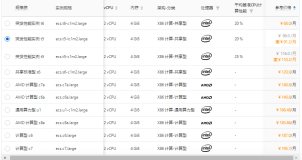
基础装备:
Linux云服务器(阿里云Ubuntu 16.04);
建立远程连接的软件(这里用的是XShell);
友情链接:
Scrapy入门教程:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html
Scrapy-Github地址:https://github.com/scrapy/scrapy
XShell官网下载:http://www.netsarang.com/xshell_download.html
XShell百度下载:http://rj.baidu.com/soft/detail/15201.html?ald
ubuntu常用命令:http://www.jianshu.com/p/1340bb38e4aa
tips: 连接到云服务器之后请先更新操作系统!!!
----------------------------------看完觉着有用的话帮忙点个赞哦~-----------------------------------------
目录
- Ubuntu 16.04云服务器下Scrapy的配置
- 使用ssh方法连接到服务器
- 查看python版本
- 用pip安装virtualenv
- 创建虚拟环境
- pip安装twisted
- 其他相关软件包安装
- 安装cryptography
- 安装scrapy
- Scrapy抓取网页源码
- 找到spiders文件夹
- 本地编写spiders文件并上传
- 执行文件
- Scrapy抓取多页数据
- 本地编写spiders文件
- 上传并执行文件
- Scrapy抓取指定数据
- 本地编写spiders文件
- 上传并执行文件
- 总结
Ubuntu 16.04云服务器下Scrapy的配置
使用ssh方法连接到云服务器
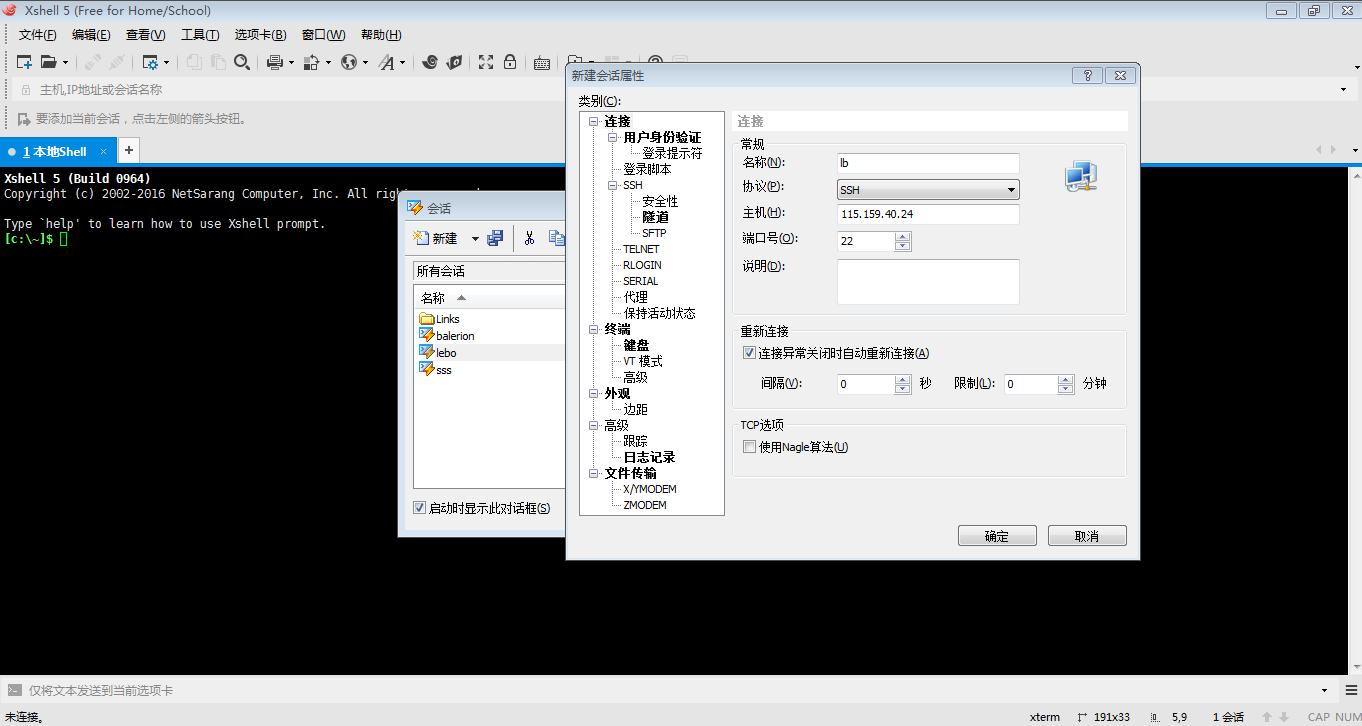
新建-->输入主机IP-->确定-->输入用户名和密码-->连接成功-->进入打算安装scrapy的文件夹
如果不知道怎样创建新用户和进入文件夹的请移步到 Ubuntu常用命令整理
友情链接: xshell登陆详解--腾讯云服务器+Ubuntu+Scrapy抓取网页数据
注意:xshell输入密码会有对话框弹出;在linux系统中输入密码不会有显示,输入完后Enter即可。
查看python版本

python --version
--version用于查看版本
用pip安装virtualenv
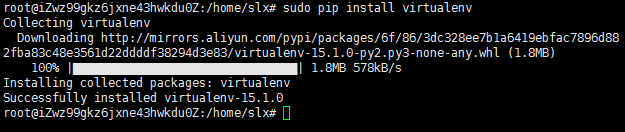
sudo pip install virtualenv
