推荐阅读:带你搞懂朴素贝叶斯分类算法
首先放代码
function NB(data) {
this.fc = {}; //记录特征的数量 feature conut 例如 {a:{yes:5,no:2},b:{yes:1,no:6}}
this.cc = {}; //记录分类的数量 category conut 例如 {yes:6,no:8}
}
NB.prototype = {
infc(w, cls) { //插入新特征值
if (!this.fc[w]) this.fc[w] = {};
if (!this.fc[w][cls]) this.fc[w][cls] = 0;
this.fc[w][cls] += 1;
},
incc(cls) { //插入新分类
if (!this.cc[cls]) this.cc[cls] = 0;
this.cc[cls] += 1;
},
allco() { //计算分类总数 all count
var t = 0;
for (var k in this.cc) t += this.cc[k];
return t;
},
fprob(w, ct) { //特征标识概率
if (Object.keys(this.fc).indexOf(w) >= 0) {
if (Object.keys(this.fc[w]).indexOf(ct) < 0) {
this.fc[w][ct] = 0
}
var c = parseFloat(this.fc[w][ct]);
return c / this.cc[ct];
} else {
return 0.0;
}
},
cprob(c) { //分类概率
return parseFloat(this.cc[c] / this.allco());
},
train(data, cls) { //参数:学习的Array,标识类型(Yes|No)
for (var w of data) this.infc(String(w), cls);
this.incc(cls);
},
test(data) {
var ccp = {}; //P(类别)
var fccp = {}; //P(特征|类别)
for (var k in this.cc) ccp[k] = this.cprob(k);
for (var i of data) {
i = String(i);
if (!i) continue;
if (Object.keys(this.fc).indexOf(i)) {
for (var k in ccp) {
if (!fccp[k]) fccp[k] = 1;
fccp[k] *= this.fprob(i, k); //P(特征1|类别1)*P(特征2|类别1)*P(特征3|类别1)...
}
}
}
var tmpk = "";
for (var k in ccp) {
ccp[k] = ccp[k] * fccp[k];
if (!tmpk) tmpk = k;
if (ccp[k] > ccp[tmpk]) tmpk = k;
}
return tmpk;
}
};
1.学习(train)功能
学习功能非常简单,只是将学习的数据进行统计
代码实现你可以查看代码中的train函数
假设,某个医院早上收了六个门诊病人:
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
我们先统计记录这些信息数据:
var nb = new NB();
var data=[
{d:["打喷嚏","护士"],c:"感冒"},
{d:["打喷嚏","农夫"],c:"过敏"},
{d:["头痛","建筑工人"],c:"脑震荡"},
{d:["头痛","建筑工人"],c:"感冒"},
{d:["打喷嚏","教师"],c:"感冒"},
{d:["头痛","教师"],c:"脑震荡"},
];
for(var i of data){
nb.train(i.d, i.c);
}
统计结果:

2.预测(test)功能
预测功能就要用到朴素贝叶斯算法
首先来看,贝叶斯公式:
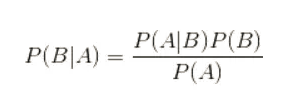
可能你看不懂公式或看懂公式不知道公式怎么用
那我来简单的翻译一下:
P( Category |Feature) = P ( Feature | Category ) * P( Category)/ P(Feature)
其实也是就是:
P(类别|特征)=P(特征|类别)*P(类别)/p(特征)
所以我们只要计算以下数据即可:
P(特征|类别)
P(类别)
p(特征)
假设两个类别,分别是类别1,与类别2
那么类别总次数就是两个类别出现次数总和
加上可能我们输入的特征有多个假设就3个把那么也简单:
P((特征1、特征2、特征3)|类别1)= P(特征1|类别1)*P(特征2|类别1)*P(特征3|类别1)
P(类别1)=类别1的次数/(类别总数)
P(特征1、特征2、特征3)=P(特征1)*P(特征2)*P(特征3)
因为根据公式我们知道:
P(类别1|特征)=P(特征|类别1)*P(类别1)/p(特征)
P(类别2|特征)=P(特征|类别2)*P(类别2)/p(特征)
刚好p(特征)为分母所以如果比较P(类别1|特征)与P(类别2|特征)的概率
只要比较P(特征|类别1)*P(类别1)与 P(特征|类别2)*P(类别2)的大小就行了
代码实现查看代码部分的test函数
3.测试数据
在已经学习了
我们预测一下打喷嚏的建筑工人是生了什么病
console.log(nb.test(["打喷嚏","建筑工人"]));

结果是感冒
预测性别示例:
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 男 | 6 | 165 | 10 |
| 男 | 5.72 | 164 | 9 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
var nb = new NB();
nb.train([6, 180, 12], "男");
nb.train([5.92, 190, 11], "男");
nb.train([5.58, 170, 12], "男");
nb.train([5.72, 164, 9], "男");
nb.train([6, 165, 10], "男");
nb.train([5.92, 165, 10], "男");
nb.train([5, 100, 6], "女");
nb.train([5.5, 150, 8], "女");
