一、背景
内容是一个电商app不可或缺的组成部分。越来越多的人会使用碎片时间浏览手机app的内容,包含导购的帖子、短视频、直播等。1688挑货业务,打造了基于买家和商家之间老买卖关系的内容场。让商家通过内容维系老客户,挖掘新客户。让买家能第一时间获取到关注商家的上新、优惠、直播等信息,为自己的采购等决策提供帮助。
从宏观的背景分析,挑货业务有以下几个特点:
-
基于1688的老买卖关系: 关注关系、客户会员关系、星标关系、分销关系
-
内容的产生源头是供应商,供应商在1688网站的各种行为,都可以转变成内容信息
-
内容的消费源头是供应商的老买家(与供应商有老买卖关系)
-
内容形式比较多样:帖子、营销活动、店铺上新、商家动态、直播、短视频等一系列商家产生的有效内容
-
内容产生形式:供应商的主动行为、供应商的被动行为
基于上面的业务特点,我们梳理下挑货整体的业务架构。
二、业务框架
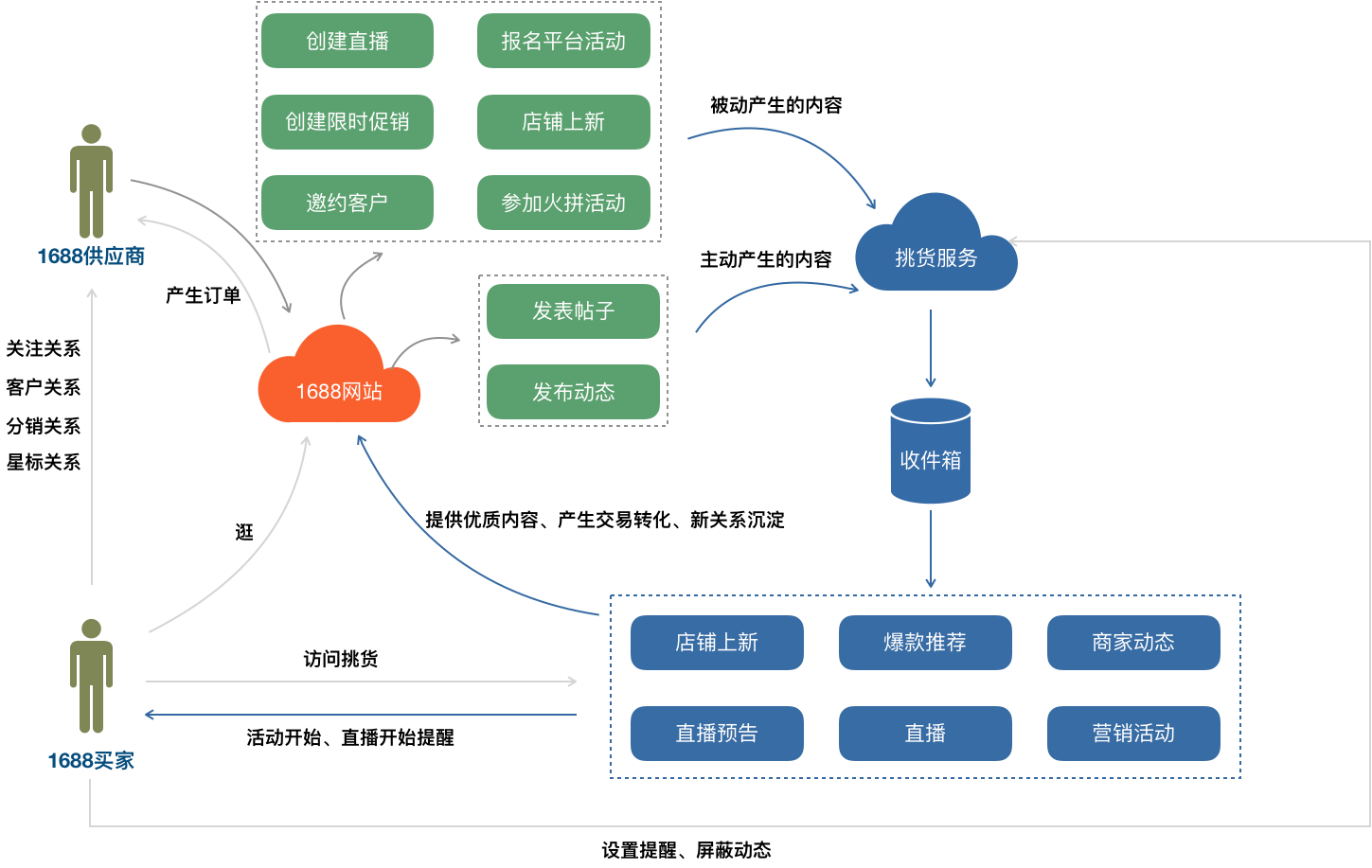
-
供应商在1688网站可以直接将动态和文章发布到挑货。
-
供应商在1688网站的直播、店铺上新、报名营销活动、邀约客户等行为,会被挑货服务识别到,被动抓取到挑货。
-
挑货将供应商产生的内容推送到供应商老买卖关系的买家收件箱中。
-
