先上一个爬虫程序的成品截图,然后一行行代码来细说。
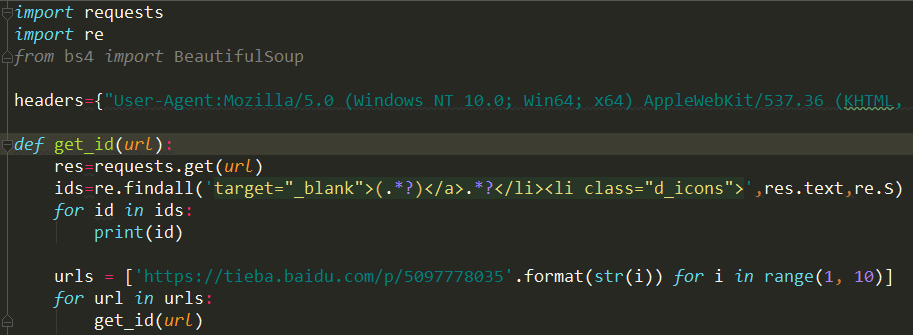
一、导入requests库和正则表达式
首先是导入requests库和re模块。使用re模块,python 会将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配。
用Python写爬虫,提取网站信息有很多种方法,第三行被注释掉的代码,导入beautifulsoup就是其中一种方法,但本篇文章只说明如何使用正则表达式作匹配。
二、添加header
如果不添加该行代码的话,程序会报错。例如出现urllib2.HTTPError: HTTP Error 403: Forbidden的错误。这是由于网站禁止爬虫。
我们可以加上头信息,伪装成浏览器访问.。
其中,agent就是请求的身份,如果没有写入请求身份,那么服务器不一定会响应,所以要在headers中设置agent。接下来是写清楚电脑配置和浏览器配置。
我查了一下资料,此处关于header的内容细究下去还是挺多的,而且分为好几类header。
比如,在登录之后的知乎首页按F12->network,点击第一个请求,查看headers,可看到General、Response Headers、Request Headers三个分类,有General
Request URL: https://www.zhihu.com/
Request Method:GET
在此不赘述,提供我用的具体代码。
headers={"User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
三、定义获取用户id的函数
主要说一下re的主要功能函数。
常用的功能函数包括:compile、search、match、split、findall(finditer)、sub(subn)、compile等等参数。这里使用了re.findall(pattern, string[, flags])函数。
该作用是:在字符串中找到正则表达式所匹配的所有子串,并组成一个列表返回。
下面这个博客里面有关于正则表达式的使用举例,大家可以参考一下。
http://blog.csdn.net/u014015972/article/details/50541839
上面的程序只用到了(.*?)这一正则表达式,即写出用户id前后一定数量的代码,即可匹配出用户id。可见以下的使用举例:
***************************************
# .*?的使用举例
c = re.findall('xx.*?xx', secret_code)
printc# ['xxIxx', 'xxlovexx', 'xxyouxx']
***************************************
四、输入要爬的网站url,调用获取id的函数
不同的网站有不同的正则表达式,这里我选的是百度贴吧里的二次元吧。
https://tieba.baidu.com/p/5097778035
程序是没有错的,但是由于方法的局限性,除了爬取出用户id之外,还匹配了一些别的文本。
其实上面那个正则表达式还可以改得更简单些。?
罗罗攀老师讲课的时候用的是糗事百科的网站,正则表达式是<h2>(.*?)</h2>,大家也可以试一下。
等我学会了用beautifulsoup写爬虫会再放一篇文章上来的,弥补现有程序的局限性。
如果有大神知道怎样解决上面这个问题,也请留言指点一二。