nb.train([5.42, 130, 7], "女");
nb.train([5.75, 150, 9], "女");
console.log(nb.test([6, 180, 11]));
中文脏话测试
function defaultTokenizer(text) {
// 仅保留英文、中文、数字
var rgxPunctuation = /[^(a-zA-ZA-Яa-я\u4e00-\u9fa50-9_)+\s]/g;
// 英文以空格分词,中文不分词,以单个字为单位
return text.replace(rgxPunctuation, ' ').replace(/[\u4e00-\u9fa5]/g, function(word) {
return word + ' ';
}).split(/\s+/);
};
// 中文测试
nb.train(defaultTokenizer('我的名字叫司马萌.'), '正常')
nb.train(defaultTokenizer('没什么,就是一道测试程序!!'), '正常')
nb.train(defaultTokenizer('不要皱眉,即使在伤心的时刻,因为你从不知道有谁会醉心于你的笑容。'), '正常')
nb.train(defaultTokenizer('去只是一种姿势,得到并不等同于幸福。'), '正常')
nb.train(defaultTokenizer('理和美女都是赤裸裸的。'), '正常')
nb.train(defaultTokenizer('们看错了这个世界,却说世界欺骗了我们。'), '正常')
nb.train(defaultTokenizer('们人这一辈子不是别人的楷模,就是别人的借鉴。'), '正常')
nb.train(defaultTokenizer('万别说直到永远,因为你压根不知道永远有多远。'), '正常')
nb.train(defaultTokenizer('些无法复制的浪漫,只能在回忆里慢慢变淡。'), '正常')
nb.train(defaultTokenizer('调是永恒的美德,缺心眼的话就要学会沉默。'), '正常')
nb.train(defaultTokenizer('用什么优势赢得人生,就会用同样的原因输掉人生。'), '正常')
nb.train(defaultTokenizer('人最可悲的是,有自由的思想,却没有冲破羁绊的勇气。'), '正常')
nb.train(defaultTokenizer('爱情就像俩个拉着橡皮筋的人,受伤的总是不愿意放手的那一个。'), '正常')
nb.train(defaultTokenizer('人生的经历就像铅笔一样…开始很尖…经历的多了也就变得圆滑了…如果承受不了就会断了。'), '正常')
nb.train(defaultTokenizer('在你往上爬的时候,一定要保持梯子的整洁,否则你下来时可能会滑倒。'), '正常')
nb.train(defaultTokenizer('人生是没有穷尽的,所以也就没有什么所谓的归宿。'), '正常')
nb.train(defaultTokenizer('幸福是因为你看到别人的不幸,不幸是因为你只看到别人的幸福。'), '正常')
nb.train(defaultTokenizer('我们的安全感,来自于充分体验不安全感。'), '正常')
nb.train(defaultTokenizer('男人最大的武器是眼神,女人最大的武器是眼泪。'), '正常')
nb.train(defaultTokenizer('心清如水即是佛,了无牵挂佛无边。'), '正常')
nb.train(defaultTokenizer('人活着为了什么?答案:一个念想。'), '正常')
nb.train(defaultTokenizer('有些事遇见了就无法放手,有些事放开了手就不必再回首。'), '正常')
nb.train(defaultTokenizer('我操,你他妈咋回事!!'), '脏话')
nb.train(defaultTokenizer('你他妈整个脑残了,不惜拿自己的父母家人来骗别人的精液。!!'), '脏话')
nb.train(defaultTokenizer('跟一个你视为他为狗的人将素质,你真心逗B,脑子也秀逗了吧!'), '脏话')
nb.train(defaultTokenizer('贱人的生活方式就是,只许自己吃屎,不许别人放屁。'), '脏话')
nb.train(defaultTokenizer('你爹有点多,我忍不住笑了下,不好意思啊,你不要去想你那悲伤的母亲。'), '脏话')
nb.train(defaultTokenizer('我们骂不骂关你个婊子什么事,草你吗的瞎眼白内胀!'), '脏话')
nb.train(defaultTokenizer('你他妈那么喜欢被人擦,我想说我退出我不喜欢兽交。'), '脏话')
nb.train(defaultTokenizer('我只是你祖宗而已,你怎么可以这样,你个傻逼怎么能把你祖宗都忘记了?'), '脏话')
nb.train(defaultTokenizer('你要是不扒一扒脸皮,我还真不晓得原来你的脸皮如此的厚呢!'), '脏话')
nb.train(defaultTokenizer('对不起哈,当年老子我没忍住,一个屁把这二逼给蹦出来了!'), '脏话')
nb.train(defaultTokenizer('你是脑子有病还是怎么?你以为你是谁?不就是傻逼一个嘛!'), '脏话')
nb.train(defaultTokenizer('整天把逼脸摆给别人看,是想要告诉别人你是黄世仁他妈吗?'), '脏话')
nb.train(defaultTokenizer('你是不是每次拉完屎,然后又自己舔干净了,还到处炫耀自己拉屎很香。'), '脏话')
nb.train(defaultTokenizer('你妈是靠卖逼把你养大的吧,到你这代还能继续卖逼,真的是母业女继承啊。'), '脏话')
nb.train(defaultTokenizer('难道你是吃大姨妈拌饭长大的,怪不得长那么恶心呢!'), '脏话')
nb.train(defaultTokenizer('操你妈,日子那么难过像被人强奸了,但是经典他妈说与其挣扎不如学会享受!'), '脏话')
nb.train(defaultTokenizer('就你那鸟样还整得跟个吉娃娃卖烧烤串似得,重口味卖得都是巨根火腿吧。'), '脏话')
nb.train(defaultTokenizer('你大哥拉破车、一直拉到耗子窝、耗子给你两块糖、你管耗子叫大娘。'), '脏话')
