实验对象:四川大学公共管理学院官网--新闻动态页
实验目的:运用Scrapy框架进行实际信息的采集以巩固和提高信息检索能力
实验过程:分析采集实体->确定采集方法->制定爬取规则->编写代码并调试->得到数据
---------------------------------欢迎纠错和提问!24小时在线不打烊!!---------------------
目录
- 分析采集实体
- 确定采集方法
- 制定爬取规则
- 编写代码并调试
- 得到数据
- 一些常用排错方法和技巧
- 常见报错信息汇总
- 总结和感悟
1. 分析采集实体
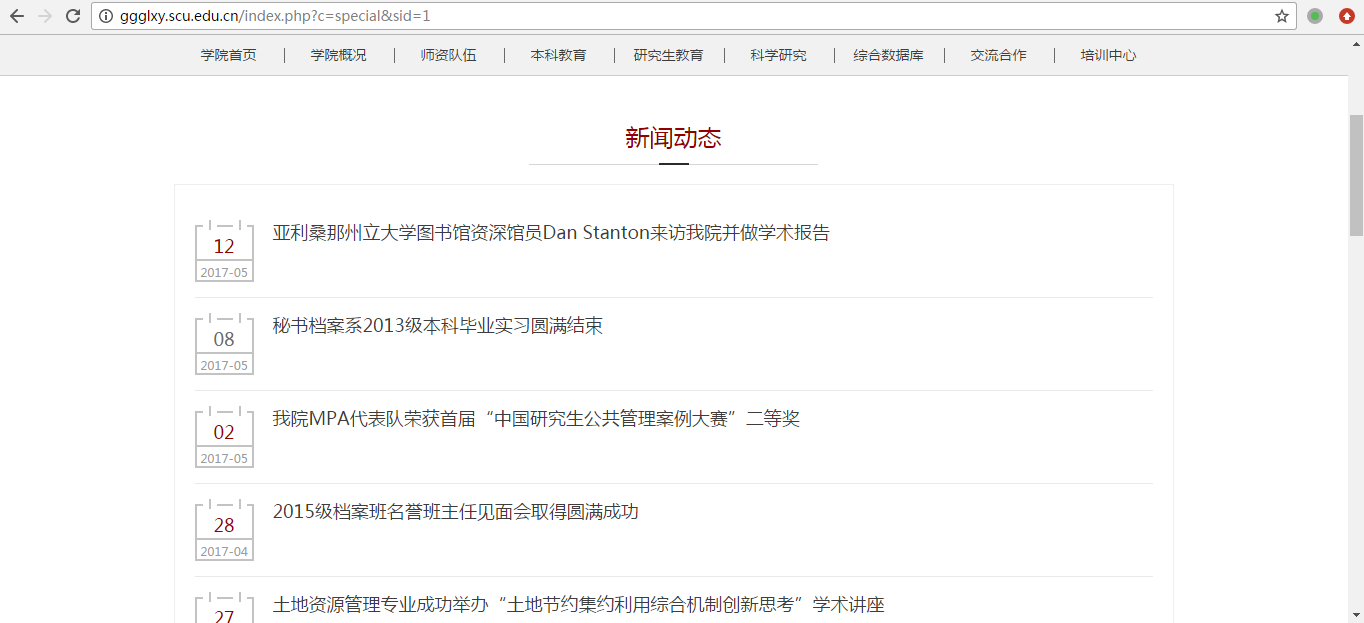
我们此次数据采集的目标内容是川大公管的新闻资讯。首先,我们需要分析网页的主要内容,并确定数据采集的实体。
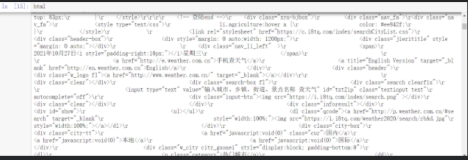
我们可以使用开发者工具或查看网页源码的方式对网页内容进行更深入的分析。
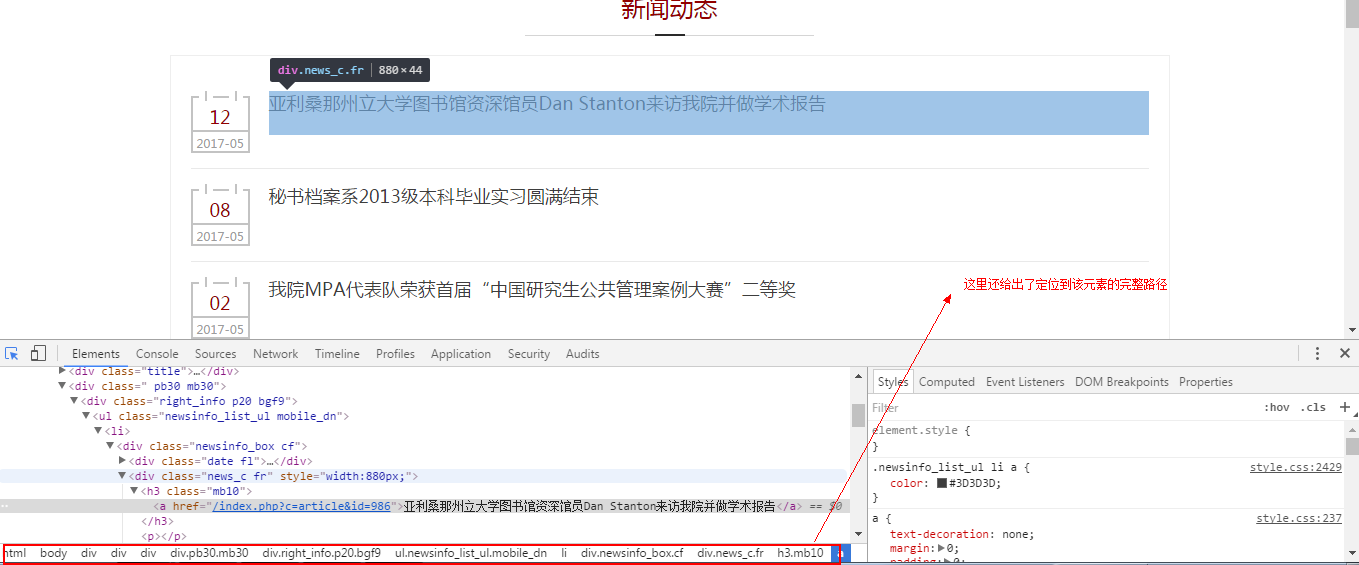
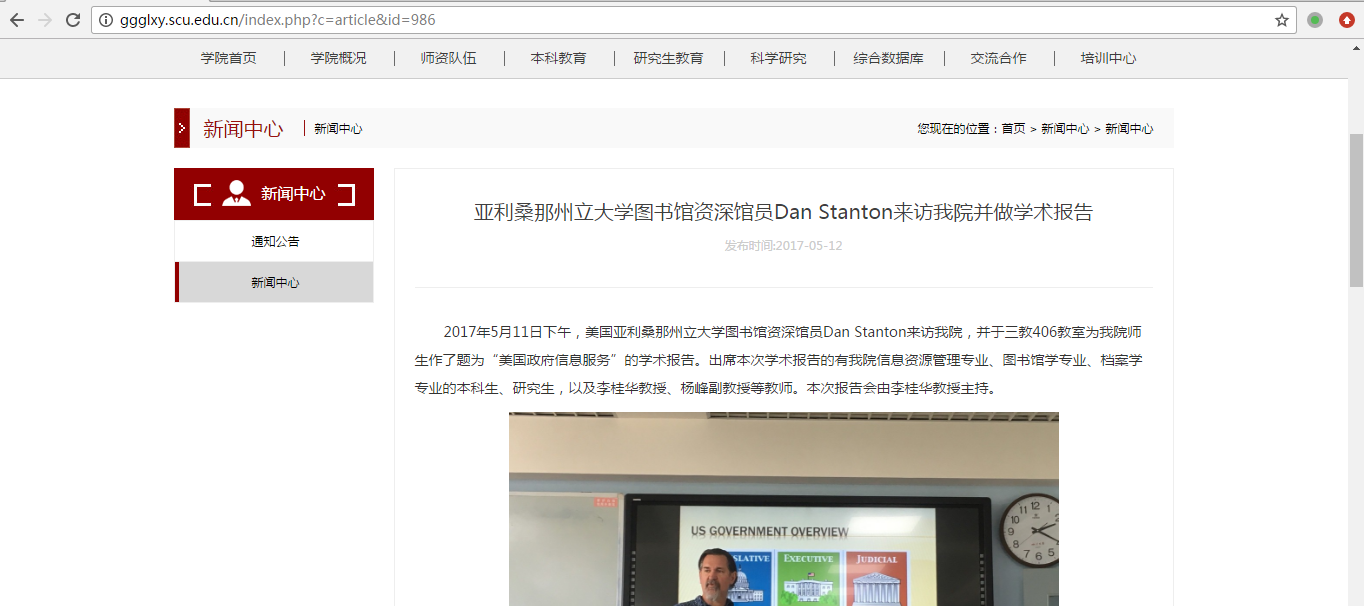
可以看出,我们需要采集的实体一共有四个,分别是标题(title),日期(date),内容(content)和图片(img)。
2. 确定采集方法