买家访问挑货时,挑货服务会从买家收件箱中将内容渲染成各种业务卡片,呈现到客户手机端。
-
买家可以对部分有时效性的内容(直播预告、未开始的互动)设置订阅提醒,当直播开始、活动开始时,挑货服务主动通过消息告知买家。
-
买家可以通过挑货平台去到供应商的店铺和商品详情去购买商品,产生交易订单。
-
挑货中的优质内容,可以投放到1688网站的其他模块,新用户看到后,能有效的产生交易和关系转化。
-
新用户访问挑货时,挑货服务会推荐部分优质供应商给用户,用户可以关注供应商,看到供应商的挑货内容。
挑货的业务价值在于可以维系供应商的老买卖关系,提供买家快速获取供应商信息的内容,另外可以为供应商引入新的客户,并沉淀为老买卖关系。而挑货的优质内容可以投放到1688网站公域频道,一方面节省运营成本,另一方面为供应商引入更多的新用户。挑货在1688公域、私域流转上承担着枢纽的作用。
三、技术框架
为了实现挑货的业务架构,在1688无线领域孵化出多个技术方案。下面就其中关键的技术细节进行下描述。
挑货总架构图
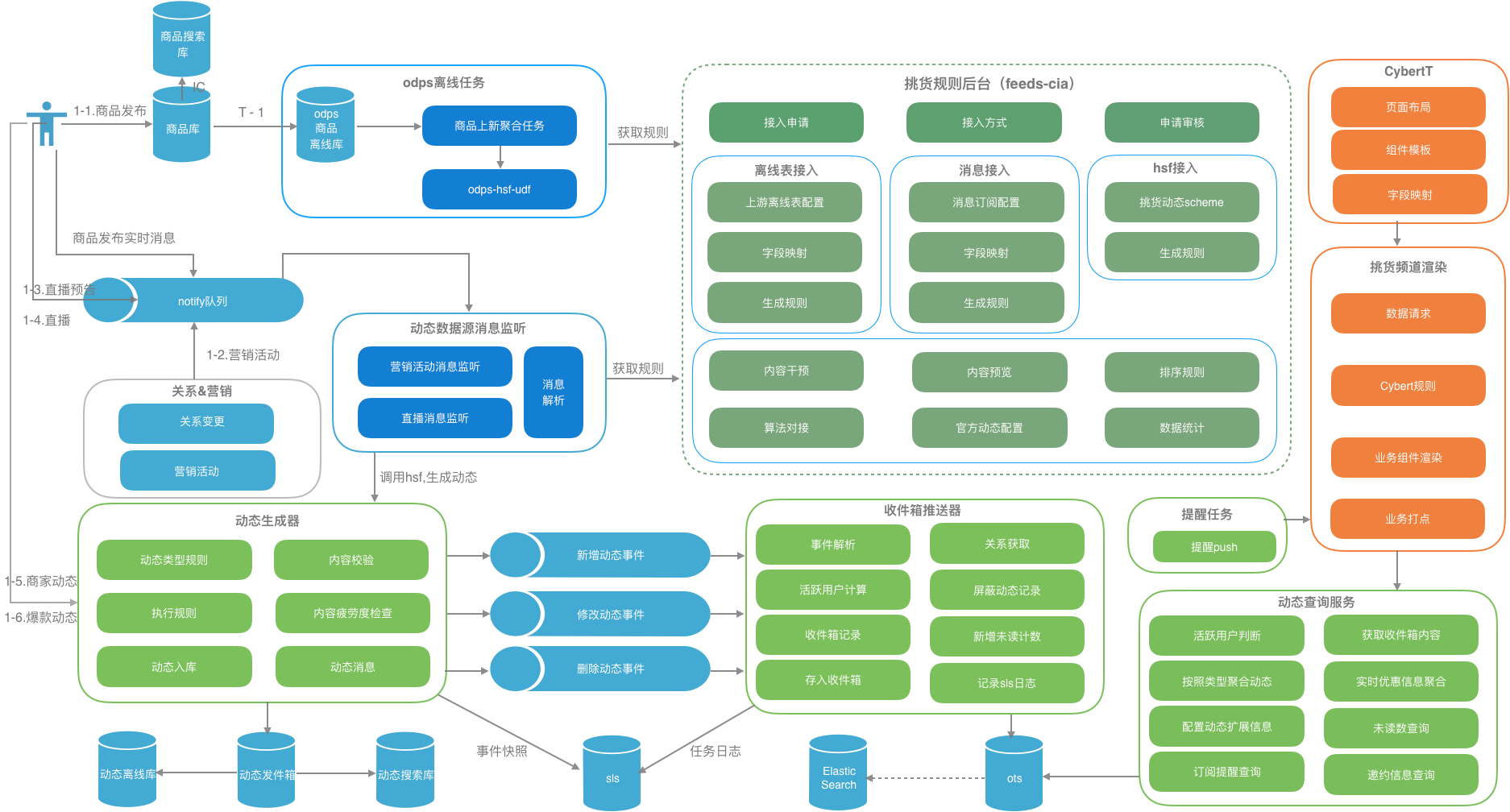
-
业务对接方式:离线任务、消息对接、实时rpc
-
feeds流的推拉引擎:feeds动态生成器、feeds的收件箱推送、架构图未包含非活跃用户走拉的模式、feeds流查询服务
-
