目录
- luke 简介
- luke下载及安装
- luke 使用
- 打开luke
- Overview选项卡
- Documents选项卡
- search选项卡
- Commits选项卡
- Plugins选项卡
- 导出索引为XML
- 检查索引正确性
- 总结
1. luke 简介
luke###
是一个用于Lucene/Solr/Elasticsearch 搜索引擎的,方便开发和诊断的 GUI(可视化)工具。它有以下功能:
- 查看文档并分析其内容(用于存储字段)
- 在索引中搜索
- 执行索引维护:索引运行状况检查;索引优化(运行前需要备份)
- 从
hdfs读取索引 - 将索引或其部分导出为XML格式
- 测试定制的Lucene分析工具
- 创建自己的插件
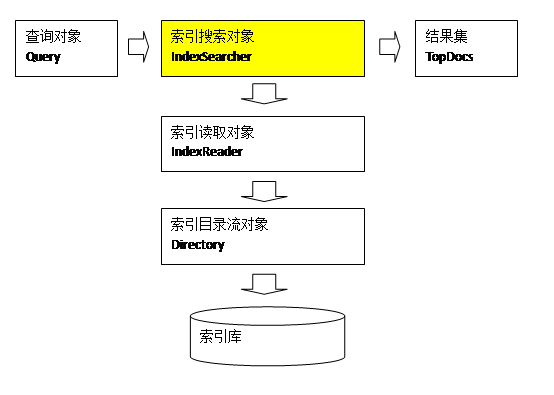
根据索引搜索的流程
2. luke 下载及安装
官方下载地址:https://github.com/DmitryKey/luke/releases
最新版本是 luke - 6.5.0,发布于2017年5月。
luke - 6.5.0 - luke - release.zip包含luke的可执行文件和打包好的jar包,可以通过双击
luke.bat/
luke.sh直接运行在Windows/Mac平台打开可视化界面。
Source code包含luke的Maven项目的源代码。