virtualenv --version
sudo命令必须在root权限用户或者被赋予sudo权限的用户执行;
给普通用户赋sudo权限
usermod -aG sudo username
virtualenv 简介
virtualenv 是一个创建隔绝的Python环境的工具。virtualenv创建一个包含所有必要的可执行文件的文件夹,用来使用Python工程所需的包。
相关链接:
http://python-guide-pt-br.readthedocs.io/en/latest/dev/virtualenvs/
https://docs.python.org/3/library/venv.html
创建 venv 虚拟环境

virtualenv venv
cd venv
ls
source bin/activate
virtualenv venv 将会在当前的目录中创建一个文件夹,包含了Python可执行文件,以及 pip 库的一份拷贝,这样就能安装其他包了。虚拟环境的名字(此例中是 venv )可以是任意的;若省略名字将会把文件均放在当前目录。
其中,cd命令用于进入指定目录;ls用于查看当前目录;
source bin/activate用于激活venv, 每次要开始使用虚拟环境之前都需要激活。
激活后,当前虚拟环境的名字会显示在提示符左侧(比如说 (venv)你的电脑:你的工程 用户名$)以显示它是激活的。从现在起,任何使用pip安装的包将会放在 ``venv 文件夹中,与全局安装的Python隔绝开。
pip安装twisted
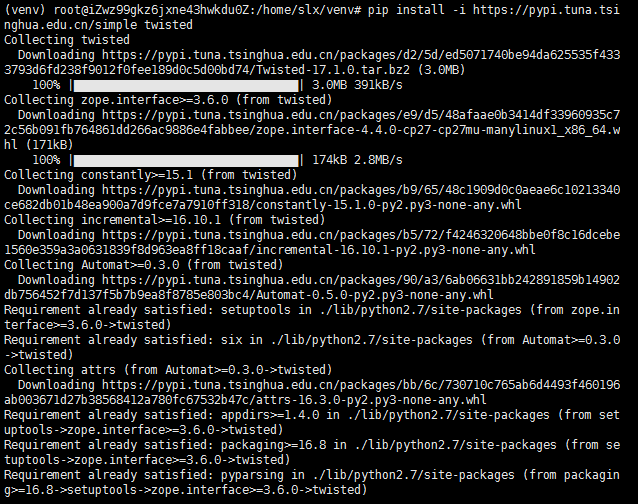
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple twisted
Twisted是一个python编写的事件驱动网络引擎。支持许多常见的网络协议,包括SMTP,POP3,IMAP,SSHv2和DNS。
如果Twisted版本过高,要降包适配。
相关链接:
pip常用命令总结:http://blog.csdn.net/ezreal_king/article/details/61474541
twisted官网:https://twistedmatrix.com/trac/
twisted-gitbook:https://www.gitbook.com/book/likebeta/twisted-intro-cn/details
其它相关软件包安装
sudo apt-get install build-essential libssl-dev libffi-dev python-dev
这里由于忘记sudo apt-get update,出了一点点小问题..

所以千万要记得经常给服务器update!!!
