2017年的双11,虽然仓配系统做了非常多业务端的优化,使得峰值不会达到如交易系统那般恐怖的程度,但仓配业务链路长、节点多、分析维度复杂的业务特点,也使我们在开发仓配实时数据的过程中,面临了不少挑战。而正好基于双11的业务背景,我们也开始着手建立起带有"仓配特色"的实时数据版图。
双11仓配业务系统的预估峰值是日常峰值的n倍以上,我们应该如何保障仓配实时数据如丝般顺滑呢?本文将从全局设计、数据模型、数据计算、数据服务、数据应用、数据保障等各方面作简单介绍。
一. 全局设计
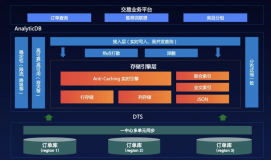
实时数据能够如丝般顺滑,离不开各个系统之间的紧密协同。从需求评审的一开始,我们就制定了一套端到端的技术方案。如下图:
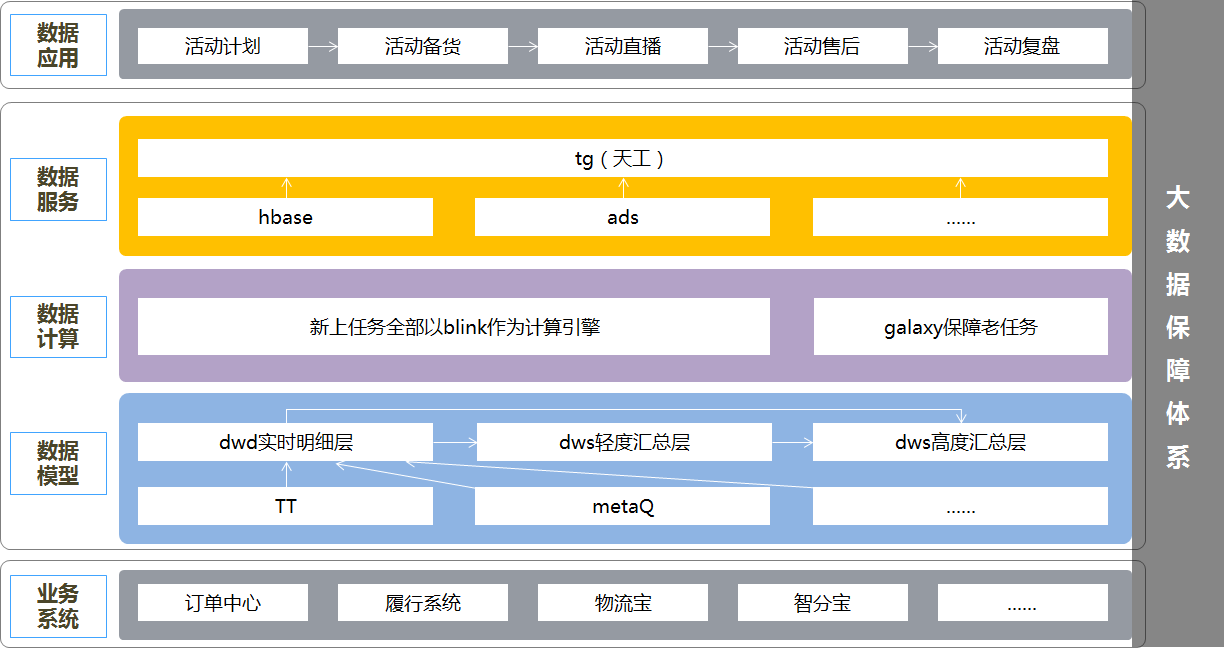
图中的内容显而易见,基于业务系统的数据,数据模型采用中间层的设计理念,建设仓配实时数仓;计算引擎,选择更易用、性能表现更佳的blink作为主要的计算引擎;数据服务,选择天工数据服务中间件,避免直连数据库,且基于天工可以做到主备链路灵活配置秒级切换;数据应用,围绕大促全链路,从活动计划、活动备货、活动直播、活动售后、活动复盘五个维度,建设仓配大促数据体系。
二. 数据模型
不管是从计算成本,还是从易用性,还是从复用性,还是从一致性……,我们都必须避免烟囱式的开发模式,而是以中间层的方式建设仓配实时数仓。与离线中间层基本一致,我们将实时中间层分为两层:
第一层是dwd公共明细层,将一些相同粒度的业务系统、维表中的维度属性全部关联到一起,增加数据易用性和复用性。能将这么多的数据源秒级延迟的情况下产出,也得益于blink强大的状态管理机制。
第二层是dws公共汇总层,以数据域+业务域的理念建设公共汇总层,与离线有所不同的是,我们根据业务需要,将汇总层分为轻度汇总层和高度汇总层,为了保障数据的时效性,这两层数据会直接依赖dwd,分别写到ads和hbase中。
以仓配最重要的“物流订单/包裹明细表”为例,简要的数据模型方案设计如下:
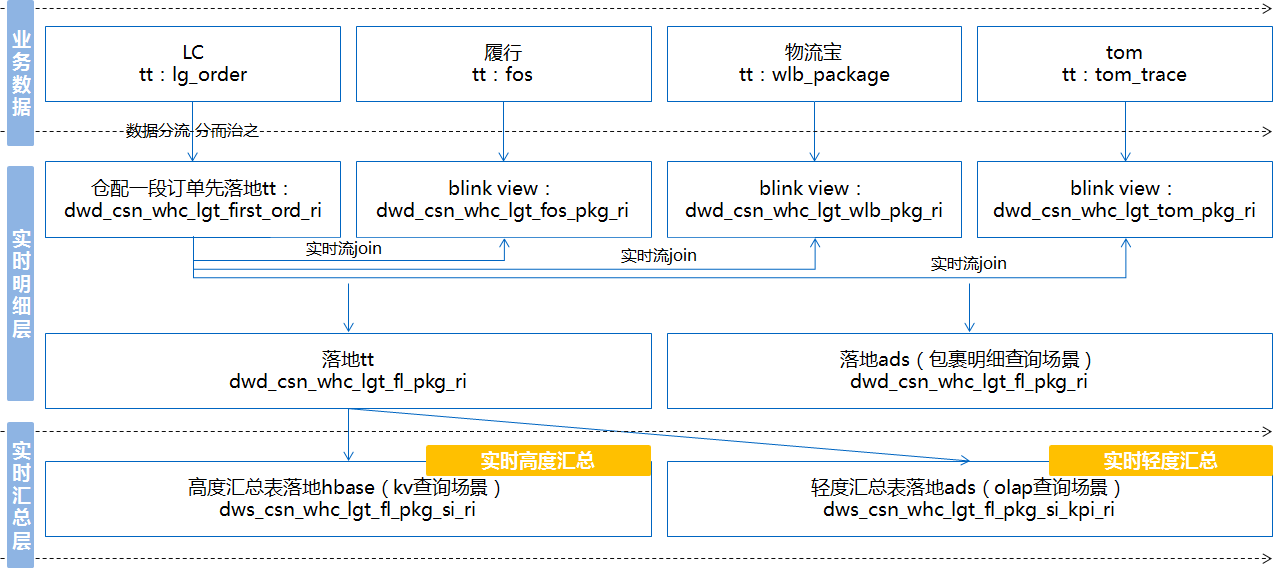
与原来的模型设计方案相比,现在的模型设计方案有如下优势:
-
