目录:
- robots.txt简介
- 亚马逊--robots.txt分析
- Github--robots.txt分析
- 总结
robots.txt简介
介绍
robots.txt(统一小写)文件位于网站的根目录下,是ASCII编码的文本文件,用于表明不希望搜索引擎抓取工具访问的内容。
robots.txt基本语法
- User-agent(用户代理)是指网页抓取工具软件
- Disallow 是针对用户代理的命令,指示不要访问某个特定网址
- Allow 是允许访问的特定网址,多用于给已禁止访问的父级目录的子目录设置允许访问
- 用正则表达式进行路由匹配
Web Robots Database中列出了大多数用户代理 - Sitemap:指示站点地图位置
robots.txt的限制范围
- robots.txt命令仅仅只是指令,不能强制屏蔽抓取
- robots.txt指令不能阻止其他网站引用网址
原则
1、搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
作用
爬虫通过爬取网站并索引网页,并随后通过关键字搜索为网站带来流量。然而,我们只希望爬虫抓取的是最有价值的网页,不希望它们访问不重要的信息或私密的、不适于公开的信息和数据。
robots.txt可用于搜索引擎优化。
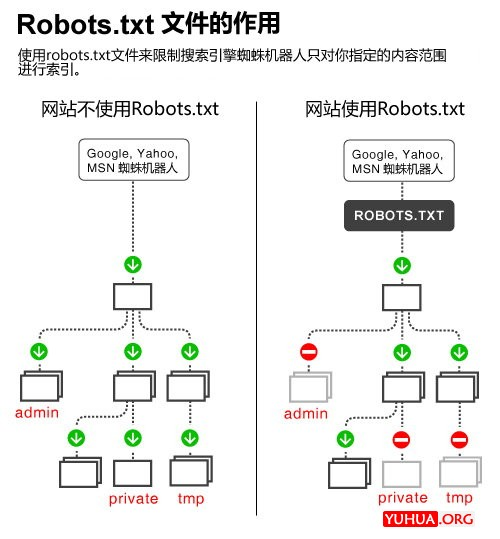
来源: 完全指南:如何写好WordPress博客的robots.txt文件
亚马逊--robots.txt分析
User-agent:
美国亚马逊:www.amazon.com/robots.txt
- *屏蔽全部爬虫的指令
- Googlebot
- Googlebot 是Google 的网页抓取漫游器(有时称为“蜘蛛程序”)。 抓取是指Googlebot 找出要添加到Google 索引中的新网页和更新过的网页的过程。 我们使用大量计算机来提取(或“抓取”)网络上的大量网页。
- 与*屏蔽内容相似
- EtaoSpider
- 阿里巴巴旗下一淘网比价网垂直抓取系统
- 指令屏蔽全部爬虫
中国亚马逊:www.amazon.cn/robots.txt
User-agent:*
没有屏蔽谷歌和一淘爬虫的指令
disallow内容分析(仅摘录了我能看懂的部分):
登录页面
加入购物车
心愿单
评论常见问题
投票
好友
twitter
历史记录
图片
音视频文件
死链接
robots元数据
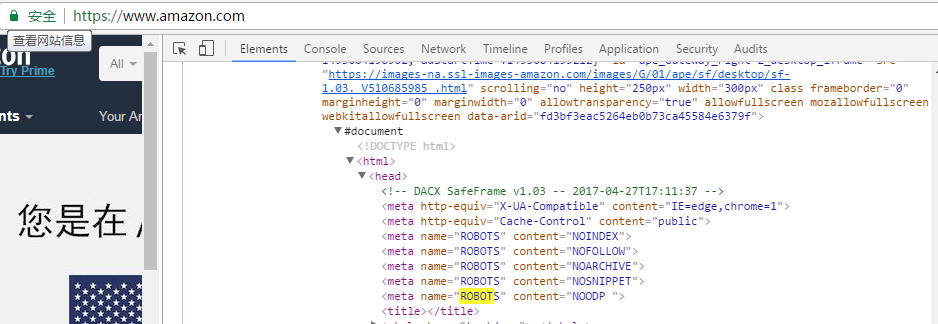
NOINDEX指令:定义了此网页不被搜索引擎索引进数据库,但是搜索引擎可以通过此网页的链接继续索引其它网页
NOFOLLOW指令:不索引这个页面,以及这个页面的链出页面。只适用于此页面上的链接
小结
亚马逊的屏蔽命令主要包括四个部分:客户个人隐私信息、商业数据、耗费大量带宽的数据和死链接。
商家有义务保护用户的个人信息和隐私不被侵犯。商业数据又包括用户的浏览信息、购买信息、反馈信息等可以带来商业价值的大数据。耗费大量带宽的数据如图片、音视频文件等,屏蔽后可以节省服务器带宽。
其中,美国亚马逊还屏蔽了谷歌爬虫和一淘网爬虫的抓取。一淘比价网的抓取可能会影响到亚马逊的商品销量。
Allow部分的指令主要是为了方便爬虫抓取,以便为亚马逊带来客户和流量。
Github--robots.txt分析
User-agent:
CCBot
coccoc---越南的免费网页浏览器
Daumoa---
dotbot
duckduckbot
EtaoSpider
Googlebot---谷歌爬虫,搜索网站
HTTrack
ia_archiver
IntuitGSACrawler
Mail.RU_Bot---邮件爬虫
msnbot---msn爬虫,社交网站
Bingbot---必应爬虫,搜索网站
naverbot
red-app-gsa-p-one
rogerbot
SandDollar
seznambot
Slurp
Swiftbot---Swift爬虫
Telefonica
teoma
Twitterbot---推特爬虫,社交网站
Yandex
disallow内容分析(仅摘录了我能看懂的部分):
/*/*/tree/master //代码的master主分支
/*/stars //获得的star
/*/download //链接中需要下载的内容
/*/*/commits/*/* //评论
/*/*/search //内嵌搜索
/*/cache/ //缓存
/.git/ //git仓库
/login //用户登录
小结
Github屏蔽的用户代理有很多,主要目的还是以保护用户的个人隐私和知识产权不被侵犯。
总结
通过对以上两个网站分析可以看出,robots.txt协议的主要目的是为了进行搜索引擎优化。一方面允许爬虫为网页带来流量和客户,另一方面努力维护用户和商家的隐私和利益不受侵犯。
尽管robots.txt并不能完全防止自己的网页内容被爬取,但是,为自己的网站设置robots.txt依然是很有必要的。
参考链接:
Baidu baike: http://baike.baidu.com/item/robots%E5%8D%8F%E8%AE%AE/2483797?fromtitle=robots.txt&fromid=9518761
Google support:https://support.google.com/webmasters/answer/6062596?hl=zh-Hans&ref_topic=6061961
seobook: http://tools.seobook.com/robots-txt/
完全指南:如何写好WordPress博客的robots.txt文件