nb.train(defaultTokenizer('就你这样子不好好读书,以后做鸡都没人敢要!'), '脏话')
nb.train(defaultTokenizer('看你这尖嘴猴腮样,长的那么丑还每天学人家自拍,太恶心人了。'), '脏话')
console.log('预期:脏话,实际:', nb.test(defaultTokenizer('我操')));
console.log('预期:正常,实际:', nb.test(defaultTokenizer('还没使用中文分词就分的这么棒')));
console.log('预期:脏话,实际:', nb.test(defaultTokenizer('你大爷的吧'))); // 脏话
console.log('预期:脏话,实际:', nb.test(defaultTokenizer('你丫有病吧'))); // 脏话
console.log('预期:正常,实际:', nb.test(defaultTokenizer('妈妈,我饿了'))); // 正常
console.log('预期:正常,实际:', nb.test(defaultTokenizer('马克思主义')));

英文脏话测试
function defaultTokenizer(text) {
// 仅保留英文、中文、数字
var rgxPunctuation = /[^(a-zA-ZA-Яa-я\u4e00-\u9fa50-9_)+\s]/g;
// 英文以空格分词,中文不分词,以单个字为单位
return text.replace(rgxPunctuation, ' ').replace(/[\u4e00-\u9fa5]/g, function(word) {
return word + ' ';
}).split(/\s+/);
};
// 英文学习
// positive
nb.train(defaultTokenizer('What is your name?'), 'positive');
nb.train(defaultTokenizer('amazing, awesome movie!! Yeah!! Oh boy.'), 'positive');
nb.train(defaultTokenizer('Sweet, this is incredibly, amazing, perfect, great!!'), 'positive');
nb.train(defaultTokenizer('Do one thing at a time, and do well.'), 'positive');
nb.train(defaultTokenizer('Never forget to say “thanks”.'), 'positive');
nb.train(defaultTokenizer('Believe in yourself.'), 'positive');
nb.train(defaultTokenizer('Never put off what you can do today until tomorrow.'), 'positive');
nb.train(defaultTokenizer('Do not aim for success if you want it; just do what you love and believe in, and it will come naturally.'), 'positive');
nb.train(defaultTokenizer('Whatever is worth doing is worth doing well.'), 'positive');
nb.train(defaultTokenizer('Keep on going never give up.'), 'positive');
// foul
nb.train(defaultTokenizer('Get out !Beat it! Get lost!'), 'foul');
nb.train(defaultTokenizer('Go to hell! Go to the devil!'), 'foul');
nb.train(defaultTokenizer('Oh, hell is bells!'), 'foul');
nb.train(defaultTokenizer('You SOB (son of a)!'), 'foul');
nb.train(defaultTokenizer('You damned (disgusting) bastard!'), 'foul');
nb.train(defaultTokenizer('Idiot! You damned fool!'), 'foul');
nb.train(defaultTokenizer('Disgusting!'), 'foul');
nb.train(defaultTokenizer('I will see you in hell first!'), 'foul');
nb.train(defaultTokenizer('FUCK Fuck fuck'), 'foul');
nb.train(defaultTokenizer('You pig!'), 'foul');
nb.train(defaultTokenizer('God damn !'), 'foul');
nb.train(defaultTokenizer('Whore! Slut!'), 'foul');
nb.train(defaultTokenizer('You hypocrite!'), 'foul');
nb.train(defaultTokenizer('You ass licker (kisser)!'), 'foul');
// 判断分类
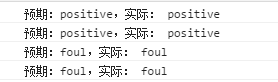
console.log('预期:positive,实际:', nb.test(defaultTokenizer('My name is Surmon.')));
console.log('预期:positive,实际:', nb.test(defaultTokenizer('awesome, cool, amazing!! Yay.')));
console.log('预期:foul,实际:', nb.test(defaultTokenizer('get out!!!')));
console.log('预期:foul,实际:', nb.test(defaultTokenizer('Fuck!')));