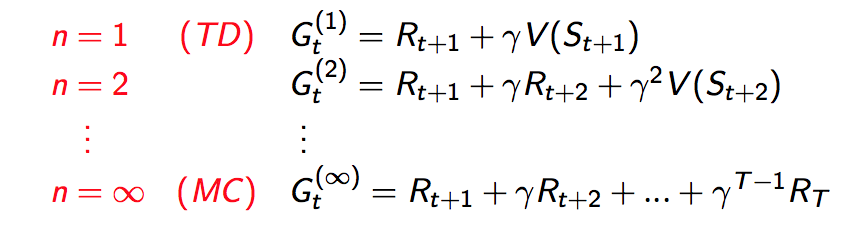前面关于强化学习的文章中介绍了MDP,动态规划的方法对MDP问题的V函数进行评估和求最优策略。然而现实问题中,往往很多时候环境是未知的。那么这篇文章就介绍一下在未知环境下用Model Free的方法预测MDP。
1. Monte-Carlo (蒙特卡洛)策略估计
Monte-Carlo(MC)方法广泛应用于数学、物理和金融等领域。比如在物理学中研究离子运动轨迹,我们就可以采用Monte-Carlo方法进行多次随机抽样,观测离子运动规律。
同样的,在解决强化学习问题的时候,机器人面对未知环境的时候,它也可以用MC的方法评估当前策略。如果想知道当前策略π,当前状态s下的价值函数V函数,在当前策略π下直接行动,待到达终点之后(完成一个episode),再复盘整个过程所获得的奖励,评估出s状态下的V函数。然后再不停迭代,最终获得该策略π下s状态下的真实V函数Vπ(s)。
当然Monte-Carlo策略估计方法也分为首次访问MC方法和每次访问MC方法,两者唯一的不同只有一处,下面算法过程中在括号中的就是每次访问MC方法。
算法过程如下:
- 在一个episode中,当s状态第一次被访问到(或者每次被访问到)的时候,计数器N(S)=N(S)+1。
- 总共得到的奖励S(s) = S(s) + Gt
- 价值V函数的数值V(s)= S(s) /N(s)
- 当迭代无数次之后,根据大数定理,V(s)就应该趋近真实的V函数Vπ(s)
2. Monte-Carlo(MC)迭代更新
在介绍Monte-Carlo迭代更新之前必须先引入一个迭代求平均的例子。比如你想算一箱苹果中苹果的平均重量,简单的方法是随机抽取几个苹果,将这几个苹果的重量相加再除以个数就估算出了苹果的平均重量。
如果想让这个估计更加精确,你又从箱子里面拿出一个苹果,这时候还需要将所有拿出来的苹果重量相加吗?当然不需要。你只需要将这个苹果的重量减去之前求得的平均数,再除以总共拿出苹果的数量得到误差。最后原平均数加上这个误差就是新的平均数了。证明过程如下。
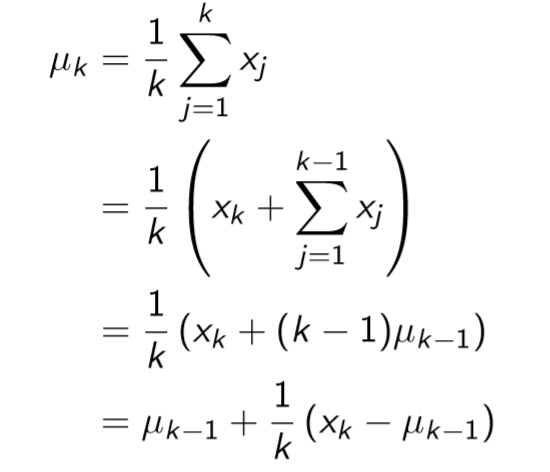