我们已经了解到,采集的实体共4个,其中,标题和日期在首页和详情页均有显示,因此我打算先采集首页转向详情页的链接,再进入第二层详情页进行数据采集。
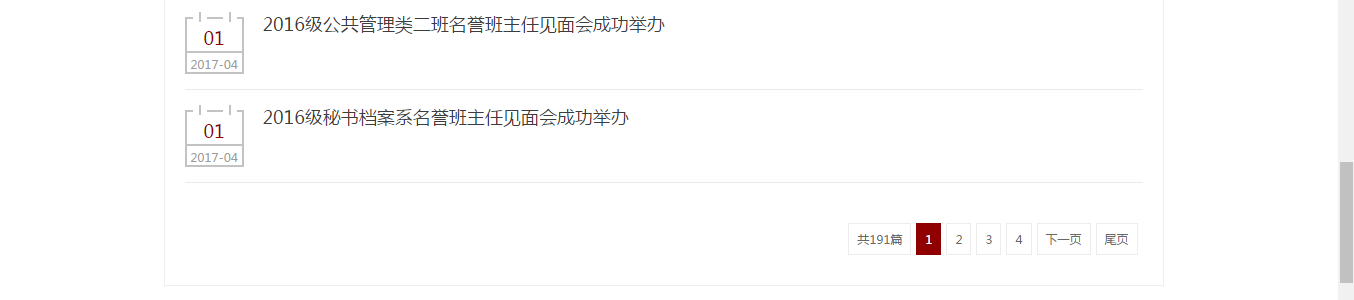
首页的新闻列表是分页显示的,我们还需要思考采集下一页新闻列表的方法。
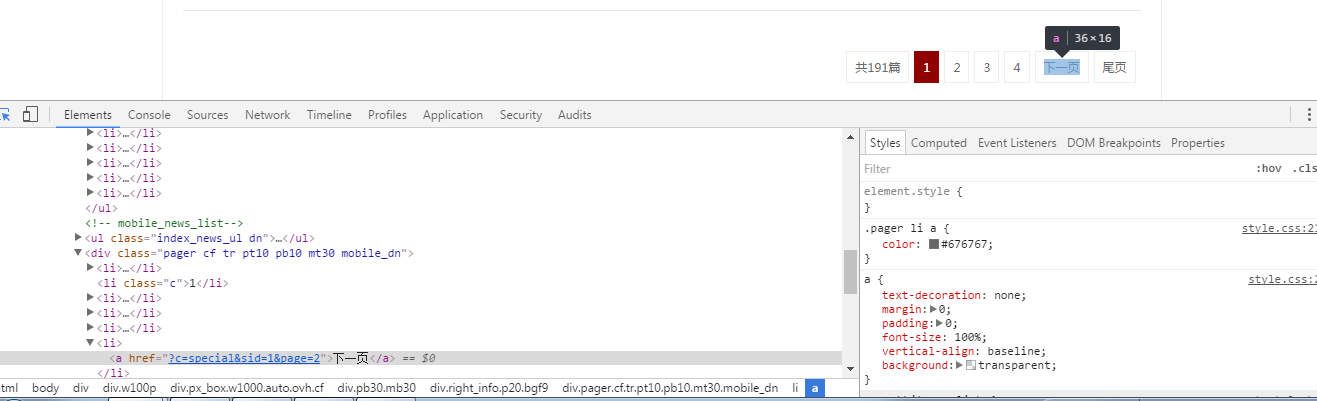
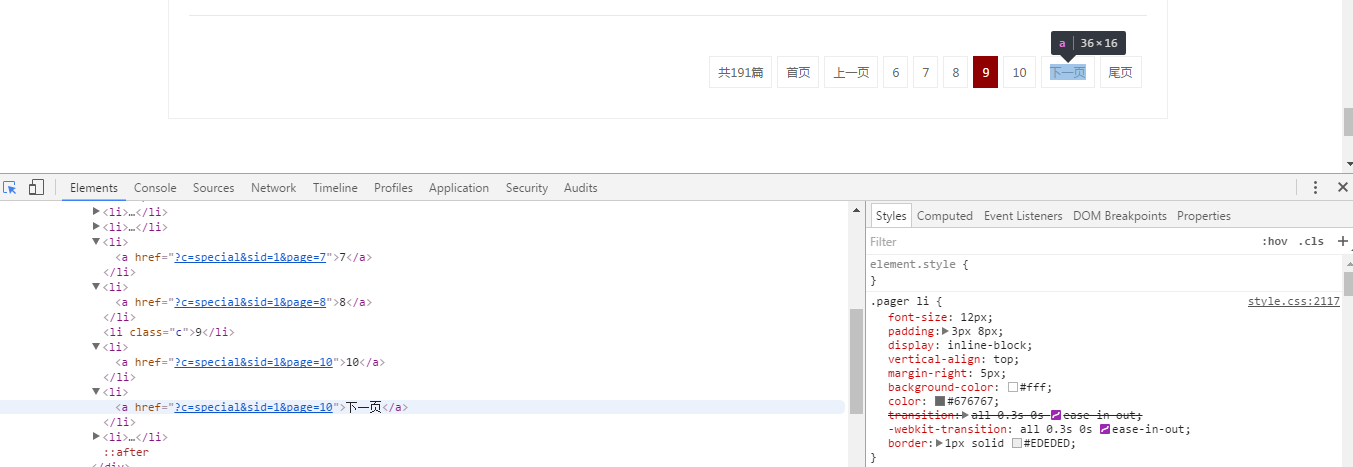
观察可知,我们并不能准确定位到下一页的url,一方面下一页按钮的url路径与其他页码的路径相同,另一方面它并不是固定在同一个次序的。
但是我们可以在<li class="c"></li>标签中获取当前页面的页码,与下一页的url固定格式进行字符串连接得到真正的下一页。
3. 制定爬取规则
这里我都采用css选择器的方法进行元素定位,并写出了完整路径(如果不确定是否可以准确定位到某元素,尽量写完整路径。)
div.pb30.mb30 div.right_info.p20.bgf9 ul.index_news_ul.dn li a.fl::attr(href)
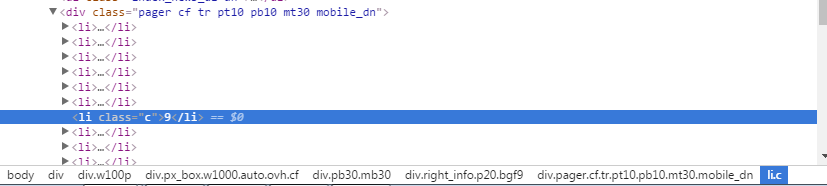
div.w100p div.px_box.w1000.auto.ovh.cf div.pb30.mb30 div.mobile_pager.dn li.c::text