由于 luke 的兼容性不太好,不同版本的 Lucene 生成的索引要使用对应版本的luke 进行分析,如果版本过低会导致无法正确解析索引。
3. luke 使用
打开luke
在Windows系统下,双击打开luke.bat,启动Luke。选择需要处理的索引位置,点击OK导入索引。
这些是我从solr中拿到的索引文件
Overview选项卡
导入成功
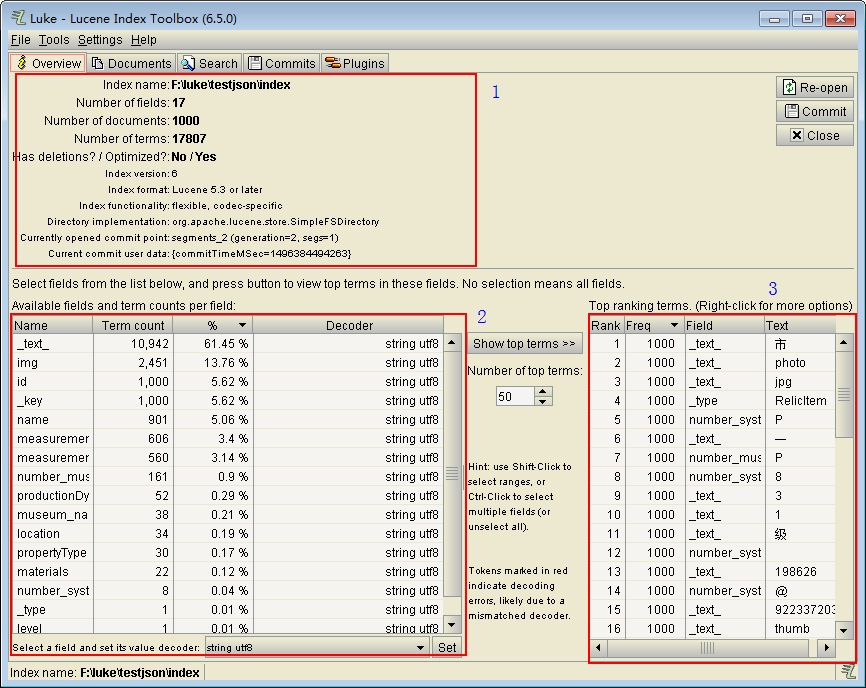
图中,1处显示了统计结果,有1000个Document,17个Field,一共有17807个分词
2处统计了所有的Field,每个Field所包含的分词个数,百分比和编码格式。
3处是索引的详细信息,统计了每个分词出现的词频,以及对应的Field名字。
Documents选项卡
document选项卡用于文档的增删查改,下方的表格就像数据表一样,为我们展示每一个文件的具体数据,我们可以根据文档编号来查找文件。
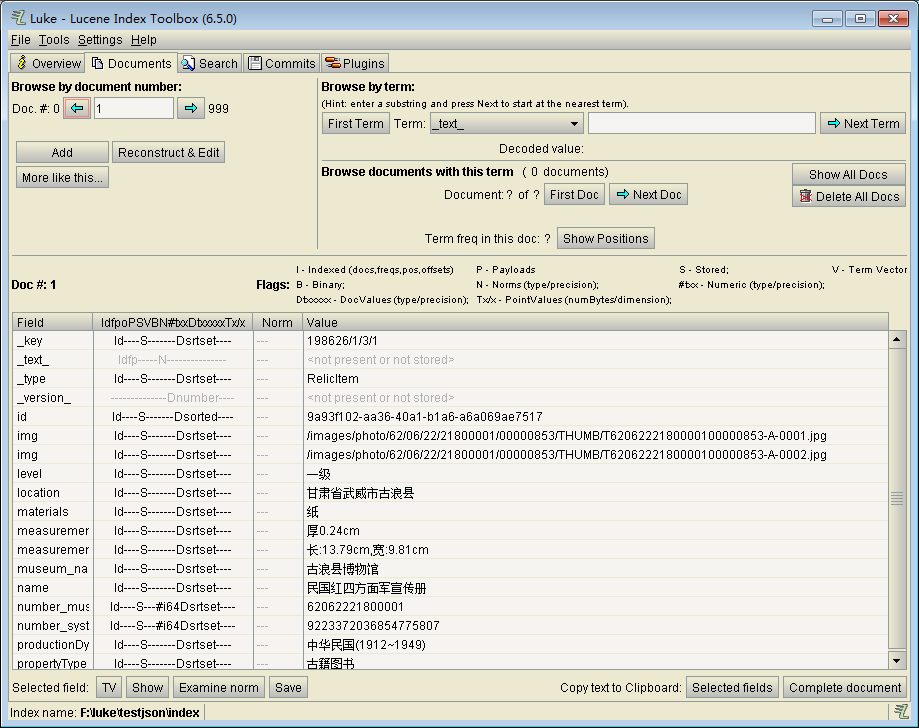
点击Add按钮新增Document;点击Recoonstruct&Edit来更改当前Document的值与属性。
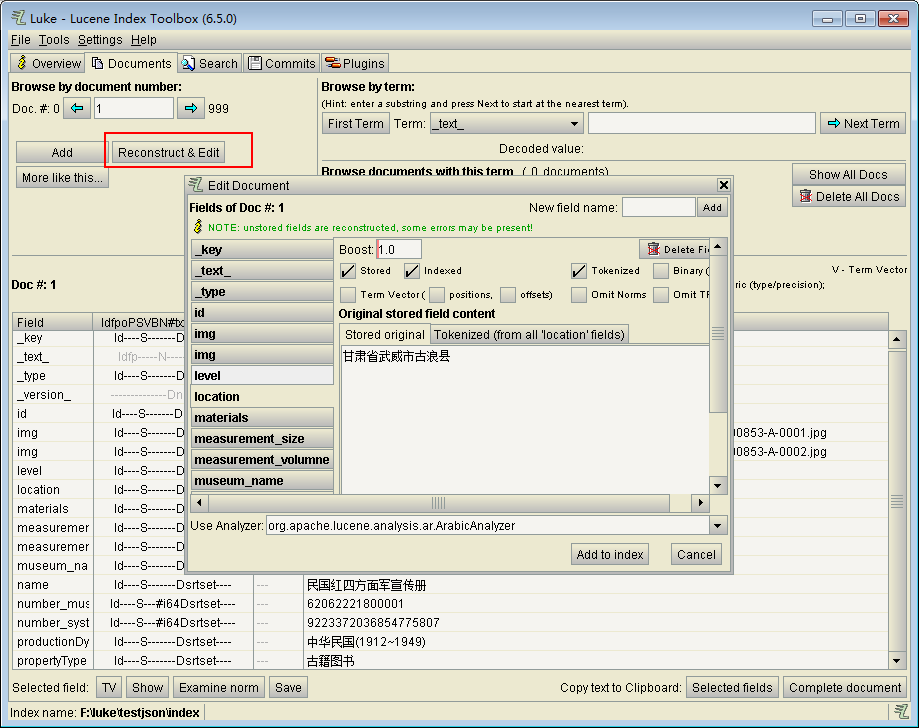
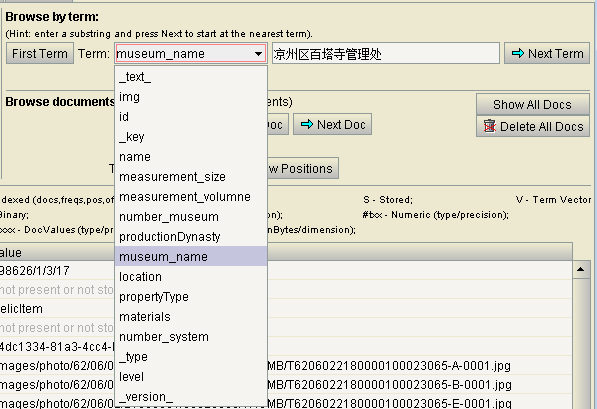