软件包介绍:
build-essential: Informational list of build-essential packages
libssl-dev:是OpenSSL项目实施SSL和TLS加密协议的一部分,用于通过Internet进行安全通信。
libffi-dev:外部函数接口库(开发文件)
python-dev:头文件和Python的静态库(默认)
相关链接:
libffi介绍:https://sourceware.org/libffi/
安装cryptography
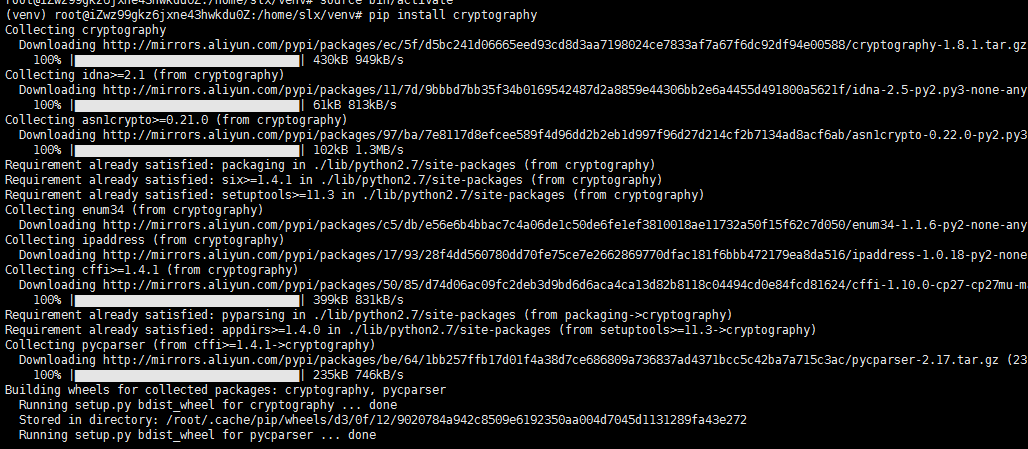
pip install cryptography
cryptography[加密]是一种为Python开发人员提供加密配方和原语的软件包。
cryptography includes both high level recipes, and low level interfaces to common cryptographic algorithms such as symmetric ciphers, message digests and key derivation functions.
来源:https://pypi.python.org/pypi/cryptography
相关链接:
cryptography开发文档:https://cryptography.io/en/latest/
安装scrapy

pip install scrapy
scrapy --version
scrapy startproject quotes(工程名)
到这里,scrapy已经成功安装在了我们的Ubuntu云服务器上。
接下来,就可以开始写代码进行数据爬取了。
Scrapy抓取网页源码
------------------------------------以抓取quotes网站的名人名言为例------------------------
找到spiders文件夹