从lg_order中分流出仓配订单产出dwd_csn_whc_lgt_first_ord_ri,供下游物流订单明细、物流包裹明细等实时作业使用,避免从lg_order中直接读取全量数据,减少不必要的IO;且我们把一些常用的逻辑,如预售标、预约配送标、时效标等全部解析出来,供下游使用。
-
重新定位各个业务系统的角色,LC获取一段订单信息,履行获取计划信息,物流宝获取仓内及物流属性信息,tom获取配送全链路信息,角色分明,同样的属性只从一个系统出,如体积属于物流属性,以物流宝为准,应签收时间是计划信息,以履行履行为准。这样,最终将多条实时流join到一起形成最终的明细表,一方面不再像618一样将履行和实操数据拆分成两张表,提升数据的易用性;另一方面减少烟囱式的读取数据,增加数据的复用性。
-
汇总层分为轻度汇总层和高度汇总层,轻度汇总层写入ads,用于前端产品复杂的olap查询场景,满足自助分析;高度汇总层写入hbase,用于前端比较简单的kv查询场景,提升查询性能。
三. 数据计算
今年双11,我们选择blink作为主要的实时开发引擎,主要用于产出核心的明细表和部分汇总表;辅以galaxy,主要处理以前遗留的历史作业。为什么选择blink作为今年主要的实时开发引擎呢,基于之前的调研,我们一致认为blink有几点功能特别具有吸引力:
-
强大的blinkSQL功能:双流join功能,不仅支持两条数据流join,而且可以在一段代码中实现多条数据流join操作;子查询功能,代码中允许使用子查询,与离线odps基本相同,不需要做任何处理;视图功能,可以将复杂的SQL语句封装成视图,使代码更清晰,且数据无需落地成tmp表;维表join功能,支持join hbase维表,且blink为维表join做了诸如 async、cache、multi-join-merge 等优化,使得维表join的性能非常优异……
-
强大的流计算性能:blink团队做了非常多的计算性能优化,诸如MiniBatch优化、维表cache&async、ignore delete、rockDB进行状态管理以及可以灵活配置资源参数等。经过多次的压测结果显示,我们不少明细数据的中间层tps_in能达到非常恐怖的处理速度,这大大超出了我们的预期。