动态组件的对接方案Cybert:业务模型和组件UI分离、动态生成native组件
-
个性化算法对接方案(未包含)
-
异构系统的监控体系(未包含):多种中间件平台实现同一个业务时,异构系统的监控成为一大难题。在挑货中,已经设计出了方案,目前正在对接中。
-
数据统计系统
1. feeds流推拉结合的引擎
挑货的内容从供应商产生,到供应商的买家去消费,是典型的feeds场景。实现一个feeds流业界比较流行的主要是推模式、拉模式、或者是推拉结合的模式。
推模式:内容产生后,会为每一个订阅内容的粉丝复制一份内容,放入粉丝独有的收件箱中。
-
优点:粉丝读取内容非常快,只是一个表查询。在写的过程中可以做很多业务干预。
-
缺点:写的成本比较高,需要很多耗费存储,数据冗余。
拉模式:内容产生后,只会存入内容产生者的发件箱。读取时,需要粉丝读取每一个被关注用户的发件箱,实时将内容聚合到一起排序,最终展现给粉丝。
-
优点:存储耗费少,写入速度快。
-
缺点:查询都需要耗费很多计算资源做内容聚合,业务干预规则多时,会更加加重查询复杂度,查询性能会下降。
推拉模式:综合推模式、拉模式的优缺点使用的方案。
我们从挑货业务的特点和已有的技术积累两个方面,选取了推拉结合,以推为主、拉为辅的技术方案。
-