这里如果中断了之前的连接,需要重新激活
激活并进入虚拟环境

cd /home/slx/venv //进入venv虚拟环境的目录
source bin/activate //激活
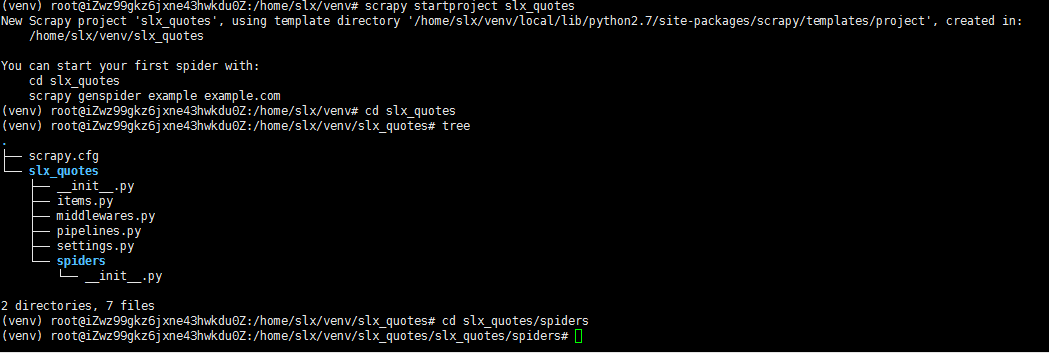
cd slx_quotes //进入venv下新建工程的目录
tree //查看当前目录
(如果没有安装tree,输入命令sudo apt-get install tree进行安装)
cd slx_quotes/spiders //进入spiders目录下
目录分析:
scrapy.cfg/
slx_quotes/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
- scrapy.cfg:项目配置文件
- slx_quotes/:该项目的python模块,之后在这里加入代码
- slx_quotes/items.py:项目中的item文件
- slx_quotes/middlewares.py:spider中间件文件
- slx_quotes/pipelines.py:项目管道组件文件
- slx_quotes/settings.py:项目的设置文件
- slx_quotes/spiders/:放置spider代码的目录
本地编写spider代码并上传
import scrapy
class QuotesSpider(scrapy.Spider):
name = "slx_quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1',
'http://quotes.toscrape.com/page/2',
]
for url in urls:
yield scrapy.Request(url = url, callback = self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'slx-quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