在这里可以查看所选择的field的值。这里也可以相当于搜索功能。
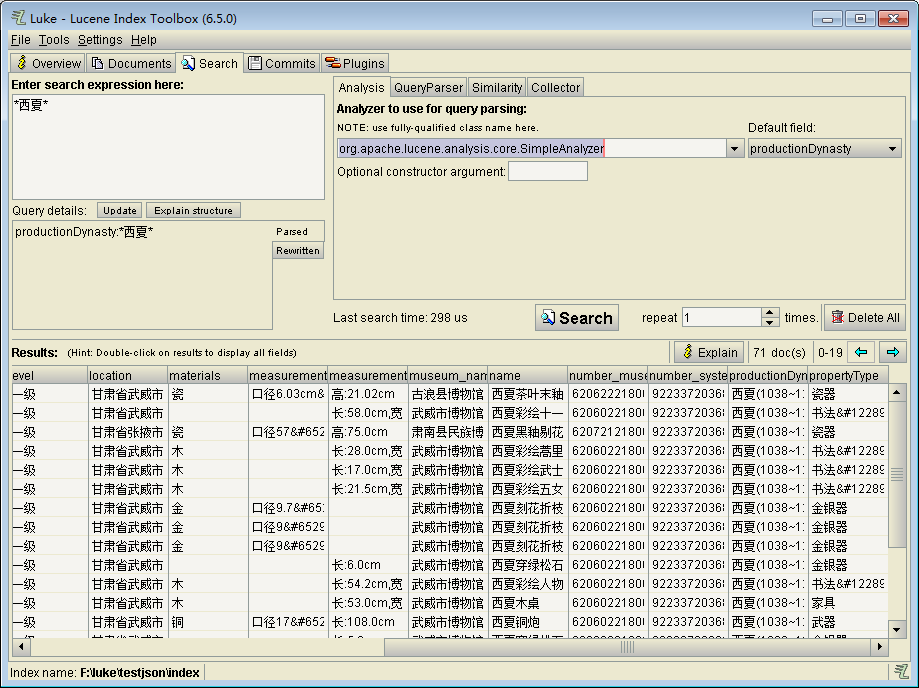
Search选项卡
在这个界面可以进行索引的搜索测试,构造lucene的搜索语句,选择匹配的field字段,并执行查询。也可以选择进行索引的分词器,设置默认字段和重复搜索次数,设置限制查询时间及匹配个数、是否可以模糊匹配、选取哪种相似度的匹配模式、是否选用XML Query模式,还可以查看查询花费的时间等。
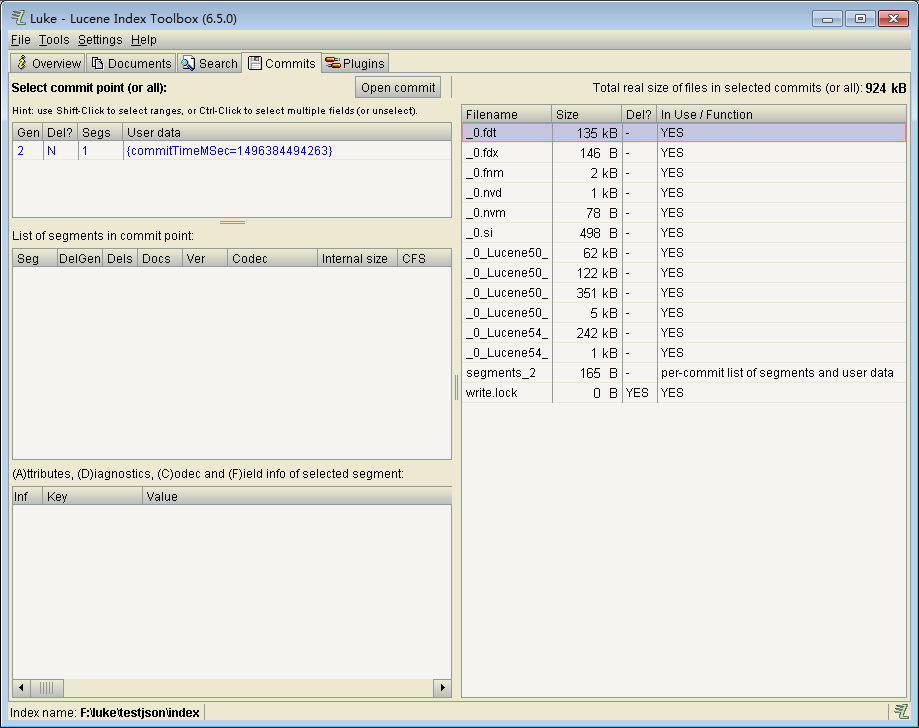
Commits选项卡
Comments选项卡用于查看每个索引文件的大小及相关属性,用于分析索引文件是否需要优化及合并等。
Plugins选项卡
这个页面是luke提供的各种插件,其中,Analyser Tool提供了一些分词的类,如图为luke分词的一个示例。Hadoop插件支持Hadoop( 0.20.1)的任何文件系统打开索引。
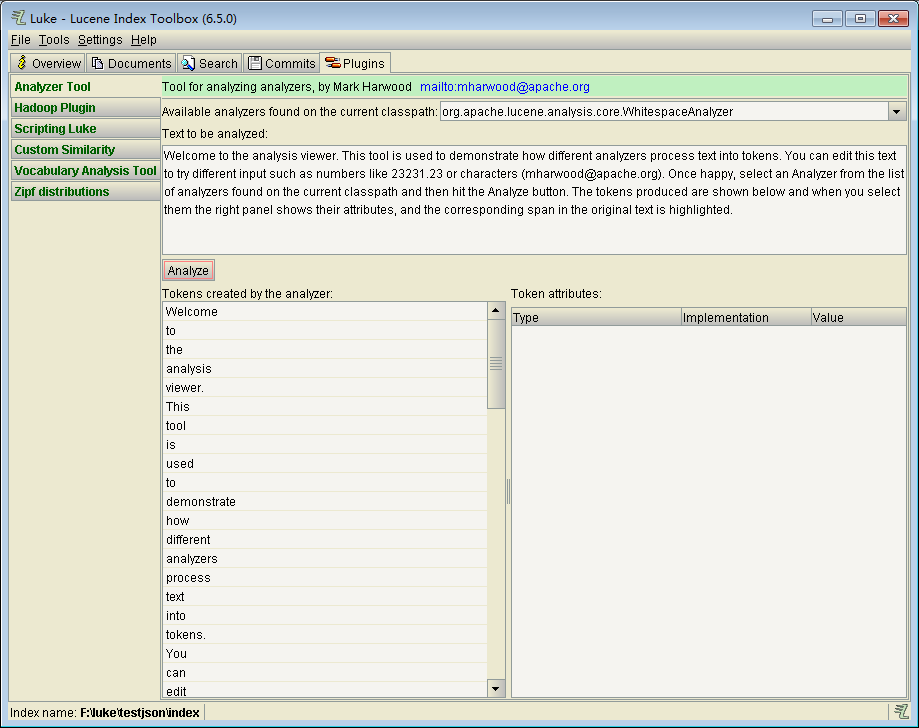
Scripting Luke提供了一个JavaScript的交互式Shell,可以在help查看具体使用方法。
Custom Similarity用于设计自定义相似性的插件
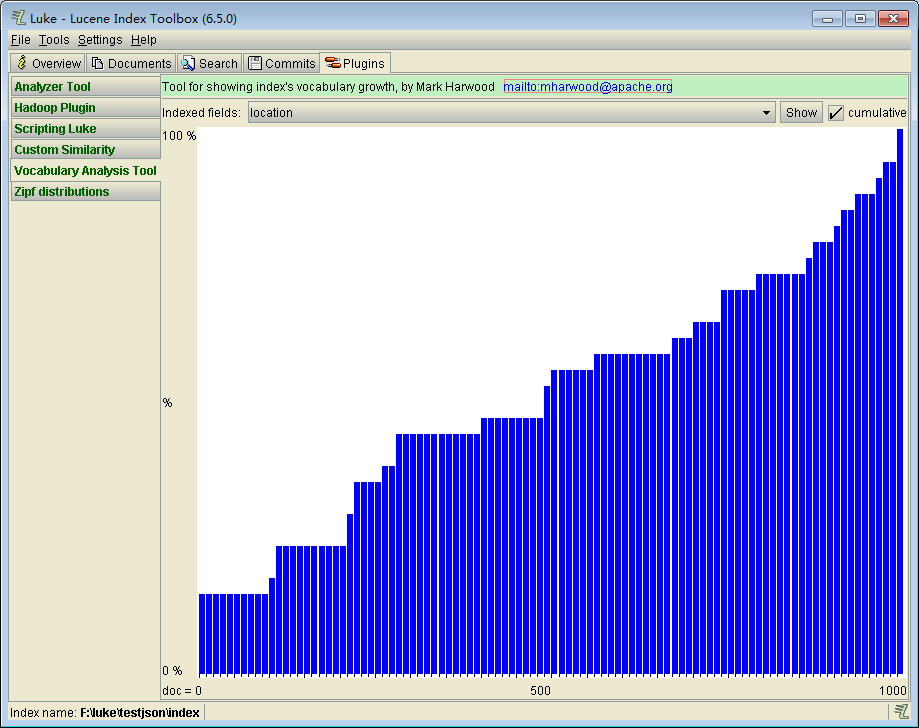
