最近在 OpenStack 环境下需要部署消息队列集群,包括 RabbitMQ 和 Kafka,这篇记述一下 Kafka 集群的部署过程。
本文所用的环境包括:
软件版本
- OpenStack 版本: Pike release
- Kafka 版本:2.11-2.0.0
- Zookeeper 版本:3.4.8-1
- 虚拟机系统:Ubuntu 16.04
- Java 版本:openjdk 1.8.0_181
虚拟机信息:
- 一共用到三台虚拟机;
- zookeeper 和 Kafka 共用统一虚拟机;
- 三台虚拟机信息:
- hostname:kafka-1,IP:10.0.0.1,ID:1
- hostname:kafka-2,IP:10.0.0.2,ID:2
- hostname:kafka-3,IP:10.0.0.3,ID:3
注意:由于用到了多台服务器,所以以下操作步骤如无特殊说明,需要在全部三台虚拟机上执行。
0. 服务器配置
在进行 Kafka 和 zookeeper 集群配置之前要先做一些服务器的基础配置,主要是主机名的修改。
首先要先修改 hostname:
$ cat /etc/hostname
kafka-1/2/3
然后修改 hosts 文件,当然下面文件的内容是根据前面给出的配置信息进行填写的,大家需要根据自己服务器的 IP 和实际主机名进行对应修改。
$ cat /etc/hosts
......
10.0.0.1 kafka-1
10.0.0.2 kafka-2
10.0.0.3 kafka-3
1. Zookeeper 集群
Kafka 目前专注于消息处理方面的功能,大部分其他能力都是靠外部组件来实现的,比如搭建集群就需要依赖于 zookeeper,鉴权则用到了 Kerberos 和 SASL。所以第一步自然是要搭建 zookeeper 了。
当然 Kafka 是自带 Zookeeper 的,如果用自带 Zookeeper 的方式,可以实现单节点的 Kafka 集群,但本文讨论的是集群环境,所以不详细描述单节点的部署方式。
1.1 zookeeper 集群安装
之所以要用三个虚拟机,是因为 Zookeeper 集群需要至少三个节点才能正常工作,所以 zookeeper 的安装步骤当然是所有三台上都要执行。Zookeeper 用的是 Ubuntu 16.04 的默认版本,所以大家再去安装时,可以版本对不上,这不是问题,基本步骤应该没什么变化。
$ sudo apt update
$ sudo apt upgrade -y
$ sudo apt install -y openjdk-8-jre
$ sudo apt install -y zookeeperd
接下来要修改 zookeeper 的配置信息,第一步是要修改 zoo.cfg 中全部 zookeeper 器群服务器的地址信息。下面配置中的 kafka-* 这部分需要根据大家的环境信息替换为主机名或主机 IP。
$ cat /etc/zookeeper/conf/zoo.cfg
...
# specify all zookeeper servers
# The fist port is used by followers to connect to the leader
# The second one is used for leader election
#server.1=zookeeper1:2888:3888
#server.2=zookeeper2:2888:3888
#server.3=zookeeper3:2888:3888
server.1=kafka-1:2888:3888
server.2=kafka-2:2888:3888
server.3=kafka-3:2888:3888
...
最后要修改 /etc/zookeeper/conf/myid,这个文件就是集群的中的特殊标识,一般来讲,三台服务器的集群,三台服务器分别使用 1、2、3 就可以了。所以为了避免大家配置错误,下面把三台服务器的配置示例都贴了上来。
$ cat /etc/zookeeper/conf/myid # on kafka-1
1
$ cat /etc/zookeeper/conf/myid # on kafka-2
2
$ cat /etc/zookeeper/conf/myid # on kafka-3
3
到这里 zookeeper 的基本配置就完成了。
1.2 SASL 鉴权
完成基本配置后 zookeeper 就可以正常使用了,但问题是只要能访问到 zookeeper 的端口,谁都可以使用,没有校验机制,这是不可接受的。zookeeper 和 kafka 提供了两种安全验证机制:SSL 和 SASL,本文中使用的是 SASL,安全性上应该是 SSL 更好,不过 SASL 配置起来相对简单,所以暂时选用了 SASL。
zookeeper 为了实现 SASL 功能,需要引入一些 JAR 包,我把这些文件上传到了百度云盘,大家可以通过这个链接进行下载:
zookeeper-sasl-jar.tar.gz
下载后解压,并放到 zookeeper 的安装目录:
$ tar zxvf zookeeper-sasl-jar.tar.gz
$ sudo mv sasl /etc/zookeeper/
然后修改 zoo.cfg 文件:
$ cat /etc/zookeeper/conf/zoo.cfg
......
