- 什么是交叉验证?在机器学习中,交叉验证是一种重新采样的方法,用于模型评估,以避免在同一数据集上测试模型。交叉验证的概念实际上很简单:我们可以将数据随机分为训练和测试数据集,而不是使用整个数据集来训练和测试相同的数据。交叉验证方法有几种类型LOOCV - leave -one- out交叉验证,holdout方法,k - fold交叉验证。
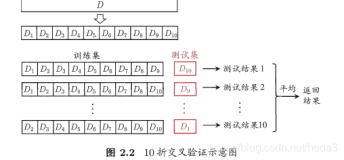
- K折交叉验证(k-fold cross-validation)首先将所有数据分割成K个子样本,不重复的选取其中一个子样本作为测试集,其他K-1个样本用来训练。共重复K次,平均K次的结果或者使用其它指标,最终得到一个单一估测。这个方法的优势在于,保证每个子样本都参与训练且都被测试,降低泛化误差。其中,10折交叉验证是最常用的。
英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十分,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。之所以选择将数据集分为10份,是因为通过利用大量数据集、使用不同学习技术进行的大量试验,表明10折是获得最好误差估计的恰当选择,而且也有一些理论根据可以证明这一点。但这并非最终诊断,争议仍然存在。而且似乎5折或者20折与10折所得出的结果也[相差无几
#####################################################
#--------------------------------------------------
#####################################################
#数据导入并分组
target.url <- 'https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data'
data <- read.csv(target.url,header = F)
set.seed(17)
require(caret)
folds <- createFolds(y=data[,61],k=10)
#####################################################
#--------------------------------------------------
#####################################################
#2、选取最优训练集与测试集的AUC为最优的训练集与测试集划分。
library(pROC)
max=0
num=0
auc_value<-as.numeric()
for(i in 1:10){
fold_test <- data[folds[[i]],] #取folds[[i]]作为测试集
fold_train <- data[-folds[[i]],] # 剩下的数据作为训练集
fold_pre <- lm(as.numeric(V61)~.,data=fold_train)
fold_predict <- predict(fold_pre,
type='response',
newdata=fold_test)
auc_value<- append(auc_value,
as.numeric(auc(as.numeric(fold_test[,61]),
fold_predict)))
}
num <- which.max(auc_value)
print(auc_value)
#####################################################
#--------------------------------------------------
#####################################################
#根据前一步的结果,使用最优划分构建线性分类器并预测。绘制出测试集的ROC曲线。
fold_test <- data[folds[[num]],]
fold_train <- data[-folds[[num]],]
fold_pre <- lm(as.numeric(V61)~.,data=fold_train)
fold_predict <- predict(fold_pre,type='response',newdata=fold_test)
roc_curve <- roc(as.numeric(fold_test[,61]),fold_predict)
plot(roc_curve, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),
grid.col=c("green", "red"), max.auc.polygon=TRUE,
auc.polygon.col="skyblue", print.thres=TRUE,main="ROC curve for the set with the largest AUC value")
set.seed(450)
cv.error <- NULL
k <- 10
library(plyr)
pbar <- create_progress_bar('text')
pbar$init(k)
for(i in 1:k){
index <- sample(1:nrow(data),round(0.9*nrow(data)))
train.cv <- scaled[index,]
test.cv <- scaled[-index,]
nn <- neuralnet(f,data=train.cv,hidden=c(5,2),linear.output=T)
pr.nn <- compute(nn,test.cv[,1:13])
pr.nn <- pr.nn$net.result*(max(data$medv)-min(data$medv))+min(data$medv)
test.cv.r <- (test.cv$medv)*(max(data$medv)-min(data$medv))+min(data$medv)
cv.error[i] <- sum((test.cv.r - pr.nn)^2)/nrow(test.cv)
pbar$step()
}
mean(cv.error)
cv.error
library(randomForest)
data("iris")
data <- iris
library("caret")
folds<-createFolds(y=data$Species,k=10) #根据training的laber-Species把数据集切分成10等份
re<-{}
for(i in 1:10){
traindata <- data[-folds[[i]],]
testdata <- data[folds[[i]],]
rf <- randomForest(Species ~ ., data=traindata, ntree=100, proximity=TRUE) #Species是因变量
re=c(re,length(traindata$Species[which(predict(rf)== traindata$Species)])/length(traindata$Species))
}
mean(re)#取k折交叉验证结果的均值作为评判模型准确率的结果