Vocabulary Analysisi Tool是一个表示索引词汇增长的工具。
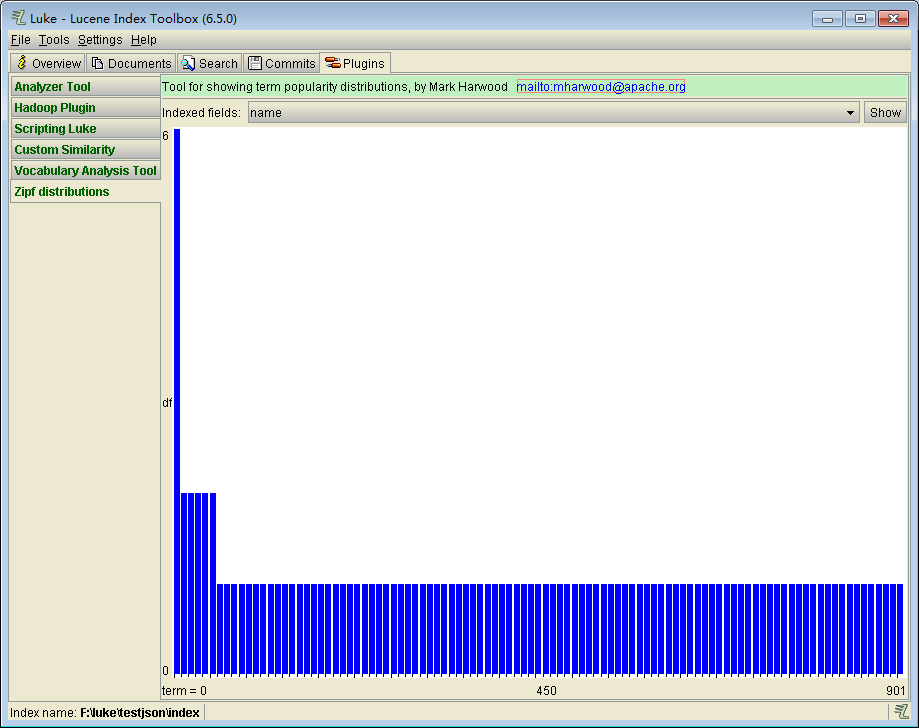
Zipf distribution是用于显示术语流行度发行的工具
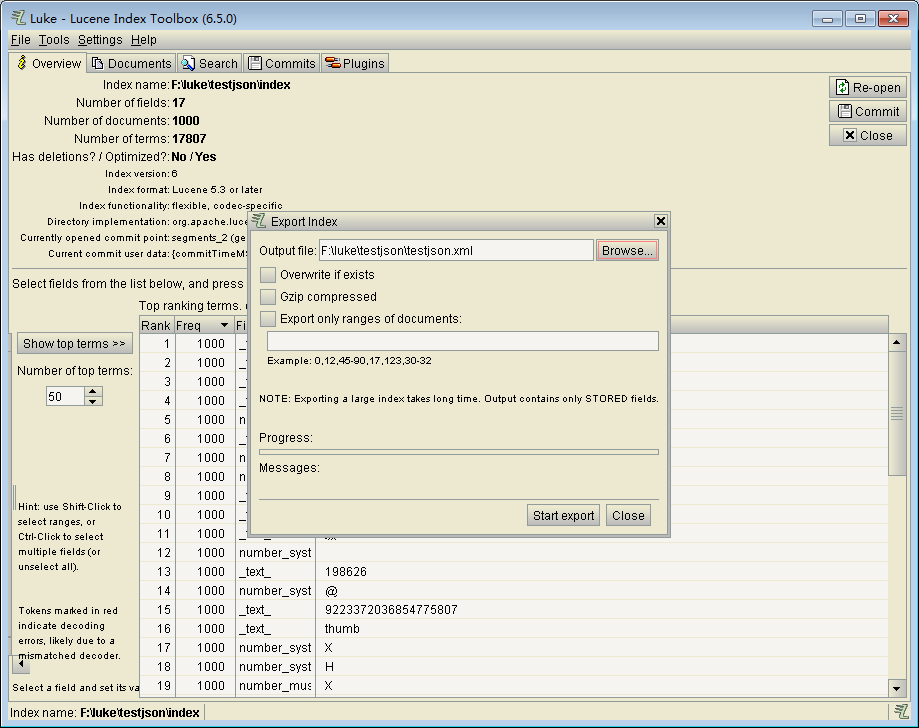
导出索引为xml
Tools->export Index to XML将索引导出为xml格式。
基本信息
<?xml version='1.0' encoding='UTF-8'?>
<index>
<info>
<indexPath>F:\luke\testjson\index</indexPath>
<fields count='17'>
<field name='_key'/>
<field name='_text_'/>
<field name='_type'/>
<field name='_version_'/>
<field name='id'/>
<field name='img'/>
<field name='level'/>
<field name='location'/>
<field name='materials'/>
<field name='measurement_size'/>
<field name='measurement_volumne'/>