- 三个属性:
- name: 用于区别不同的spider.必须是唯一的,不能为不同的spider设定相同的名字。
- start_urls:包含了Spider在启动时进行爬取的url列表。
- parse() :是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
page通过response.url取到了页码数;
filename是保存的文件名;
self.log在控制台打印出日志信息,显示文件名。
- %s介绍:
python字符串格式化符号:
符 号 描述
%c 格式化字符及其ASCII码
%s 格式化字符串
%d 格式化整数
%u 格式化无符号整型
%o 格式化无符号八进制数
%x 格式化无符号十六进制数
%X 格式化无符号十六进制数(大写)
%f 格式化浮点数字,可指定小数点后的精度
%e 用科学计数法格式化浮点数
%E 作用同%e,用科学计数法格式化浮点数
%g %f和%e的简写
%G %f 和 %E 的简写
%p 用十六进制数格式化变量的地址
来源:http://www.runoob.com/python/python-strings.html
参考:http://www.cnblogs.com/wilber2013/p/4641616.html
把写好的py文件拖进spiders目录下
执行文件
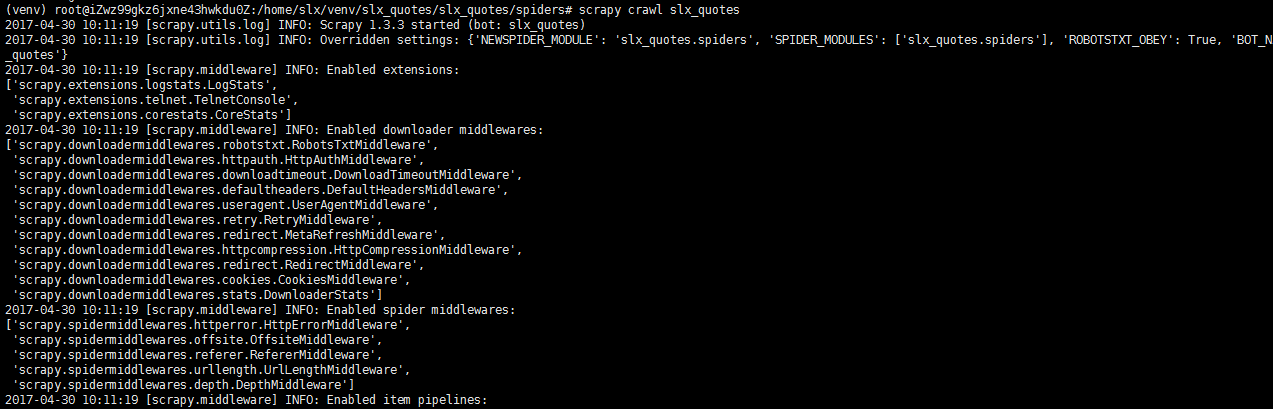
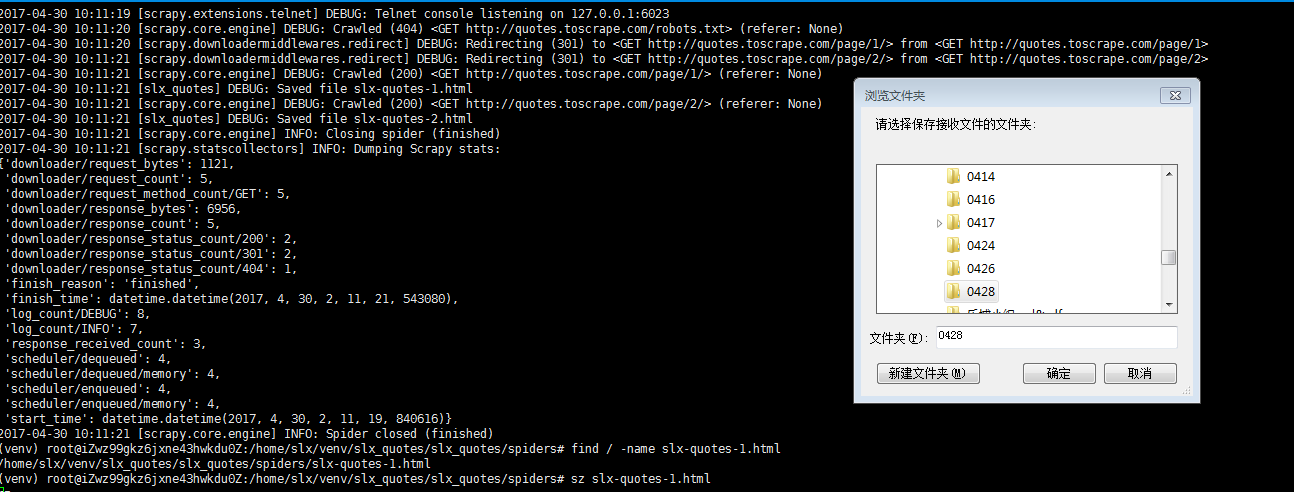
scrapy crawl slx_quotes
find / -name slx-quotes-1.html
sz
执行爬虫后,我们得到了html文件,找到它并且保存到本地(这里我用的lrzsz方法执行sz命令进行保存)
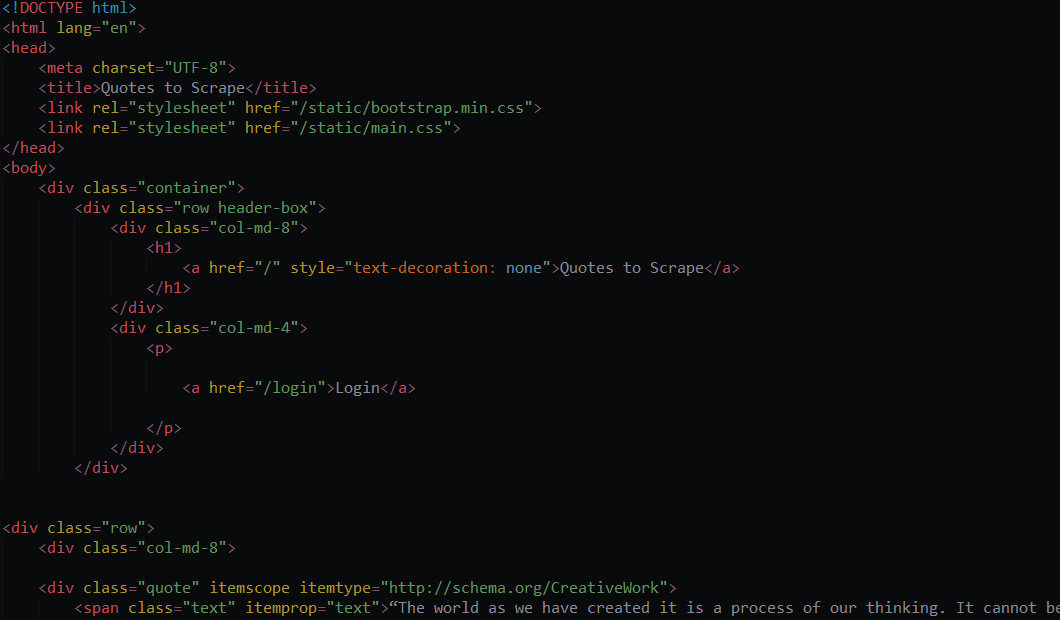
得到html文件