div.w1000.auto.cf div.w780.pb30.mb30.fr div.right_info.p20 div.detail_zy_title h1::text

div.w1000.auto.cf div.w780.pb30.mb30.fr div.right_info.p20 div.detail_zy_title p::text
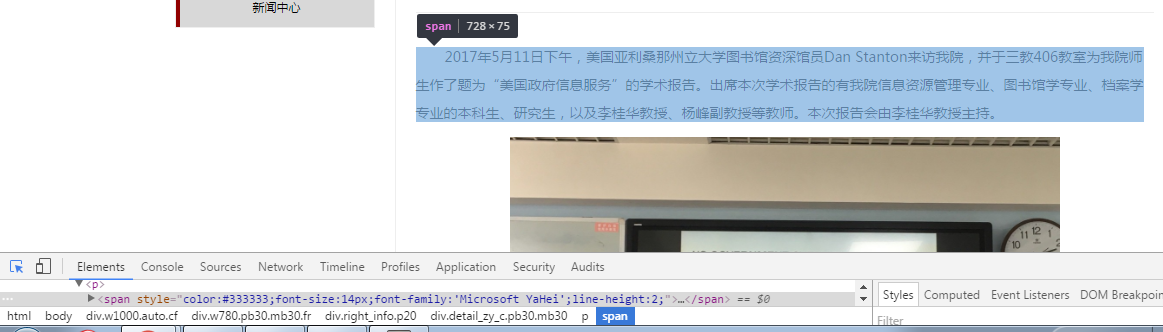

这里两个段落的路径不一样,为了保证两个段落都可以被采集到,选用范围较大的选择器。
div.w1000.auto.cf div.w780.pb30.mb30.fr div.right_info.p20 div.detail_zy_c.pb30.mb30 p span::text
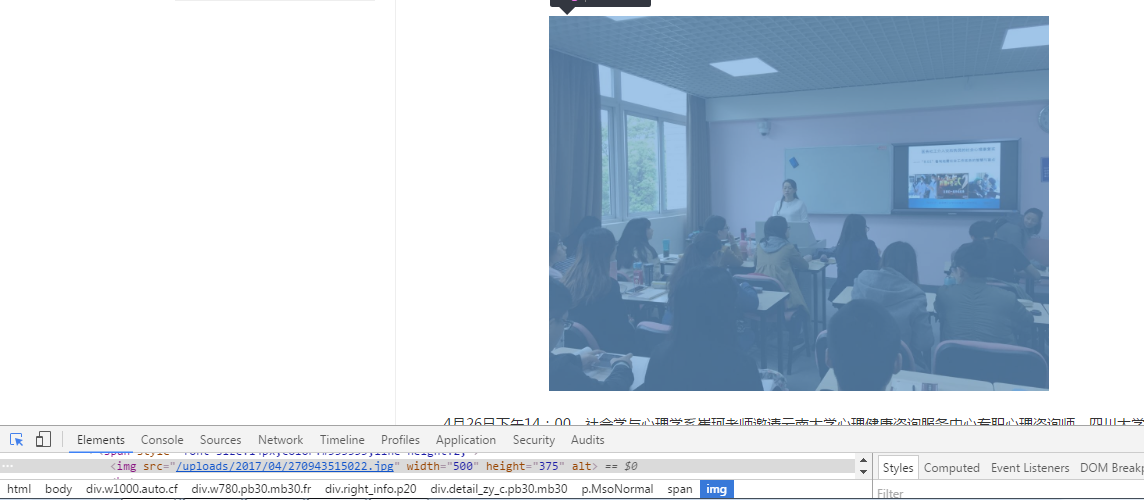
div.w1000.auto.cf div.w780.pb30.mb30.fr div.right_info.p20 div.detail_zy_c.pb30.mb30 p.MsoNormal img::attr(src)
4. 编写代码并调试
scrapy startproject ggnews
cd /ggnews/ggnews
在这里修改items.py的代码