1688有独立的关系团队维护了1688所有的老买卖关系数据,已经成为1688底层基础服务。而微淘的关系和微淘的内容之前是在一个团队孵化出来的。目前1688关系是B类的老买卖关系,和淘系的关系没有打通。基于老买卖关系的挑货不能直接复用微淘关系的技术。
-
微淘开发的timeline的拉引擎,使用多级缓存,很好的支持了微淘业务的发展,在feeds流拉模式上有很强的专业性。而集团搜索团队的igraph图数据引擎也能很好支持数据多维度拉取功能。igraph有详细的文档、成体系化的接入和运维方案、专业的答疑。从对接的成本和后期运维角度,我们选择了igraph作为拉引擎。
-
选择以推为主,拉为辅的策略的原因:
-
数据规模比较小:1688的老买卖关系总量在4亿,一个粉丝比较多的供应商的粉丝数量级在几十万,而在挑货频道活跃的粉丝,对应一个供应商量级在5万以下。更多的在几百到上千。所以这种量级的数据,使用推模式能很好的支持查询性能。
-
集团的中间件平台非常成熟:在blink平台开发feeds流的收件箱推送功能,能根据数据规模扩缩容资源,有效的支持大规模数据的推送。tablestore是一个单表支持10PB数据的nosql,作为挑货买家收件箱非常合适。
-
业务的规则干预比较多:需要支持屏蔽动态这样干预feeds展现的业务规则。
-
下面看下挑货feeds流引擎的架构图:
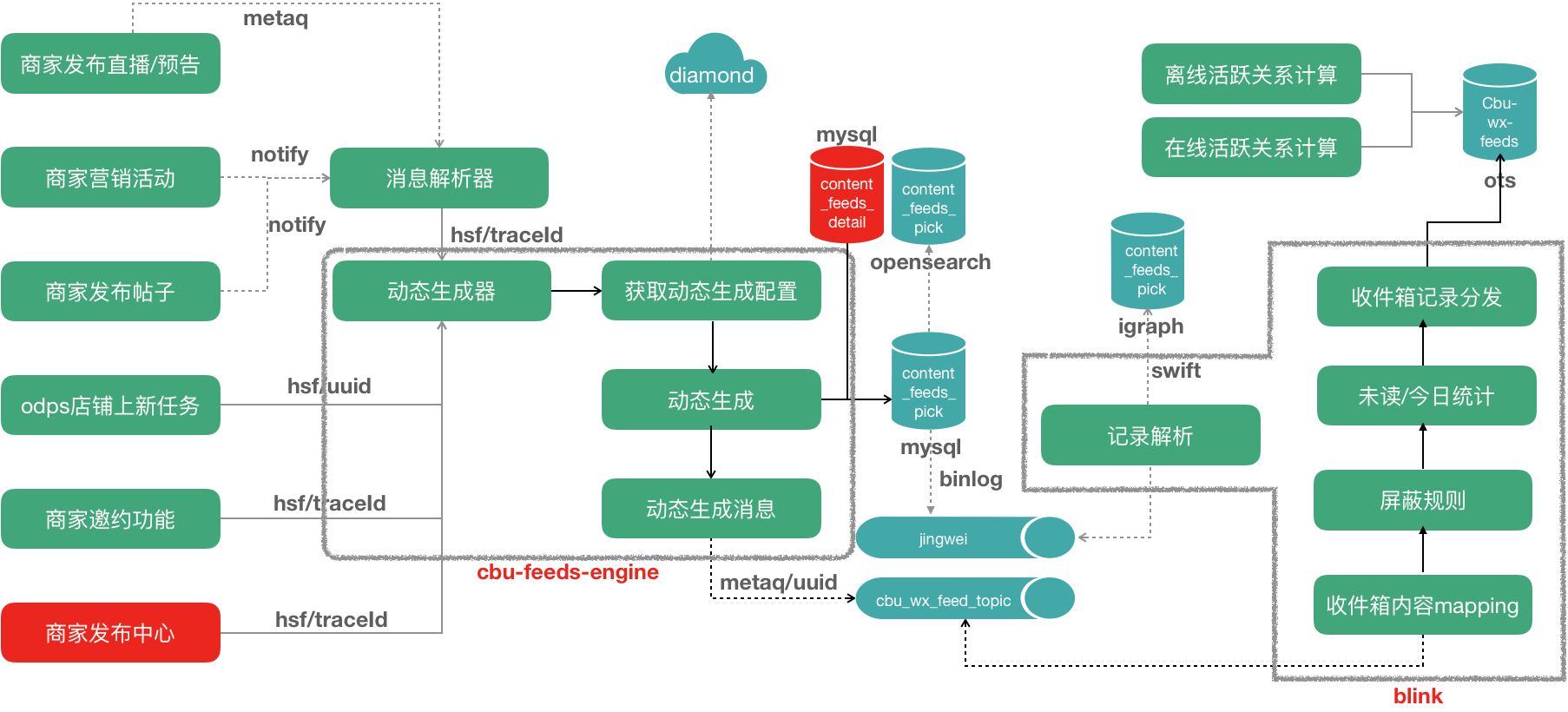
