制作近10年期间,环保板块市值最高的20只股票动态变化,需要获得各只股票在不同年份的市值。获取特定股票的市值可以利用pro.daily_basic接口获取到每日的市值,然后利用Resample函数获得年均市值。但获取环保板块所有几十只股票的数据,用手动输入股票代码就不是很方便,此时,可以利用该包另外一个接口ts.get_stock_basics()接口获取所有股票基本数据,该接口能够返回股票代码、行业类别等数据。两个接口合二为一就可以提取出所需的数据,下面开始详细实现步骤。
1. 提取所有股票代码
1import tushare as ts
2# 获取所有股票列表
3data = ts.get_stock_basics()
4print(data.head())
5# 返回数据如下,所有列值可以参考:http://tushare.org/fundamental.html
6 name industry area pe outstanding totals totalAssets
7code
8002936 N郑银 银行 河南 8.27 6.00 59.22 44363604.00
9600856 中天能源 供气供热 吉林 21.28 13.43 13.67 1712831.63
10300021 大禹节水 农业综合 甘肃 35.27 6.48 7.97 359294.91
11603111 康尼机电 运输设备 江苏 0.00 7.38 9.93 734670.69
12000498 山东路桥 建筑施工 山东 19.52 4.41 11.20 1926262.38
可以看到,index是股票代码,name股票名称,industry是行业分类。我们需要获取环保类(可以获取任意行业类别,也可以全部获取所有股票,为了后期数据提取量耗时短一些,所以选择提取环保类股票)的股票代码和股票名称,代码如下:
1data = data[data.industry =='环境保护']
2print(data.head()) #返回的环保股数据
3print('环保股股票数量为':len(data.industry)) #计算环保股股票数量
4结果如下:
5 name industry area pe outstanding totals totalAssets
6code
7300056 三维丝 环境保护 福建 0.00 2.37 3.85 266673.63
8002549 凯美特气 环境保护 湖南 34.44 6.20 6.24 122630.13
9300422 博世科 环境保护 广西 19.22 2.64 3.56 509822.44
10601330 绿色动力 环境保护 深圳 59.83 1.16 11.61 784969.25
11000820 神雾节能 环境保护 辽宁 0.00 2.88 6.37 284674.34
12环保股股票数量为: 66
可以看到,环境保护股一共有66只,下面我们将用这66只股票的代码和名称,输入到pro.daily_basic()接口中,获取每只股票的每日数据,其中包括每日市值。时间期限从2009年1月1日至2018年9月10日,共10年的逐日数据。
2. 提股票每日市值
每日基本指标的数据接口:https://tushare.pro/document/2?doc_id=32
1pro = ts.pro_api()
2pro.daily_basic(ts_code='', trade_date='',start_date = '',end_date = '')
3# ts_code是股票代码,格式为000002.SZ,可以为一只股票,也可以是列表组成的多支股票
4# 后面三个是交易日期,可以为固定日期,也可以为一个时期,格式'20180919'
该接口股票代码的格式是000002.SZ,而上面股票代码格式是:000002,没有带后缀.SZ,由此需要添加上,然后就可获取每只股票近10年的逐日市值数据。
1data['code2'] = data.index
2# apply方法添加.SZ后缀
3data['code2'] = data['code2'].apply(lambda i:i+'.SZ')
4data = data.set_index(['code2'])
5# 将code和name转为dict,因为我们只需要表格中的代码和名称列
6data = data['name']
7data = data.to_dict()
8
9# print(data) #测试返回的环保股字典数据 ok
10{'300056.SZ': '三维丝', '002549.SZ': '凯美特气', '300422.SZ': '博世科', '601330.SZ': '绿色动力', '000820.SZ': '神雾节能', '300072.SZ': '三聚环保', '300055.SZ': '万邦达', '002717.SZ': '岭南股份', '300070.SZ': '碧水源', '000504.SZ': '南华生物', '300203.SZ': '聚光科技', '002672.SZ': '东江环保', '000967.SZ': '盈峰环境', '002322.SZ': '理工环科', '300272.SZ': '开能健康', '300495.SZ': '美尚生态', '603717.SZ': '天域生态', '300266.SZ': '兴源环境', '603126.SZ': '中材节能', '002200.SZ': '云投生态', '300385.SZ': '雪浪环境', '603200.SZ': '上海洗霸', '000826.SZ': '启迪桑德', '300262.SZ': '巴安水务', '002887.SZ': '绿茵生态', '603568