# -- coding: utf-8 --
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GgnewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
content = scrapy.Field()
img = scrapy.Field()
cd spiders
编写ggnews.py
import scrapy
from ggnews.items import GgnewsItem
class GgnewsSpider(scrapy.Spider):
name = "ggnews"
start_urls = [
'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1',
]
def parse(self, response):
for href in response.css('div.pb30.mb30 div.right_info.p20.bgf9 ul.index_news_ul.dn li a.fl::attr(href)'):
url = response.urljoin(href.extract())
yield scrapy.Request(url, callback=self.parse2)
next_page = response.css('div.w100p div.px_box.w1000.auto.ovh.cf div.pb30.mb30 div.mobile_pager.dn li.c::text').extract_first()
if next_page is not None:
next_url = int(next_page) + 1
next_urls = '?c=special&sid=1&page=%s' % next_url
print next_urls
next_urls = response.urljoin(next_urls)
yield scrapy.Request(next_urls,callback = self.parse)
def parse2(self, response):
items = []
for new in response.css('div.w1000.auto.cf div.w780.pb30.mb30.fr div.right_info.p20'):
item = GgnewsItem()
item['title'] = new.css('div.detail_zy_title h1::text').extract_first(),
item['time'] = new.css('div.detail_zy_title p::text').extract_first(),