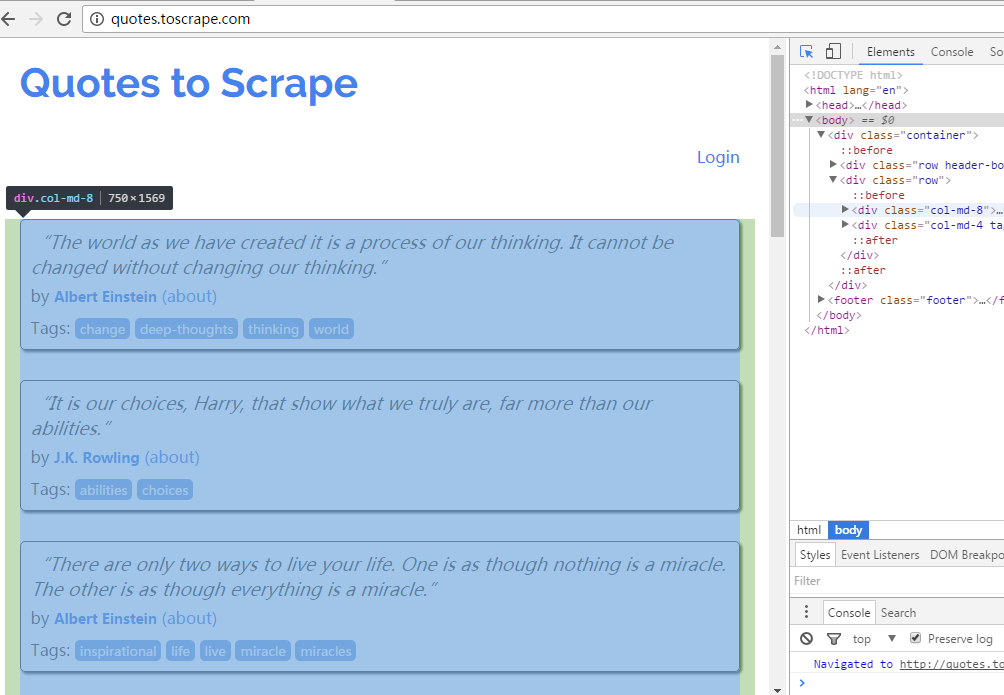
我们也可以用chrome的开发者工具分析网页的格式
---------------这里是MobaXterm上传下载及查找文件的方法-----
如果找不到home文件夹的话,它可能藏在这里了...
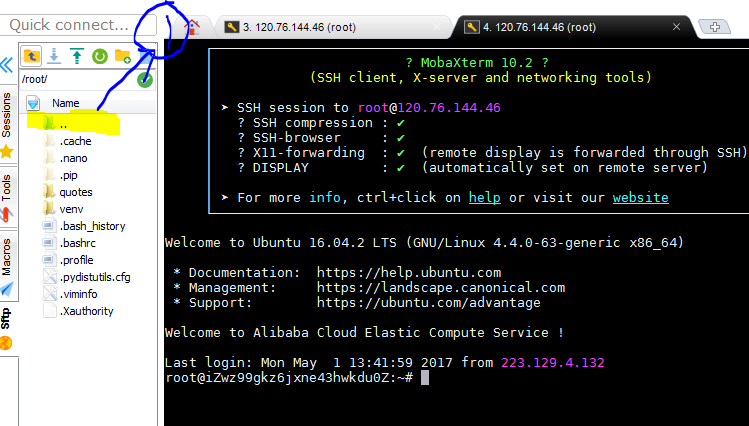
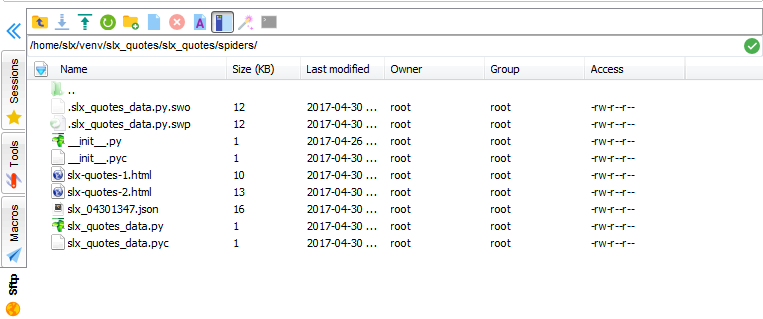
左上角有上传下载的按钮,点击即可。也可以把文件直接拖进来。
标题从左到右:文件名;大小;最后一次修改时间;所有者;所属组;权限
如果遇到了Permission denied,可能是由于权限不够, 修改文件权限方法
Scrapy爬取多页Json数据
本地编写Spiders文件
import scrapy
class QuotesSpider(scrapy.Spider):
name = "slx_quotes_spider"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author':quote.css('small.author::text').extract_first(),
'tags':quote.css('div.tags a.tag::text').extract(),
}
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page,callback = self.parse)
(如果遇到not found或者unexpected indent,可能是空格或缩进有问题。这里的代码缩进我又进行了对照完善,现在的缩进是没有问题的,可以对照检查缩进)
上传文件并执行
具体操作方法和之前一样;
这次把爬取的数据保存为json文件
scrapy crawl slx_quotes_spider -o slx_05011447.json
第一个参数与代码中name相同;name在每个爬虫中都是唯一标识的;不同的爬虫应该取不同的name.