而上面介绍的两点,还仅仅只是一小部分,基于仓配业务的特点,我觉得我们有必要分享几个非常惊艳的小功能:
-
强大的First&Last:仓配实时数据的大部分数据来自tt,当一条订单频繁更新时,会向tt中流入多条消息,而实际我们需要是最新的一条消息,如何获取最新的消息呢?经过多方打探,我们了解到tt是根据tt订阅时设置的主键保序的,首先要保证订阅的主键按照业务需要设置正确,其次我们需要借助blink提供的强大StringFirst&StringLast函数(StringFirst可以轻松获取第一条消息的非null数据,而StringLast可以获取最后一条消息的非null数据),就可以轻松获取最新的消息数据。详细可以参见军长大神的文章,https://www.atatech.org/articles/94209
-
强大的Retraction机制:刚刚在1中提到,数据库的同一记录不断变化,会往tt中流入多条消息,如果我们依赖这个tt订阅直接作一些汇总操作,可能得到的记录是不对的,举例来说一笔订单开始计划配送公司是中通,后来计划配送公司变成了圆通,那么直接针对配送公司进行汇总可能得到的结果是中通和圆通各一笔。如何来处理这种“变key”的场景呢?这需要借助blink的Retraction机制,需要先使用last函数作特殊处理,然后再做聚合,才能保证最终汇总数据的准确性。详细可以参见乔燃大神的文章,https://www.atatech.org/articles/94607
-
小而美的nullValues参数:我们都知道,如果源数据某行记录某个字段的值是null的时候,从tt流下来的数据,会将null转化成字符串\N,这样对下游使用非常不方便,尤其有用到coalesce等函数的时候,都需要对\N进行特别处理,如何能像离线odps一样"慵懒"的处理这种数据呢?blink在定义inputTable的时候,提供了nullValues参数,比如在订阅tt inputTable的时候,添加nullValues='\\N|',blink可以将tt中的\N和空字符串,全部转换成null。这样下游就可以正常使用coalesce等函数时,而不需要对每个字段中的\N和空字符串进行特殊处理了。
-