item['content'] = new.css('div.detail_zy_c.pb30.mb30 p span::text').extract(),
item['img'] = new.css('div.detail_zy_c.pb30.mb30 p.MsoNormal img::attr(src)').extract(),
items.append(item)
return items
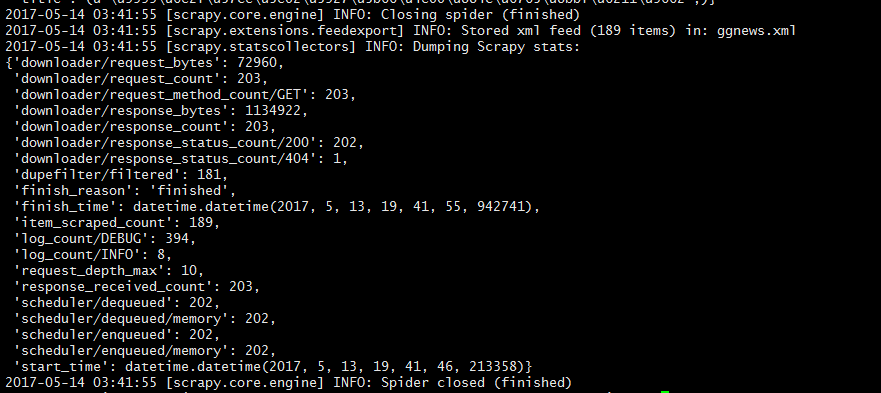
5. 得到数据
scrapy crawl ggnews -o ggnews.xml

6. 一些常见的排错方法和技巧
如何避免出现错误空格
如果你在写代码的过程中,不小心把空格和制表符<tab>混用,就很容易报错--
解决方法是设置你的IDE(代码编辑器)可以为你显示区分空格和制表符,就像这样
具体设置方法请自行百度:‘xxx如何显示空格和制表符’
如何检查xpath/css定位是否正确
用scrapy shell进行调试
教程在这里:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/shell.html
如何查看错误信息
7. 常见报错信息汇总
8. 总结和感悟
在进行数据采集的过程中,爬取数据的方法和规则是数据采集的核心与精华。不仅需要对整个页面的构造和布局有深入的理解和认识,而且需要耐心和细心,经过反复对比和推敲,才能使自己的爬虫规则更加完善。