第二个参数是你想要保存的json文件名
Scrapy抓取指定数据
本地编写spiders文件
import scrapy
class QuotesSpider(scrapy.Spider):
name = "tag_ys"
start_urls = [
'http://quotes.toscrape.com',
]
def parse(self, response):
for href in response.css('span.tag-item a::attr(href)'):
url =response.urljoin(href.extract())
print href.extract()
yield scrapy.Request(url, callback=self.parse1)
def parse1(self, response):
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author':quote.css('small.author::text').extract_first(),
'tags':quote.css('div.tags a.tag::text').extract(),
}
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page,callback = self.parse1)
这段代码主要是用于爬取quotes.toscrape.com网页中热门标签下的名人名言,通过抓取当前页面的热门标签的url地址,链接到对应的页面再次进行数据抓取。
上传并执行文件
scrapy crawl tag_ys -o tag_ys.json
抓取json数据结果如下:
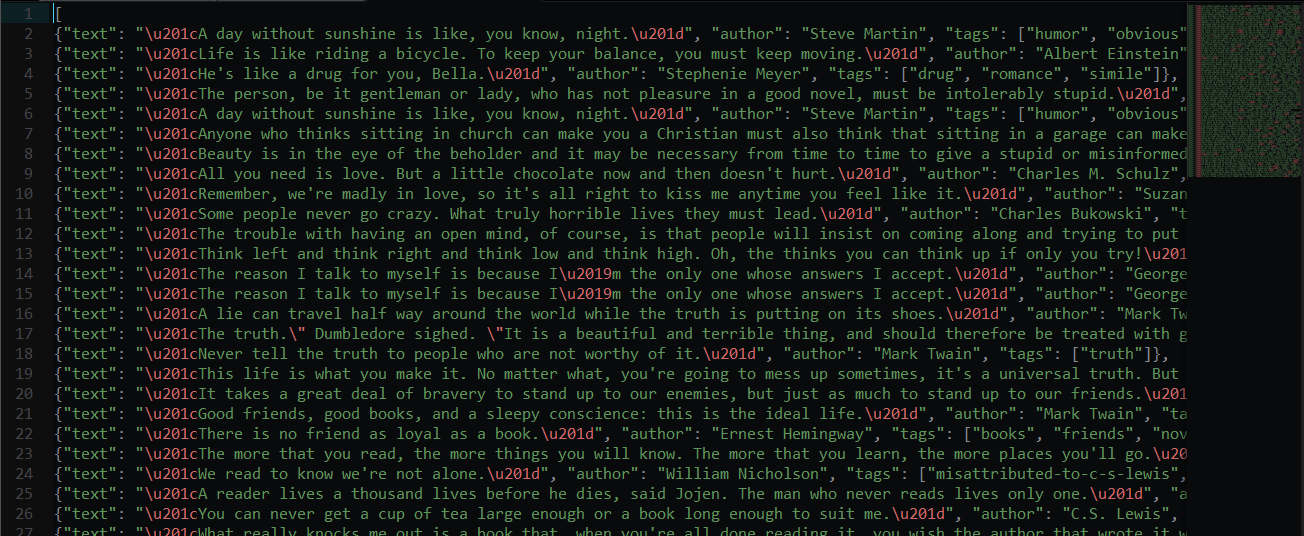
如果需要xml数据,可用json转xml在线工具进行转换
当然,也可以自己用java造轮子自行转换
总结
通过几天的学习与整理,我对scrapy框架有了更深刻的理解和认识,也在scrapy安装过程中巩固了ubuntu基础知识。在学习的过程中,通过发现问题与解决问题,逐渐完善自己的知识体系。
主要用到的知识点有:
- Ubuntu基础知识;
- python基础知识;
- scrapy基础;
- css选择器;
- xpath选择器;
- 正则表达式