.SZ': '伟明环保', '300631.SZ': '久吾高科', '002616.SZ': '长青集团', '300156.SZ': '神雾环保', '000920.SZ': '南方汇通', '600008.SZ': '首创股份', '601200.SZ': '上海环境', '603955.SZ': '大千生态', '603177.SZ': '德创环保', '600481.SZ': '双良节能', '300190.SZ': '维尔利', '603588.SZ': '高能环境', '002034.SZ': '旺能环境', '603817.SZ': '海峡环保', '002499.SZ': '科林环保', '603822.SZ': '嘉澳环保', '300664.SZ': '鹏鹞环保', '300332.SZ': '天壕环境', '600526.SZ': '菲达环保', '600874.SZ': '创业环保', '600292.SZ': '远达环保', '603903.SZ': '中持股份', '300172.SZ': '中电环保', '000544.SZ': '中原环保', '300692.SZ': '中环环保', '600388.SZ': '龙净环保', '300425.SZ': '环能科技', '300388.SZ': '国祯环保', '300362.SZ': '天翔环境', '300197.SZ': '铁汉生态', '300187.SZ': '永清环保', '300090.SZ': '盛运环保', '002573.SZ': '清新环境', '000035.SZ': '中国天楹', '603797.SZ': '联泰环保', '603603.SZ': '博天环境', '300137.SZ': '先河环保', '300355.SZ': '蒙草生态', '300152.SZ': '科融环境', '002658.SZ': '雪迪龙', '600217.SZ': '中再资环'}
可以看到,很完整地显示了环保股的股票代码和名称,下面通过for循环即可获取每日数据。为了方便,将上式代码命名为一个函数get_code(),return data 为上面的dict。
3. 提取环保股公司数据
1ts_codes = get_code()
2start = '20090101'
3end = '201809010'
4for key,value in ts_codes.items():
5 data = pro.daily_basic(ts_code=key, start_date=start, end_date=end) # 获取每只股票时间段数据
6 # 添加代码列和名称列
7 # 替换掉末尾的.SZ,regex设置为true才行
8 data['code'] = data['ts_code'].replace('.SZ','',regex = True)
9 data['name'] = value
10 # 存储结果
11 data.to_csv('environment.csv',mode='a',encoding = 'utf_8_sig',index = False,header = 0)
12 print('数据提取完毕')
表格结果如下,66只股票10年一共产生了75933行数据。如果提前全部3000多家股票的数据,那么数据量会达到几百万行,量太大,所以这里仅提取了66支。其中,选中的列为每日市值(万元)。下面就可以根据日期、市值得到各只股票每年的市值均值,然后绘制股票动态表。
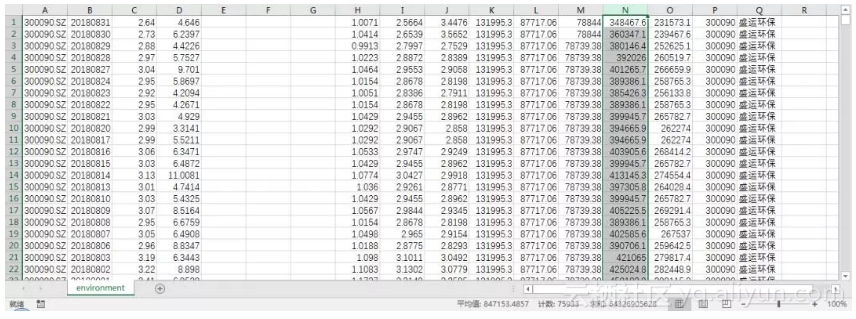
首先读取上面的表格,获取DataFrame信息:
1df = pd.read_csv('environment.csv',encoding = 'utf-8',converters = {'code':str})
2# converters = {'code':str} 将数字前面不显示的0转为str显示
3print(df.info())
4
5Data columns (total 17 columns):
6ts_code 75932 non-null object
7trade_date 75932 non-null int64
8close 75932 non-null float64
9turnover_rate 75932 non-null float64
10volume_ratio 0 non-null float64
11pe 70861 non-null float64
12e_ttm 69254 non-null float64
13pb 73713 non-null float64
14ps 75932 non-null float64
15ps_ttm 75840 non-null float64
16total_share 75932 non-null float64
17float_share 75932 non-null float64
18free_share 75932 non-null float64
19total_mv 75932 non-null float64
20circ_mv 75932 non-null float64
21code 75932 non-null int64
22name 75932 non-null object
23dtypes: float64(13), int64(2), object(2)
可以看到trade_date交易日期是整形,需将交易日期先转换为字符型再转换为datetime日期型。
1from datetime import datetime
2# trade_date是int型,需转为字符型