<field name='museum_name'/>
<field name='name'/>
<field name='number_museum'/>
<field name='number_system'/>
<field name='productionDynasty'/>
<field name='propertyType'/>
</fields>
<numDocs>1000</numDocs>
<maxDoc>1000</maxDoc>
<numDeletedDocs>0</numDeletedDocs>
<numTerms>17807</numTerms>
<hasDeletions>false</hasDeletions>
<lastModified>N/A</lastModified>
<indexVersion>6</indexVersion>
<indexFormat>
<genericName>Lucene 5.3 or later</genericName>
<capabilities>flexible, codec-specific</capabilities>
</indexFormat>
<directoryImpl>org.apache.lucene.store.SimpleFSDirectory</directoryImpl>
部分索引内容
<field name='level' flags='Id----S-------Dsrtset----'>
<val>一级</val>
</field>
<field name='location' flags='Id----S-------Dsrtset----'>
<val>甘肃省张掖市肃南裕固族自治县</val>
</field>
<field name='materials' flags='Id----S-------Dsrtset----'>
<val>丝</val>
</field>
<field name='measurement_size' flags='Id----S-------Dsrtset----'>
<val>肩宽1.4,腰围宽1.5</val>
</field>
<field name='museum_name' flags='Id----S-------Dsrtset----'>
<val>肃南县民族博物馆</val>
</field>
<field name='name' flags='Id----S-------Dsrtset----'>
<val>乾隆御赐黄龙袍</val>
</field>
<field name='number_museum' flags='Id----S---#i64Dsrtset----'>
<val>62072121800001</val>
</field>