-
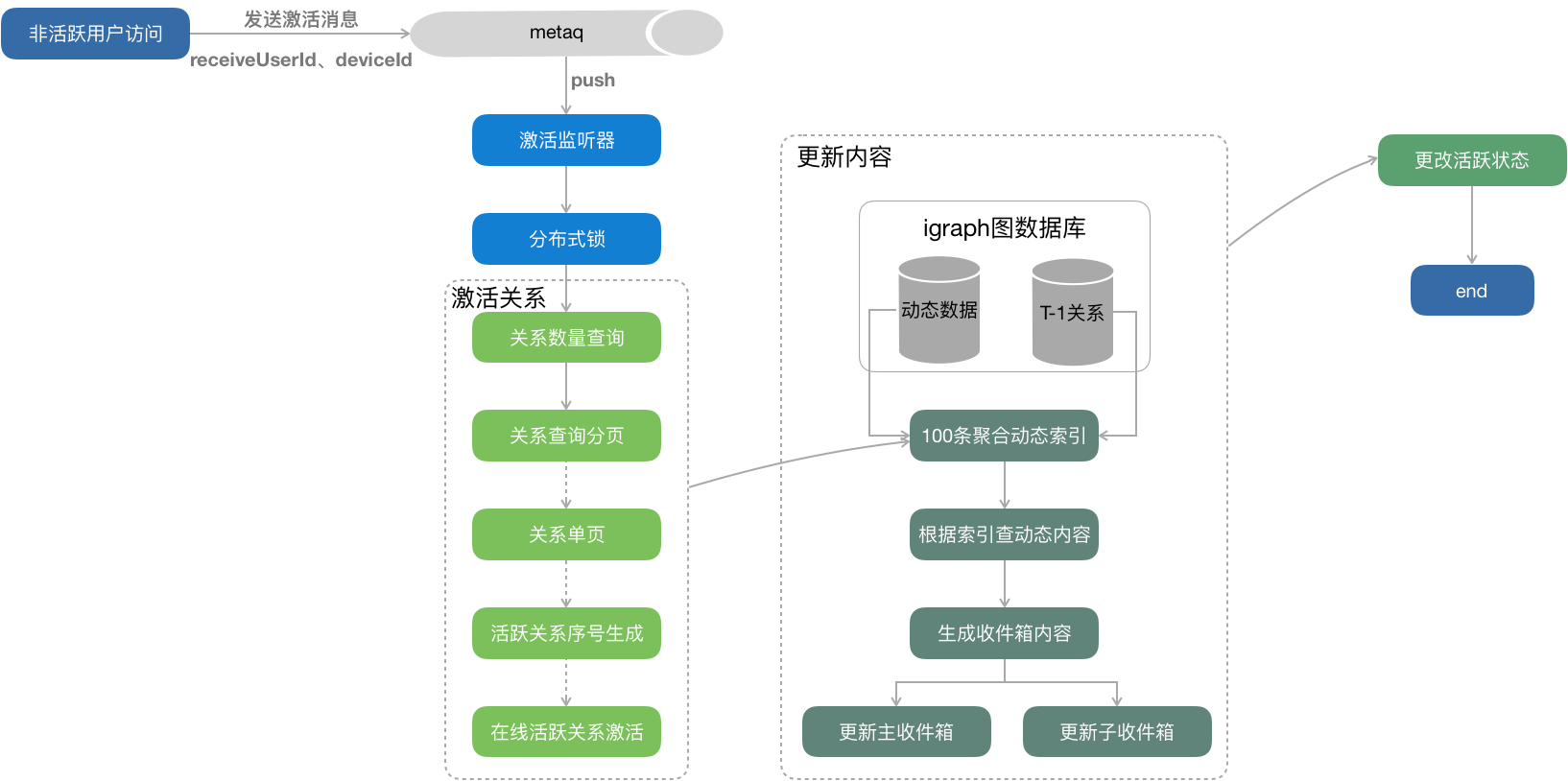
内容数据流入动态生成器,产生挑货feeds,挑货feeds生成后发送metaq消息,被运行在blink上推送任务监听到,将动态索引写入到用户到收件箱。
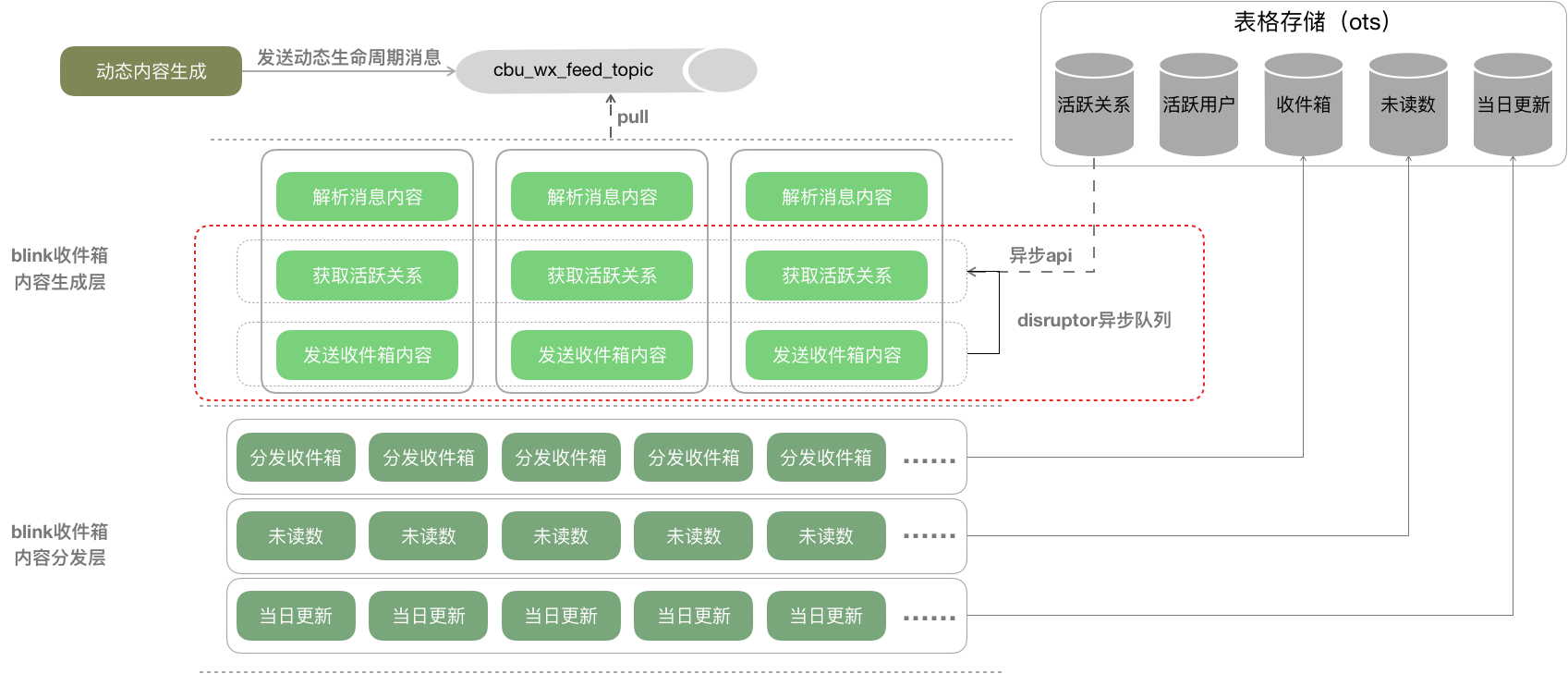
下面3张比较细节的图:
-
活跃用户-推模式2.非活跃用户-拉模式
 3.非活跃用户激活策略
3.非活跃用户激活策略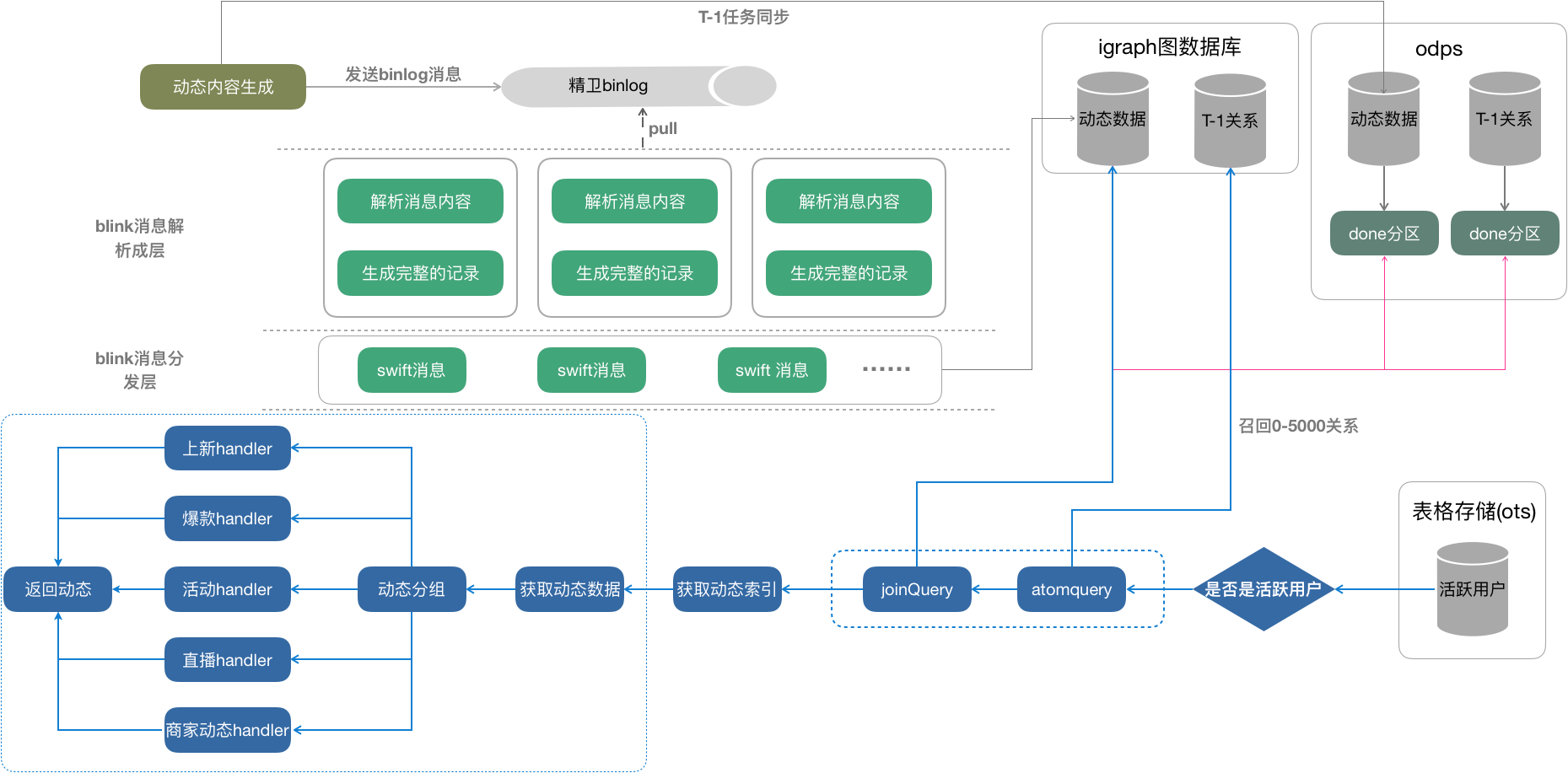
2. 动态组件的对接方案Cybert
Feeds列表原有纯native的技术解决方案,对业务的核心痛点就在于发版周期和覆盖率的限制;1. 半个月的发版周期严重限制了业务日常营销活动、用户活跃提升的运作方式,业务更希望营销类的活动卡片做到快上快下,不跟随发版节奏;2. 纯native卡片还是依托与发版,新的营销活动为了达到最佳效果,还期望于版本的覆盖率,虽然目前安卓、ios的新版本覆盖周期已经越来越短,但不代表可以做到像weex一样立马全版本覆盖。
鉴于这些业务痛点,我们可以采用的技术方案有两种1. 全weex化;2. native动态化。先从weex化来说起,去年整个营销场在整体完成性能优化后,我们已经做到ios95%会场秒开,安卓超过85%,这个秒开率对于挑货feeds来说已经足够。