3df['trade_date'] = df['trade_date'].apply(str)
4# 或者
5# df['trade_date'] = df['trade_date'].astype(str)
6# 将object转为datatime
7df['trade_date'] = pd.to_datetime(df['trade_date'],format = '%Y%m%d',errors = 'ignore') #errors忽略无法转换的数据,不然会报错
8# 结果如下:
9Data columns (total 17 columns):
10ts_code 75932 non-null object
11trade_date 75932 non-null datetime64[ns]
12close 75932 non-null float64
13turnover_rate 75932 non-null float64
14volume_ratio 0 non-null float64
15pe 70861 non-null float64
16e_ttm 69254 non-null float64
17pb 73713 non-null float64
18ps 75932 non-null float64
19ps_ttm 75840 non-null float64
20total_share 75932 non-null float64
21float_share 75932 non-null float64
22free_share 75932 non-null float64
23total_mv 75932 non-null float64
24circ_mv 75932 non-null float64
25code 75932 non-null int64
26name 75932 non-null object
接着再将市值格式改变为亿元。
1# 设置总市值数字格式由万元变为亿元
2df['total_mv'] = (df['total_mv']/10000)
3# 保留四列,并将交易日期设为index
4df = df[['ts_code','trade_date','total_mv','name']]
5df = df.set_index('trade_date')
6print(df.head())
7# 结果如下:
8 ts_code total_mv name
9trade_date
102018-08-30 300090.SZ 36.034715 盛运环保
112018-08-29 300090.SZ 38.014644 盛运环保
122018-08-28 300090.SZ 39.202602 盛运环保
132018-08-27 300090.SZ 40.126569 盛运环保
142018-08-24 300090.SZ 38.938611 盛运环保
接下来,求出每只股票每年的市值平均值:
1# 求平均市值时需切片同一股票,这里股票名称切片赋值为value变量,也就是dict字典里66只股票名称
2df = df[df.name == value]
3# 不能用query方法,会报错 df = df.query('name == value')
4# resampe按年统计数据
5df = df.resample('AS').mean() #年平均市值
6print(df.head())
7# 结果如下:
8 total_mv code
9trade_date
102009-01-01 25.184678 三维丝
112010-01-01 50.672849 三维丝
122011-01-01 46.488004 三维丝
132012-01-01 39.214508 三维丝
142013-01-01 59.110332 三维丝
15# 再用to_period按年显示市值数据
16df = df.to_period('A')
17print(df.head())
18# 结果如下:
19 total_mv code
20trade_date
212009 25.184678 三维丝
222010 50.672849 三维丝
232011 46.488004 三维丝
242012 39.214508 三维丝
252013 59.110332 三维丝
经过以上处理,基本就获得了想要的数据。为了能够满足D3.js模板表格条件,再做一点修改:
1# 增加code列
2df['code'] = value
3# 重置index
4df = df.reset_index()
5# 重命名为d3.js格式
6# 增加一列空type
7df['type'] = ''
8df = df[['code','type','total_mv','trade_date']]
9df.rename(columns = {'code':'name','total_mv':'value','type':'type','trade_date':'date'})
10# df.to_csv('parse_environment.csv',mode='a',encoding = 'utf_8_sig',index = False,float_format = '%.1f',header = 0) # float_format = '%.1f' #设置输出浮点数格式为1位小数
最终,生成parse_environment.csv文件如下:
1name type value date
2中国天楹 8.8 2009
3中国天楹 9.8 2010
4中国天楹 15 2011
5中国天楹 18.8 2012
6中国天楹 22.5 2013
7...