<field name='number_system' flags='Id----S---#i64Dsrtset----'>
<val>9223372036854775807</val>
</field>
<field name='productionDynasty' flags='Id----S-------Dsrtset----'>
<val>清(1616~1911)</val>
</field>
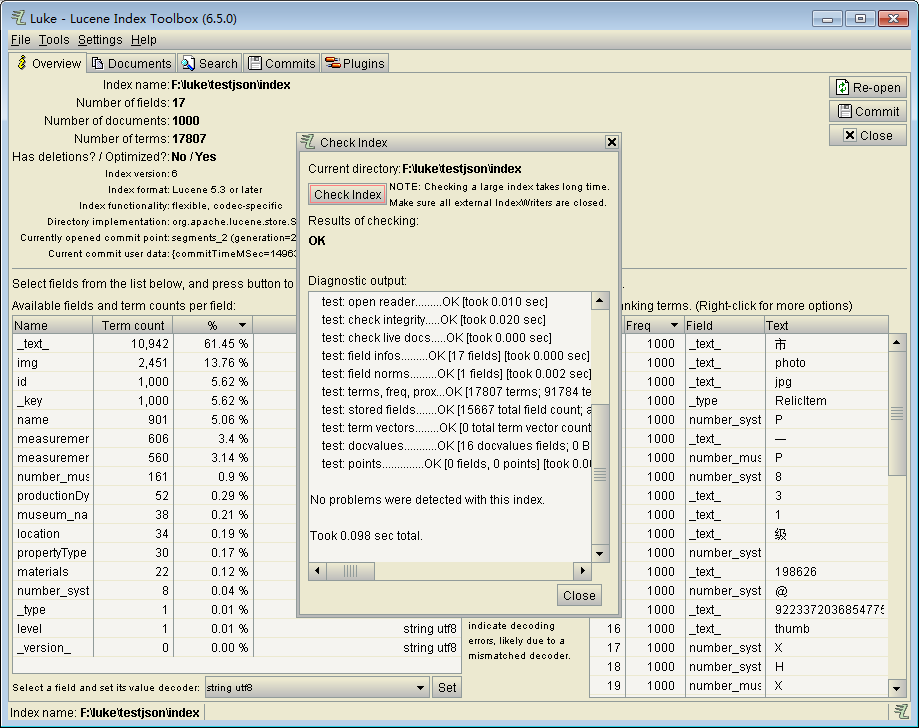
检查索引正确性
Tools->check Index Tool进行索引检查
4. 总结
通过使用luke 对索引进行分析,我对索引有了更加深刻的理解和认识。luke的功能很全面。对于索引文件方面,我们可以通过使用luke检查索引的正确性,分析索引文件并进行修改和优化,将索引文件转换为易于阅读的XML格式,并且更直观地看到我们的documents;对于分词方面,luke可以加载分词包进行分词,进行词频统计及词汇增长统计,以及术语流行度统计等;对于搜索引擎,我们在构造查询语句之前,可以先使用luke进行查询语句校验,分析查询效率,更好地进行查询优化,这些对于设计一个更优秀的搜索引擎是很有必要的。
参考链接:
http://www.kailing.pub/article/index/arcid/74.html
Luke:Lucene索引查看工具