1. 介绍
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。 SVM几乎可以适用于所有的学习任务,包括分类和数值预测两个方面。著名的应用包括:
- 在生物信息学领域中,识别癌症或者其他遗传病的微阵列基因表达数据的分类
- 罕见却重要的事件检测,如内燃机故障,安全漏洞等。
- 当支持向量机用于二分类时,它最容易理解
2.原理
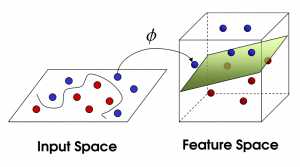
SVM可以想象成一个平面,该平面定义了各个数据点之间的界限,而这些数据点代表是根据它们的特征值在多维空间绘制。支持向量机的目标是创建一个平面边界,称为一个超平面,使得任何一边的数据划分都是均匀的。通过这种方式,svm结合了近邻学习和线性回归,因此允许支持向量机对复杂的关系进行建模。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小
image
3.kernlab
建立模型:
m <- ksvm(target ~ predictors , data = data, kenal = "rbfdot" , c = 1)
- kernal:给出一个非线性映射,例如"rbfdot"(径向基函数),"polydot"(多项式函数),"tandot"(双曲正切函数),"vanilladot"(线性函数)
- c:对于软边界的惩罚大小,较大的c值会导致边界较窄。
p <- predict(m, test, type = "response")
- 函数ksvm所训练的模型
- test:包含测试数据的数据框
- type:用于指定预测的类型为“respon”(预测类别), 或者“probabiilities”(预测概率, 每一列对应一个类水平值)
- 例子:classifier <- ksvm(letter ~., data = letter_trian, kernal = "vanilladot")
- prediction <- predict(classifier, latter_test)
- 划分训练集和测试集
setwd("E:\\Rwork")
rm=list()
#install.packages("kernlab")
library(kernlab)
iris=iris
##########拆分数据集
iris=iris
N = sample(2,nrow(iris),replace = T,prob = c(0.7,0.3))
train = iris[N==1,]
test = iris[N==2,]
dim(train)
dim(test)
- 建立模型
#=================================
set.seed(12345) # for reproducing results
ksvmfit <- ksvm(Species ~ ., data = train, type = "C-bsvc",
kernel = "rbfdot", kpar = list(sigma = 0.01), C = 10, prob.model = TRUE)
ksvmfit
> ksvmfit
Support Vector Machine object of class "ksvm"
SV type: C-bsvc (classification)
parameter : cost C = 10
Gaussian Radial Basis kernel function.
Hyperparameter : sigma = 0.01
Number of Support Vectors : 40
Objective Function Value : -36.6708 -15.7083 -208.9155
Training error : 0.039216
Probability model included.
- 预测
predict=predict(ksvmfit, test, type = "probabilities")
predict=predict(ksvmfit, test, type = "response")
> real=test$Species
> table(predict,real)
real
predict setosa versicolor virginica
setosa 19 0 0
versicolor 0 12 0
virginica 0 2 15
> #==========================================
> test=cbind(test,as.data.frame(predict))