但当时没有采用全weex化的方案更多出于以下几点考虑:1. 交互或者后期的tabview支持,挑货feeds作为第二个主tab性能、交互、稳定性都必须去强保证,会场一些tab切换层面我们可以接受刷页面的方案,但在核心主tab我们还希望做到更佳的用户体验;2. 改造成本,原有native卡片化的方式,如果整体切换就意味这页面全部重做,这个改造成本不小。因此,我们考虑是否可以把应用在首页、工作台的native动态组件化方案做能力扩展,支持类似挑货这类列表组件由“数据驱动ui”的渲染方式,老卡片仍然采用native方案,新组件采用dinamic组件插入,既做到老方案兼容,有做到新组件动态发布。在技术改造成本、动态性、业务支撑、交互体验多个点上做平衡。
这里,我先简单介绍下目前首页cyber动态组件化方案的业务价值、技术架构和能力。CyberT原生孵化于首页,核心点就是native组件化方案,后续因为业务对于动态性能力的要求,支持了weex组件、dinamic组件的扩展,两个动态化组件化方案看dinamic组件在首页的性能从渲染耗时、内存开销上更优。由服务端下发页面布局协议、组件ui协议、服务端数据协议来驱动端上的渲染,同时在ui协议上打平后可以做到组件单端投入双端生效,后续也在进一步支持h5外投方案。