高效的状态管理机制:实时计算过程中(如gby、join等)都会产生大量的state,传统的流计算引擎基本都是选择外部存储(如hbase)作为state存储方案,blink的选择是单机性能十分优异的rocksDB,这个方案大大缩短了IO latency,从而获得倍数的性能提升。结合rocksdb的数据生命周期参数state.backend.rocksdb.ttl.ms,我们可以轻松应对仓配物流周期长的业务特点。
在实操中,我们还用到了并发调优、minbatch调整、写tt使用hashFields保序、特殊场景写ads ignore delete等不少非常实用的开发和优化技能,这里就不再一一介绍了,有相关实战的同学欢迎随时沟通。
四. 数据服务
因地制宜,在合适的场景选择合适的数据服务。针对查询时效要求较高的场景,我们选择hbase;针对复杂的olap场景,我们选择ads。在此基础上,我们使用菜鸟数据部自研的天工作为数据服务中间件,一方面屏蔽底层数据库的差异,另一方面利用天工的逻辑表实现主备链路的灵活配置,秒级切换。
五. 数据应用
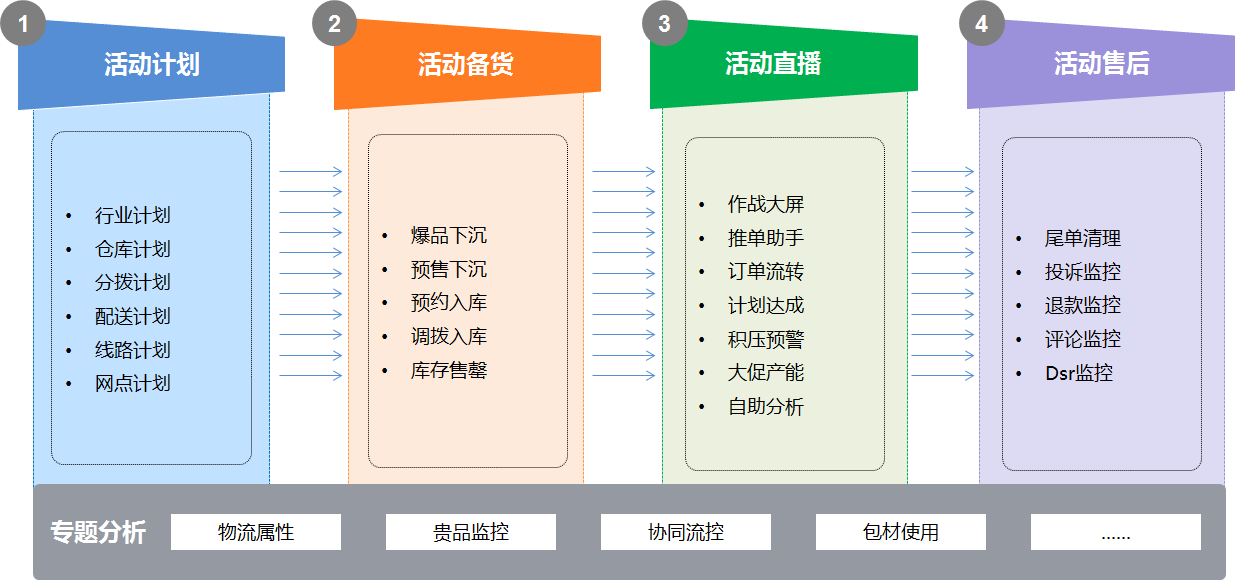
围绕大促全链路,从活动计划、活动备货、活动直播、活动售后、活动复盘五个维度,建设仓配大促数据体系。基本的数据全链路场景如下图,这里不再赘述。
六. 数据保障
针对今年双11的数据保障,我们做了很多事情,这里只简单介绍一下仓配实时链路的主备方案和数据服务的主备双活方案。
-
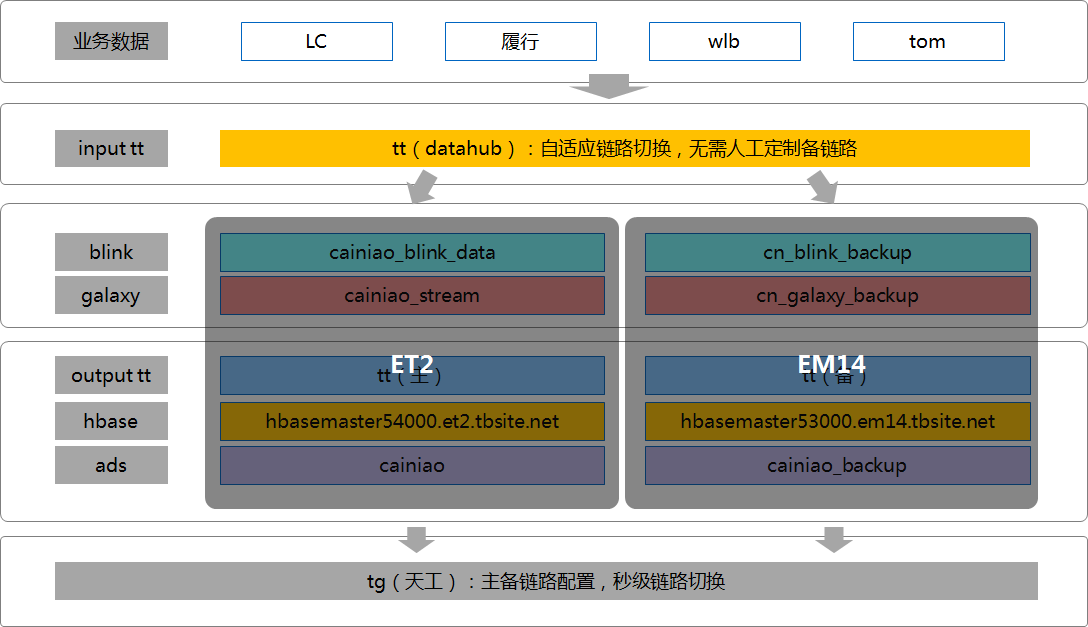
实时主备链路
对于非常重要的P0P1的实时数据,今年仍然采用实时双链路的保障方案,主链备链完全独立,主链路全部在et2机房,备链路在em14机房,这样就能做到跨机房容灾,当某条链路出现问题时,能够秒级切换到其他链路。简要介绍如下图:
-
数据服务主备双活
今年菜鸟对ads的使用非常多,除仓配业务之外,进口、出口、末端等业务也有部分的实时应用依赖ads。经过分析,我们发现这里面仓配的实时应用是大头,如果仓配跟其他业务同时使用主库,难免不会不对其他业务造成影响。所以,最终我们采取了主备双活的方案,将仓配一部分页面的数据切置备库,保证万一仓配业务发生故障时,不至于对其他业务造成影响。
-
多条实时链路压测