有了这个迭代求平均值的方法我们就可以改进MC算法,不用记住总共得到的奖励S(s)了
对于每个St,和奖励Gt
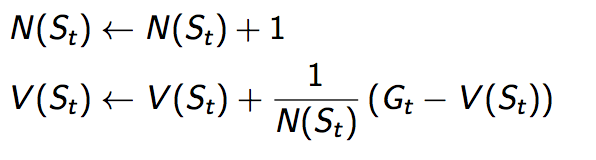
其实我们甚至都不用记住N(St), 因为在非静态的(Non-Stationary)的问题中,如果N越大,就意味着误差越小,当前行动对V函数的纠正就越小。所以在实际过程中我们往往用一个固定的学习速率α来代替1/N(St):
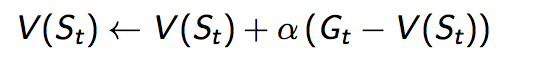
这个公式是不是跟之前的梯度下降(Gradient Desent)方法非常类似了。
3. Temporal-Defference (TD)算法
MC有一个很大的缺点,就是要更新V(s)一定要走完整个epsoide。TD方法不需要走完整个epsoide,走有限几步就可以更新,极端情况下TD(0)甚至可以走一步就更新。
回顾MC算法:
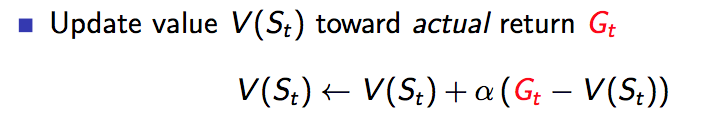
其中
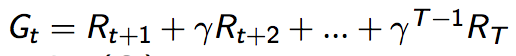
TD(0)算法:

如英文描述红色文字部分叫做TD-target。与MC类似括号里面的误差叫做TD error
4. MC vs TD
MC有高Variance 零Bias:
- 收敛性好
- 对初始值不敏感
- 算法容易理解和使用
MC 对解决非马可夫环境(或者部分马可夫环境)效果好。
TD有低的Variance,一些Bias
- 比MC效率高
- TD(0)能收敛于Vπ(s)
- 对初始值敏感
TD能探索出马可夫模型,对马可夫环境效果好。
5. DP,MC,TD比较
之前文章中介绍的动态规划(DP),与MC,TD相比较可以发现
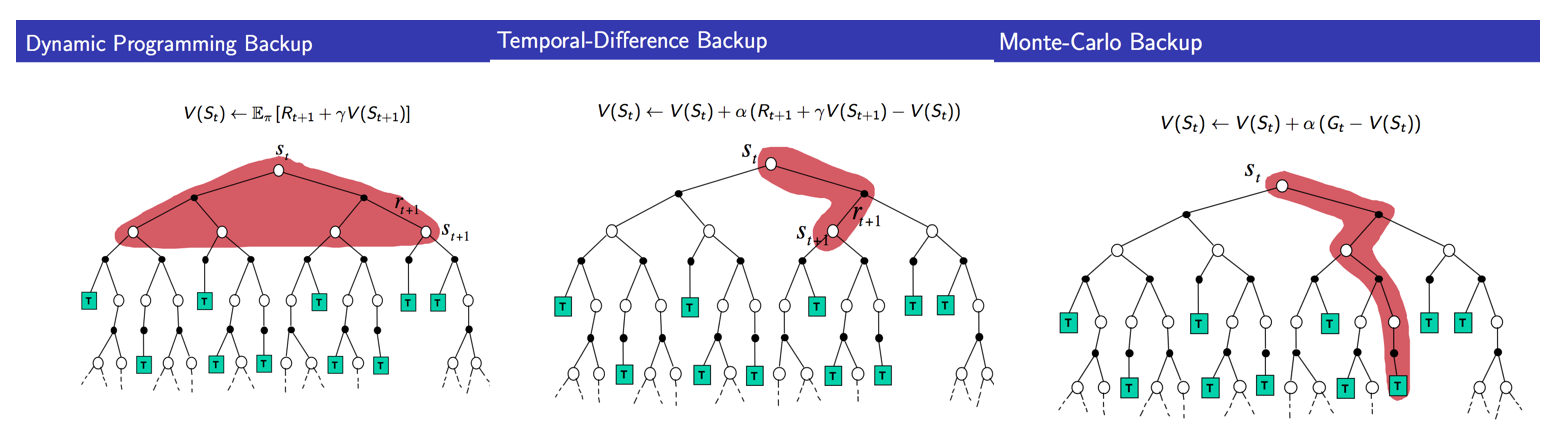
从抽样的数量和反馈的深度可以这样理解DP,MC和TD
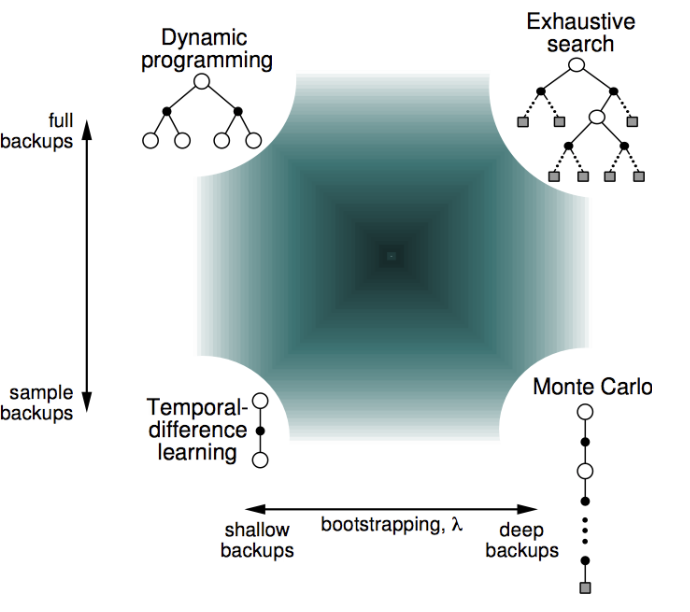
实际上TD不仅仅只有只走一步的TD(0), 可以是n TD(n)。当n等于无穷大的时候TD=MC