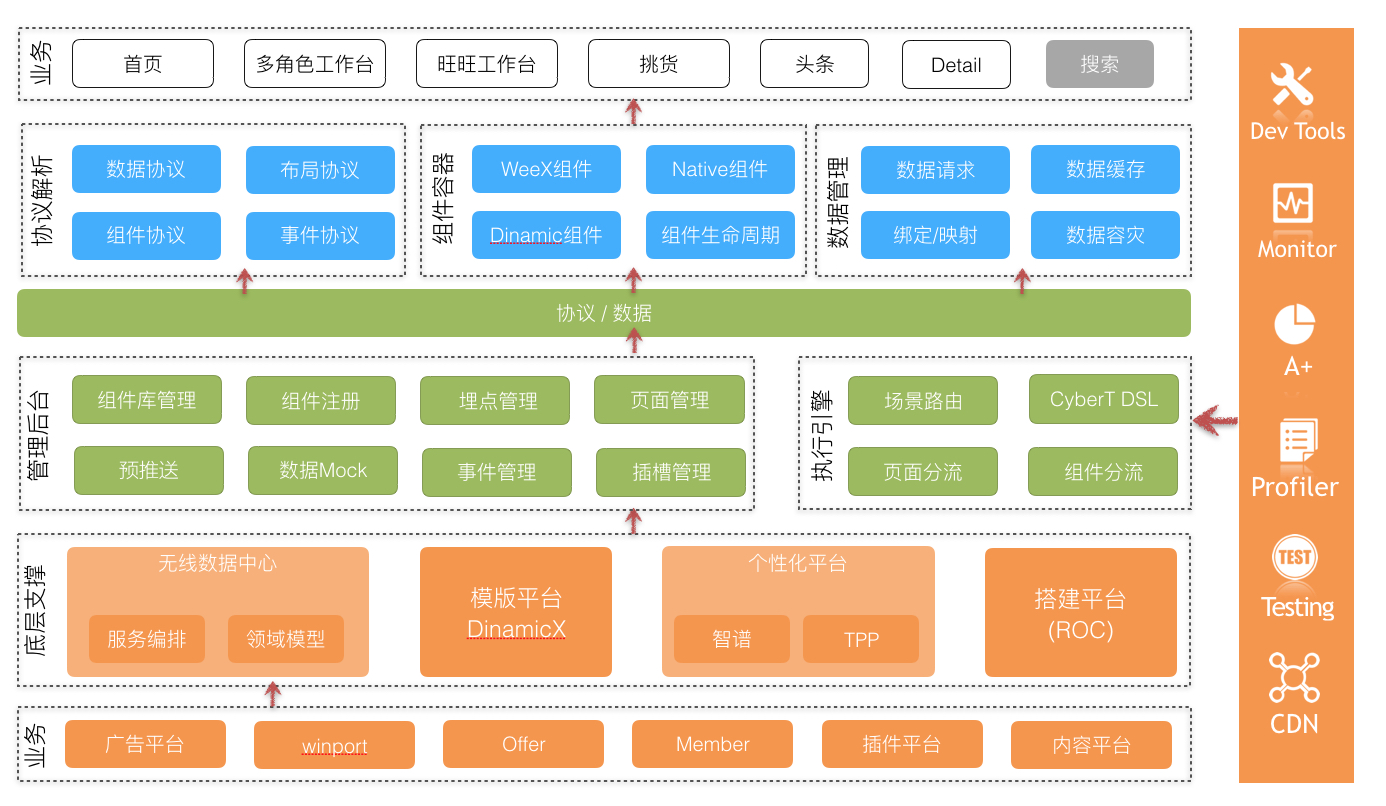
而对于feeds列表的场景,我们如何升级能力做到“数据驱动ui”?这主要是升级List复杂容器的支持,list组件的特点是由数据决定有多少个cell。cybertron 的layoutprotocl 支持list组件声明其cell的类型 ,根据服务端返回的list数据,结合cellMapping & datamapping规则,会生成一个个cell实例,并且在框架层支持了常见的分页加载(page模式和offset模式)。
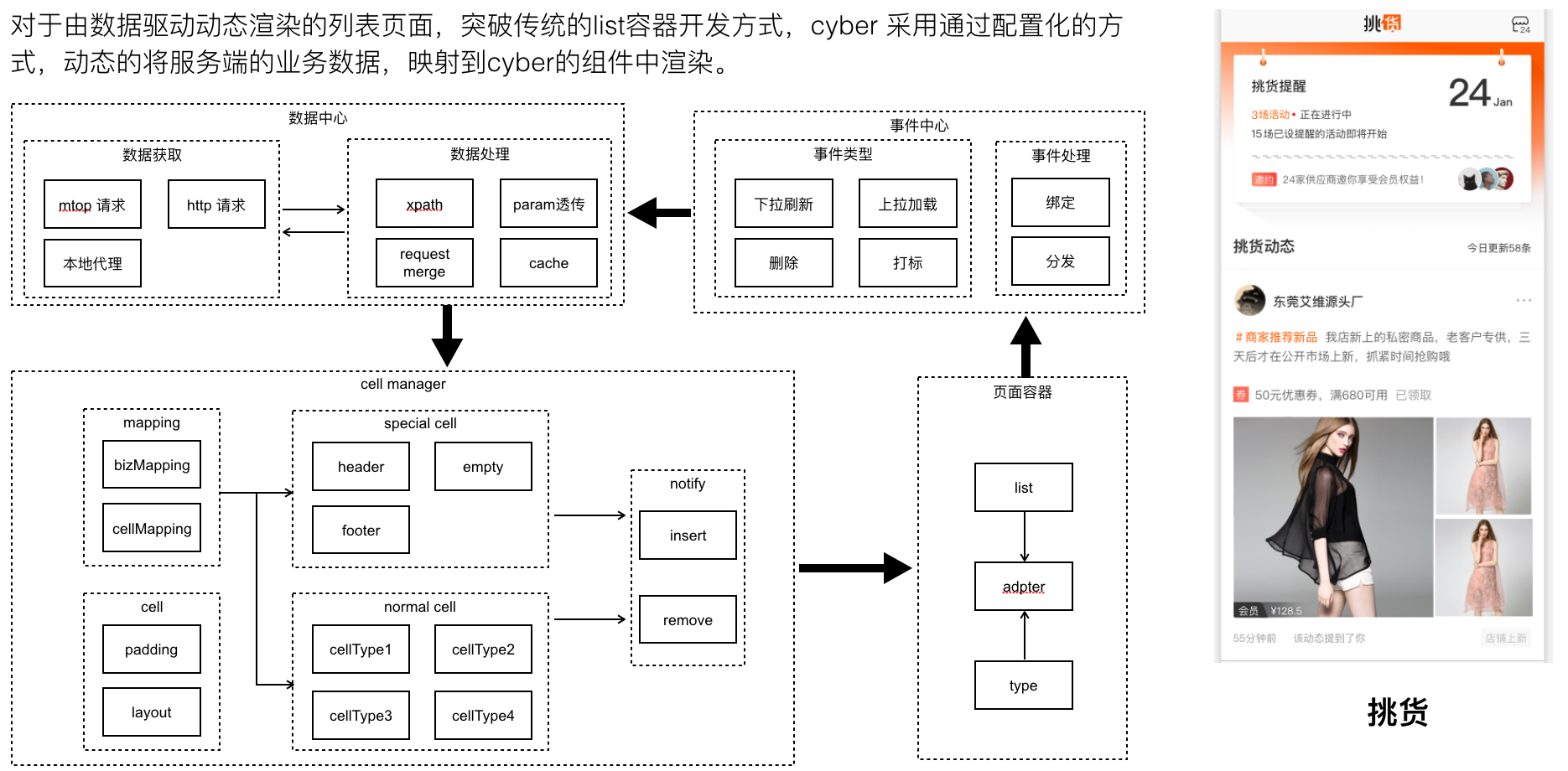
这样,由搭建平台配置组件和映射协议,业务服务端下发数据,通过cybert容器的客户端sdk实现协议、数据解析进行页面的动态渲染。
3. 挑货个性化算法对接(实时特征计算)
-
优化内容排序:用户在1688手机阿里上各种访问行为,特别是在挑货的访问行为,会被抽象成用户的行为特征。通过这些行为特征,根据对应的算法,将用户收件箱中最感兴趣的内容排序到最前面,增加用户的阅读体验。
-
提取优质的内容:用户的对内容行为,通过一定的算法,可以给内容进行评分,提炼出优质的内容。这些优质内容可以投放到其他公域场景,为商家带来更多的价值。
4. 异构系统的监控体系
