大多的开源图片框架针对图片加载都采用了三级缓存的方式,大概流程通常是这样的,加载图片时,首先检查内存中是否仍然保有这个图片对象,如果有则直接显示到控件上,加载过程到此结束;如果内存中没有,则可能是第一次加载,还没有缓存或者内存中的缓存被销毁,这时候去本地缓存中读取,通常是写入到了文件中,如果文件中读取到了缓存,则设置给控件显示,加载结束,如果没有缓存,则再请求服务器返回,这时候会将获取到的图片写入到本地硬盘(文件)中,(或者同时在内存中也写入一份),同时设置给图片显示。这时第一次加载结束,下次再次加载时,重复上一个过程,只要存在缓存就不再请求网络,降低不必要的网络请求。如下图
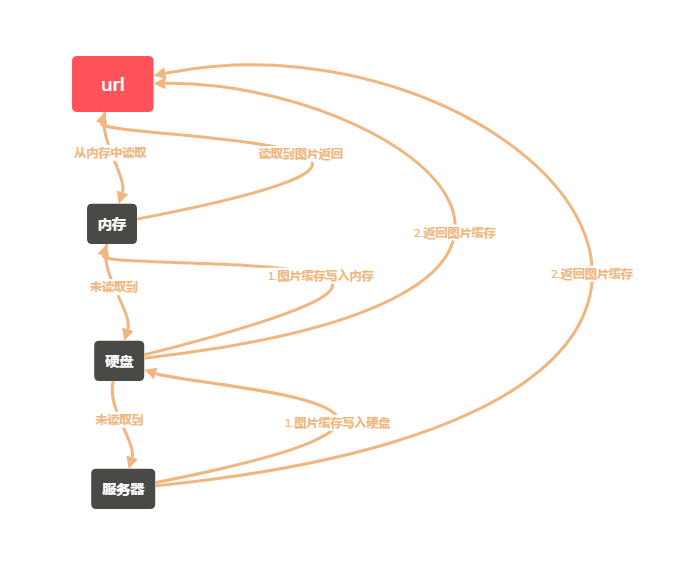
简易版的三级缓存框架: https://github.com/renzhenming/BitmapUtils
内存缓存是如何实现的,我们当然可以用一个HashMap来存储获取到的bitmap,以url的md5值为key来保存,但是有一个问题需要注意,安卓系统为每一个应用分配的内存都是有限的,使用HashMap固然可以实现功能,但是当图片足够多的时候,HashMap无法为你清理内存,极有可能发生内存溢出。
为了防止这种问题,可以在把bitmap加如到集合中时,使用软引用,弱引用,虚引用等包裹bitmap,这样可以防止内存溢出,及时的清理bitmap,但有一个问题,这样内存缓存的作用就不存在了,我们的目的是做缓存,但从 Android 2.3 (API Level 9)开始,垃圾回收器会更倾向于回收持有软引用或弱引用的对象,软引用和弱引用已经不再可靠了,试想如果你刚刚加入缓存就被系统清理了,达不到我们想要的效果,所以Android系统提供了一个可靠的缓存集合LruCache,LruCache内部封装了一个LinkedHashMap集合,所以也可以把它当作集合来看待
long maxMemory = Runtime.getRuntime().maxMemory();//获取Dalvik 虚拟机最大的内存大小:16
LruCache<String, Bitmap> lruCache = new LruCache<String,Bitmap>((int) (maxMemory/8)){//指定内存缓存集合的大小
//获取图片的大小
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight();
}
};
LruCache创建的时候通过泛型指定map集合的key和value类型,并且通过构造方法传入设定的内存缓存集合的最大值,我们来看看它的构造方法,可以看到,这里保存了内存的最大占用空间,并且创建了一个LinkedHashMap,相比于HashMap,保证有序性
/**
* @param maxSize for caches that do not override {@link #sizeOf}, this is
* the maximum number of entries in the cache. For all other caches,
* this is the maximum sum of the sizes of the entries in this cache.