8东方园林 177.1 2014
9东方园林 320.5 2015
10东方园林 288.4 2016
11东方园林 481 2017
12东方园林 461.5 2018
可绘制出动态可视化表格,见下面视频。可以看到前几年市值龙头由东方园林、碧桂园轮流坐庄,近两年三聚环保强势崛起,市值增长迅猛,跃居头名。
本文仅对比了环保股企业的市值变化,你还可以分析互联网股、金融股等100多种行业的企业市值对比。另外,Tushare包返回的参数还可以做更多其他分析。
文章完整的代码如下:
1import pandas as pd
2import tushare as ts
3from datetime import datetime
4import matplotlib.pyplot as plt
5ts.set_token('404ba015bd44c01cf09c8183dcd89bb9b25749057ff72b5f8671b9e6')
6pro = ts.pro_api()
7def get_code():
8 # 所有股票列表
9 data = ts.get_stock_basics()
10 # data = data.query('industry == "环境保护"')
11 # 或者
12 data = data[data.industry =='环境保护']
13 # 提取股票代码code并转化为list
14 data['code2'] = data.index
15 # apply方法添加.SZ后缀
16 data['code2'] = data['code2'].apply(lambda i:i+'.SZ')
17 data = data.set_index(['code2'])
18 # 将code和name转为dict
19 data = data['name']
20 data = data.to_dict()
21 # 增加东方园林
22 data['002310.SZ'] = '东方园林'
23 # print(data) #测试返回的环保股dict ok
24 return data
25
26def stock(key,start,end,value):
27 data = pro.daily_basic(ts_code=key, start_date=start, end_date=end) # 获取每只股票时间段数据
28
29 # 替换掉末尾的.SZ,regex设置为true才行
30 data['code'] = data['ts_code'].replace('.SZ','',regex = True)
31 data['name'] = value
32 # print(data)
33 data.to_csv('environment.csv',mode='a',encoding = 'utf_8_sig',index = False,header = 0)
34
35def parse_code():
36 df = pd.read_csv('environment.csv',encoding = 'utf-8',converters = {'code':str})
37 # converters = {'code':str} 将数字前面不显示的0转为str显示
38 df.columns = ['ts_code','trade_date','close','turnover_rate','volume_ratio','pe','e_ttm','pb','ps','ps_ttm','total_share','float_share','free_share','total_mv','circ_mv', 'code','name']
39 # trade_date是int型,需转为字符型
40 df['trade_date'] = df['trade_date'].apply(str)
41 # 或者df['trade_date'] = df['trade_date'].astype(str)
42 # 将object转为datatime
43 df['trade_date'] = pd.to_datetime(df['trade_date'],format = '%Y%m%d',errors = 'ignore') #errors忽略无法转换的数据,不然会报错
44 ## 设置总市值数字格式由万元变为亿元
45 df['total_mv'] = (df['total_mv']/10000)
46 # 保留四列,并将交易日期设为index
47 df = df[['ts_code','trade_date','total_mv','name']]
48 df = df.set_index('trade_date')
49
50 df = df[df.name == value]
51 # # 不能用query方法
52 # # df = df.query('name == ')
53 df = df.resample('AS').mean()/10000 #年平均市值
54 df = df.to_period('A')
55 # # 增加code列
56 df['code'] = value
57 # # 重置index
58 df = df.reset_index()
59
60 # 重命名为d3.js格式
61 # 增加一列空type
62 df['type'] = ''
63 df = df[['code','type','total_mv','trade_date']]
64 df.rename(columns = {'code':'name','total_mv':'value','type':'type','trade_date':'date'})
65 df.to_csv('parse_environment.csv',mode='a',encoding = 'utf_8_sig',index = False,float_format = '%.1f',header = 0)
66 float_format = '%.1f' #设置输出浮点数格式
67 # print(df)
68 # print(df.info())
69
70def main():
71 # get_code() #提取环保股dict
72 start = '20090101'
73 end = '201809010'
74 ts_codes = get_code()
75 # dict_values转list
76 keys = list(ts_codes.keys())
77 values = list(ts_codes.values())
78 for key,value in ts_codes.items():
79 stock(key,start,end,value)
80 for value in values:
81 parse_code(value)
82
83if __name__ == '__main__':
84 main()
Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
原文发布时间为:2018-10-25
本文作者:苏克1900
本文来自云栖社区合作伙伴“Python中文社区”,了解相关信息可以关注“Python中文社区”。