整个挑货系统,数据在多个系统中流转,一旦某个系统出现故障,很难排查和追踪问题。现有的监控体系对同构的应用的链路监控已经支持的很完善。一旦涉及到在线应用、离线任务、实时流计算多个异构的系统,就无法有效的做到串联。为了保证挑货的稳定性,我们设置了全局的uuid,将整个系统的日志采集到云日志中。通过专门的监控系统,去分析日志,做到链路预警和数据可视化。
5. 数据统计系统
挑货业务承接是1688整个买家的内容需求。从业务在挑货的展现的PV、UV到具体的业务转化率,再到新业务的AB效果对比,都离不开数据化支持。所以数据化是挑货系统的必不可少的组成部分。我们实现思路,从规范业务打点方式入手,到数据日志输出规范、数据统计模块、可视化系统,完成一个闭环的数据化系统。
四、未来发展
-
内容对接平台化(配置化、数据化):打造一个内容对接流程、内容数据展现、内容投放的配置后台。
-
feeds引擎的抽象,支持更多的业务。
作者简介
葛圆根,就职阿里巴巴,花名水锋,采源宝和手机阿里挑货技术负责人。13年起先后负责过1688内容平台、阿里头条、采源宝、挑货等多个产品的架构和研发工作。在内容平台的架构、电商app架构设计和开发、流式计算上经验丰富。

如果您有实时报表/实时数据大屏/实时金融风控/实时电商推荐等相关实时化数据处理需求,可以加入如下钉钉交流群!