*/
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
当网LruCache中添加内容的时候,进入put方法
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
//每加如一个缓存对象,缓存计数器增加1
putCount++;
//计算出当前缓存的大小值,safeSizeOf就是上边重写的sizeOf
//方法的封装,得到的是当前加如的缓存对象的大小,然后累加得到总大小
size += safeSizeOf(key, value);
//如果缓存中存在相同的对象,总的缓存大小减去当前这个存入的大小
//也就是重复的缓存对象不计入缓存,map集合在put的时候,如果集合中存在的
//话会用新的value值替换旧的value,不存在重复value的情况,
//所以只需要将总值减去即可,不需要再从集合中移除
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
//这个方法没有做什么东西,估计是提供出来让重写的
if (previous != null) {
entryRemoved(false, key, previous, value);
}
//这里是控制内存的算法所在关键
trimToSize(maxSize);
return previous;
}
trimToSize
每次向LruCache中添加新的对象缓存时,都会检查一次当前缓存大小是否超过了设置的最大值,这是一个死循环,只要占用的空间大小极值,就会一直根据lru算法来得到最符合移除条件的一个对象然后移除它,直到内存大小在合理范围内
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//如果当前缓存大小没有超过设置的最大值,就返回
if (size <= maxSize) {
break;
}
//根据lru算法(Least recently used,最近最少使用)得到一个entry
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
//从集合中移除这个对象,并且更新当前缓存大小
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
看到这里可以知道,其实LruCache的关键在于LinkedHashMap内部是如何运转的,它会根据lru算法,获取到最符合移除条件的一个对象,eldest()方法返回的就是我们需要的值,那么究竟是如何判断的呢,只有进入源码去看一下了
在LruCache实例化的时候,我们看到LinkedHashMap是这样构建的,关键在于最后一个true的标记,这个值代表什么?
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
LinkedHashMap有五种构造方法,前四个构造方法都将accessOrder设为false,默认是按照插入顺序排序的;而第五个构造方法可以自定义传入的accessOrder的值,因此可以指定双向循环链表中元素的排序规则。特别地,当我们要用LinkedHashMap实现LRU算法时,就需要调用该构造方法并将accessOrder置为true。本质上,LinkedHashMap = HashMap + 双向链表,可以这样理解,LinkedHashMap 在不对HashMap做任何改变的基础上,给HashMap的任意两个节点间加了两条连线(before指针和after指针),使这些节点形成一个双向链表。在LinkedHashMapMap中,所有put进来的Entry都保存在HashMap中,并且对于每次put进来Entry还会将其插入到双向链表的尾部。
我们看看设置为true或者false,链表的存取有什么区别,找到put方法,LinkedHashMap的put方法使用的是父类HashMap的put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true)
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//这里可以看到,当存在相同的key时,会将新的value替换旧的value,并将旧的返回
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//走到了这个方法,但其实这个方法在HashMap中是空的,LinkedHashMap重写了这个
//方法,我们看看它是如何实现
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
可以看到,LinkedHashMap调用put方法添加数据的时候,除了继承了HashMap把数据添加到hash表中,还做了另一步操作,就是同时加入了它内部的一个双向链表中,并且是加入了尾部,如果是第一个加如得数据自然也就是头部了,那么这时差不多明白了,LinkedHashMap方法得eldest方法返回得值怎么就是最近最少使用得呢
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMapEntry<K,V> last;
//这里是构造LinkedHashMap时传入的标记位,只有为true的情况才会加如链表,
//也就是说只有第五种构造方法被调用并且accessOrder 赋值为true,链表才会起作用
//同时判断一个条件,当前要加如链表的value和当前链表中最后一个value是否相同
//只有不同的情况才会将其加入
if (accessOrder && (last = tail) != e) {
//注意这种结构,p b a都是LinkedHashMapEntry类型,这一行代码写的很简洁
//第一,将e强转为LinkedHashMapEntry p,第二将p在链表中的位置放在b的后边
//(b = p.before),将p的后边指定为a,这里可以猜想b就是上一次放入链表中的
//LinkedHashMapEntry
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
上边是存入得时候,那么取出得时候呢
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
所以可以发现,LinkedHashMap存取数据都会调用afterNodeAccess方法,将最近使用得value放在链表得末尾,那么这样一来就很清楚了,使用最多得一直放在链表得末尾,使用最少得自然就放在头部了,那么eldest方法返回得head自然也就是最满足移除条件得最少使用得value了。
LinkedHashMap重写了HashMap中的afterNodeAccess方法(HashMap中该方法为空),当调用父类的put方法时,在发现key已经存在时,会调用该方法;当调用自己的get方法时,也会调用到该方法。该方法提供了LRU算法的实现,它将最近使用的Entry放到双向循环链表的尾部。也就是说,当accessOrder为true时,get方法和put方法都会调用recordAccess方法使得最近使用的Entry移到双向链表的末尾。
此时可以回到最初得位置了,LruCache中通过这一行代码取得要移除得对象,从而保证将内存控制在合理范围内。最根本的实现在于LinkedHashMap。
Map.Entry<K, V> toEvict = map.eldest();

