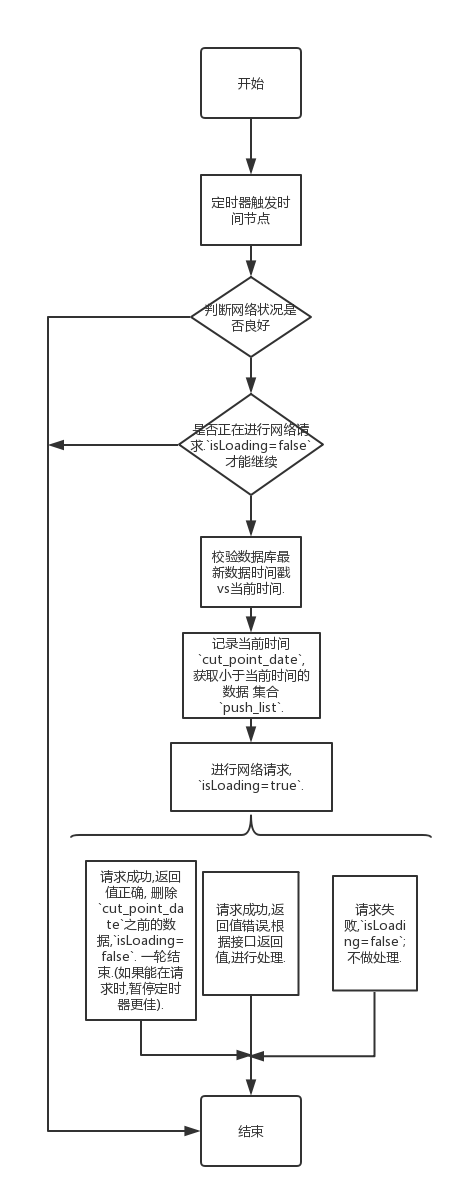
经过测试部和线上数据验证, 数据量统计无误,没有重复数据,没有遗漏数据.
7.EPushService模块
这应该是一个后台服务模块. 功能应该有 开启服务,周期推送,主动推送,停止推送.
需不需要用一个不会被杀死的后台服务?
答案是不需要,
1.从用户体验上讲,一个系统杀不死的服务,是一个用户体验极差的处理方式.有些手机 甚至会提示,该app正在后台运行.
2.从sdk必要属性上讲, 统计sdk,只有app在前台的时候,才会有事件统计.所以推送服务没有必要一直存在.
3.当系统内存不足的时候, 会把后台推送线程杀死. 但是杀死的仅仅是周期推送 ,数据记录并不会停止. 等待满足条件 (100条记录),就会主动推送.
所以,结论是 推送服务,仅仅需要在用户可见的情况下,进行即可. 线程是否被杀死,影响的仅仅是推送到服务器是否及时.
经过考量, 采用Timer+TimerTask的方式,进行周期推送服务.因为 虽然Timer不保证任务执行的十分精确。 但是Timer类的线程安全的。
而且TimerTask是在子线程中,不会push服务不会阻塞主线程.
sdk整体框架调整
1.访问权限
sdk 对外暴露类和方法,要尽可能少.只暴露用户可操作的方法.隐藏其他细节.
所以在这个sdk中,用户只需要知道 设置必要参数,开启,添加统计即可,其他无需了解.
所以,我对访问权限进行了处理,只公开以下类,以及相应方法.
-
JJEventManager事件管理JJEventManager.init()初始化JJEventManager.cancelEventPush()取消推送JJEventManager.destoryEventService()终止所有服务
-
JJEvent统计入口JJEvent.event(String ec, String ea, String el)事件JJEvent.screen(String sn, LTPType ltp)屏幕值
3.sdk唯一性
为了保证sdk命名唯一性,采用所有必要模块加前缀E代表Event的处理方式,
避免出现在业务层 查看调用出处的时候,造成误解.比如
后期,在我们做自己的业务线的时候,大家也可以采用这种方法.
2.sdk生成,版本管理,混淆打包
自己在gradle中写了一个打包脚本,让打包的过程,自动化.详情见源码.
task release_jj_analytics_lib_aar(group:"JJPackaged",type: Copy) {
delete('build/myaar')
from( 'build/outputs/aar')
into( 'build/mylibs')
include('analytics_lib-release.aar')
rename('analytics_lib-release.aar', 'jj-analytics-lib-v' + rootProject.ext.versionName +'-release'+ '.aar')
}
release_jj_analytics_lib_aar.dependsOn("build")
当然, 也可以将sdk放到Nexus Maven仓库,或者公司私有仓库,进行api依赖.
2.3 sdk需不需要混淆?
这个问题我考虑了很久, sdk给自己用,用的着混淆嘛? 混淆会不会让同事们可读性变差,想到最后,发现app上线前,也需要打包混淆.如果我在app的progurd.rules中,添加各种规则,那么sdk用起来很繁琐.
so~ , 我在 jar 包打包前,进行了必要混淆,keep了两个公开类.
现在,在任何app如果想使用sdk, 那么只需要 app的progurd.rules中添加两句混淆规则即可.
-dontwarn com.ccj.client.android.analyticlib.**
-keep class com.ccj.client.android.analytics.**{*;}
总结思考
- 在本sdk中,
由于所有动作的生命周期,是全局周期,所以,选择了sdk持有applicatin上下文进行操作.
对于需要上下文的地方,直接用持有applicatin,可以考虑
DBHelper中方法是静态的,由于依赖于其中Java静态方法,不能被静态实现..,所以依赖的实现.后期可以采用单例进行处理.
- 无从下手的感觉...无从下手的感觉的根本原因就是你没有下手去做..写写,画画,慢慢就会了然于胸.
后期优化
为了操作方便,直接让EDBHelper,ENetHelper直接作为静态类...
后期可以用单例取代.在管理类JJEventManager中,统一初始化.这样,就可以 依赖抽象.比如持有DBDao.saveEvent(),而不是用实现类EDBHelper.saveEvent().就避免了后期牵一发而动全身的问题.
About Me
===
CSDN:http://blog.csdn.net/ccj659/article/




