求解最优MDP实际上就是找到最佳策略(Policy)π来最大化来最大化V函数(Value Function)。
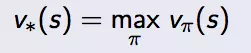
1. 策略估算(Policy Evaluation)
在MDP问题中,如何评估一个策略的好坏呢?那我们就计算这个策略的V函数(值函数),这里我们又要用到之前文章中提到的Bellman Equation了。
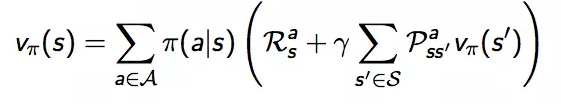
这个等式可以通过下一个状态的值函数来求得当前状态的值函数。如果我们对上面这个Bellman Equation中的每一个状态不停地迭代,最终每个状态的V(值)函数都会收敛成一个固定的数值。公式如下
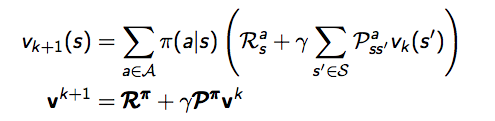
这个公式与公式二不同的是引入了k,k是指迭代的次数。Bellman等式左边表示k+1代s状态上的V函数,Bellman等式右边是k代中s下一个状态s'的的相关函数。第二个等式是Bellman等式的矩阵形式。我们使用这个公式将第k+1代的每一个状态s都更新之后,就完成了第k+1次迭代。
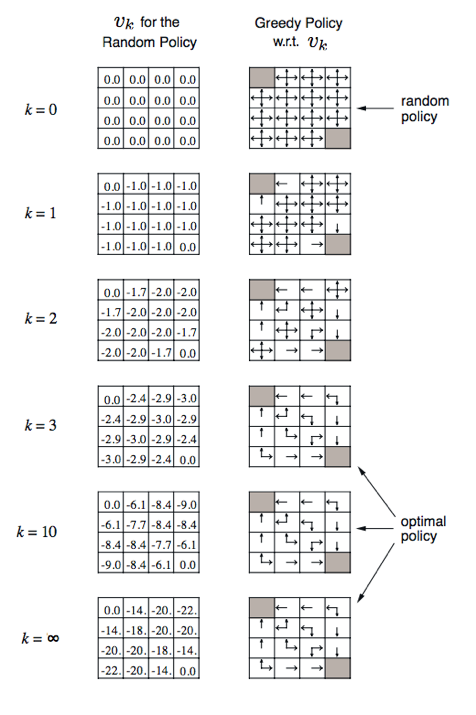
V函数真的会收敛到一个稳定的数值吗?我们不妨举一个例子。
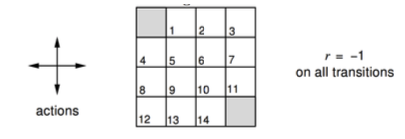
图中左上角和又下角是机器人的目标奖励为0,其他地方奖励为-1,策略是随机运动(上下左右移动的概率相等,为π=0.25)。价值函数的迭代过程如下:

可以看出在这个随机运动策略决策下,通过对Bellman 等式的不断迭代最终V函数会收敛到一个稳定的数值。
2. 策略迭代(Policy Iteration)
通过迭代Ballman函数的方式完成V函数的收敛,从而完成了对这个策略的评估。上面的例子即便收敛之后,就得到了随机运动的策略π的V函数。
接下来我们就要改进这个随机策略,改进的方法就是选择获取最大奖励的策略,而并不是跟之前一样随机运动。这种获取最大奖励的策略就叫做Greedy策略。
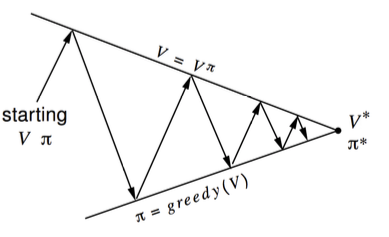
所以策略迭代分为两步:
第一步:用迭代Bellman 等式的方法对策略进行评估,收敛V函数(公式三)
第二步:用Greedy的方法改进策略。
上面两个步骤不停循环,最终策略就会收敛到最优策略。
2. 值迭代(Value Iteration)
也许你已经发现了,如同上面的例子,如果想找到最佳策略,在用Bellman等式迭代的过程中,并不一定需要等到V函数完全收敛。或许可以设定一个迭代上限,比如k=3就停止迭代了。
那更加极端地,在迭代Bellman 等式的过程中,我们只迭代一次(k=1)就采取Greedy策略,而不必等到V函数收敛,这种特殊的策略迭代方法就叫做值迭代(Value Iteration)
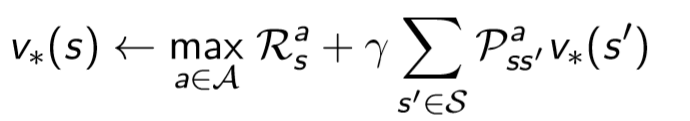
值迭代简单粗暴,直接用Bellman等式更新V函数,每次更新的时候都用Greedy的策略,当V函数收敛的时候策略也就收敛了。这个时候得到的策略就是最佳策略。
3. 总结
策略迭代和值迭代是寻找最优策略的方法,策略迭代先评估策略用迭代Bellman等式的方式使V函数收敛,然后再用Greedy的策略对原策略进行改进,然后不断重复这两个步骤,直到策略收敛。
值迭代可以看成是策略迭代的一种特殊情况,只迭代Bellman函数一次便使用Greedy策略对V函数进行更新,然后重复这两个动作直到V函数收敛从而获得最佳策略。
相关文章
AI学习笔记——求解最优MDP
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
AI学习笔记——Q Learning
AI学习笔记——Sarsa算法
AI学习笔记——卷积神经网络(CNN)
文章首发steemit.com 为了方便墙内阅读,搬运至此,欢迎留言或者访问我的Steemit主页