双11期间,100%的数据可用性,当然离不开实时链路压测的功劳。为了顶住日常50倍峰值的TPS,我们准备了5条实时压测链路,如下:
a. 实时主链路
b. 实时备链路,为P0/P1级应用而准备
c. 交易压测链路,为配合集团交易链路压测而准备
d. 全链路压测链路,为配合集团全链路压测而准备
e. 菜鸟压测链路,菜鸟“特色链路”
其中,e链路是菜鸟的“特色”链路,为什么这么说呢?上文中数次提到仓配的业务周期特别长,双11期间从物流订单创建到签收全部签收可能不止1天,加上仓配上游系统特别多,LC、WLB、TOM、FL又是完全独立的系统,需要多条实时流的join操作,如果压测仅用tt中保存的3天的历史数据,很难真正压测出效果,很可能因为周期过短导致最终关联上的记录没有实际的多,所以我们将odps tt4表最近20天的数据导回tt,基于odps离线导回来的最近20天的消息量进行压测,这是当前最适合仓配的压测模式,也是能发现问题最有力的手段之一。
七. 后续展望
虽然双11已经结束,但是我们有必要复盘一下过程中遇到的一些遗留问题:
-
压测过程过于复杂,人为的工作太多,后续的压测链路需要实现自动化的全链路压测,也许是一个按钮、也许是一句口令……就能完成各条链路的压测。
-
揽收x小时未签收等指标,暂时没有想好更好的实现方案,只能从ads的明细表中获取,对ads的查询压力太大,后续需要调研其他实现方案。
-
类似CBO的自适应资源配置,将人的经验进一步整合,形成自动化的资源配置优化方案,避免大量的人工优化。
-
防火防盗防倾斜,针对gby端的数据倾斜,一般的做法是两次gby处理,第一个gby局部聚合,第二个gby全局聚合,后续需要调研是否能像离线odps的skew gby参数一样,自动去做,而不是认为去写两次gby操作。
-
离线数据的处理,实时和离线的大统一也许就在某一天。
-
天工端做了非常多的逻辑处理,后续可以适当将一些通用的数据服务接口公共化,提升接口复用率。
八. 作者简介
贾元乔(缘桥),来自菜鸟-CTO-数据部-仓配数据研发,主要负责菜鸟仓配业务的离线和实时数据仓库建设以及创新数据技术和工具的探索和应用。

如果您有实时报表/实时数据大屏/实时金融风控/实时电商推荐等相关实时化数据处理需求,可以加入如下钉钉交流群!