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
requireClientAuthScheme=sasl
jaasLoginRenew=3600000
接下来添加 jaas.conf 文件:
$ cat /etc/zookeeper/conf/jaas.conf
Server {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-sec"
user_kafka="kafka-sec"
user_producer="prod-sec"
user_consumer="cons-sec";
};
最后修改还需要修改 environment 文件,来加载之前的 jar 文件和 jaas.conf 文件。
$ cat /etc/zookeeper/conf/environment
......
JAVA_OPTS=" -Djava.security.auth.login.config=$ZOOCFGDIR/jaas.conf "
for i in "$ZOOCFGDIR"/../sasl/*.jar; do
CLASSPATH="$i:$CLASSPATH"
done
SERVER_JVMFLAGS=" -Djava.security.auth.login.config=$ZOOCFGDIR/jaas.conf "
重启 zookeeper 完成配置:
$ sudo systemctl restart zookeeper.service
1.3 修改 systemd service 文件
zookeeper 的默认 systemd service 是自动生成的,为了实现 zookeeper service 启动失败后,可以自动重试,需要对配置文件做些修改。
$ cat /lib/systemd/system/zookeeper.service
[Unit]
Documentation=customized zookeeper service unit file
SourcePath=/etc/init.d/zookeeper
Description=LSB: centralized coordination service
Before=multi-user.target
Before=graphical.target
Before=shutdown.target
After=remote-fs.target
Conflicts=shutdown.target
[Service]
Type=forking
Restart=no
TimeoutSec=5min
IgnoreSIGPIPE=no
KillMode=process
GuessMainPID=no
RemainAfterExit=yes
ExecStart=/etc/init.d/zookeeper start
ExecStop=/etc/init.d/zookeeper stop
ExecReload=/etc/init.d/zookeeper restart
KillMode=process
Restart=on-failure
RestartSec=5s
$ sudo systemctl daemon-reload
$ sudo systemctl restart zookeeper.service
1.4 验证
最后验证一下 zookeeper 集群是否正常运行,在三台服务器上分别执行执行脚本 zkServer.sh,集群中应该有显示为 leader,也有显示为 follower 的服务器。
$ /usr/share/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
leader
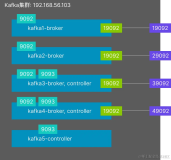
2. Kafka 集群
Kafka 也是要在全部三台服务器上都要安装,所以没有特殊说明,本节的所有操作在所有节点上都要做。
2.1 Kafka 集群安装
Kafka 没有集成到 APT 中,所以从 Kafka 的官方下载地址下载即可,另外国内的化,改用清华的镜像源会快很多(下面的例子中用的就是清华的下载源)。
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
$ tar zxvf kafka_2.11-2.0.0.tgz
$ sudo mv kafka_2.11-2.0.0 /opt/
$ cd /opt
$ sudo ln -s kafka_2.11-2.0.0 kafka
另外 Kafka 的版本查看也颇为个性,一不留神就弄错了。Kafka 是没有一个 $ kafka --version 之类的命令可用,版本完全就是看下载的 Kafka 安装包:kafka_2.11-2.0.0.tgz ,这里面有两个数字,2.11 和 2.0.0,其中 2.11 是 Scala 的版本,2.0.0 才是 Kafka 的版本,大家一定要留意。
接下来配置服务器设置,主要有两点需要注意:
-
- 这三个参数都是用来配置 Kafka 的默认 Topic:__consumer_offsets,用来存储消费者状态,这三个参数的默认配置为 1,也就是说数据只有一个备份,这在生产环境下当然是不够安全的,建议改为 3。
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
-
- 注意替换
<id>,和 zookeeper 的 Myid 文件类似,也是给每个 Kafka broker 节点一个唯一的数字标识,在本文中,由于一共三个节点,每个节点上只有一个 broker,所以三台虚拟机设置为1, 2, 3即可。
- 注意替换
$ cat /opt/kafka/config/server.properties
......
listeners=SASL_PLAINTEXT://kafka-<id>:9092
zookeeper.connect=kafka-1:2181,kafka-2:2181,kafka-3:2181
broker.id=<id>
advertised.listeners=kafka-<id>:9092
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
2.2 SASL 设置
Kafka 当然要配置用户名密码,设置方式和上面的 zookeeper 类似。先来讲讲 jaas.conf 文件:
-
KafkaServer部分是用来让 Kafka broker 之间互连鉴权使用的,username和password是设置当前 broker 自身的用户名密码,user_admin=“admin-sec”则指明连接其他 broker 时用的用户名是admin,密码是admin-sec。 -
Client部分是负责设置 Kafka 客户端(也就是 producer 和 consumer,以及一些 metrics exporter),连接 Kafka broker 时使用的密码。
$ cat /opt/kafka/config/jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-sec"
user_admin="admin-sec"
user_kafka="kafka-sec"
user_producer="prod-sec"
user_consumer="cons-sec";
};
Client {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="kafka"
password="kafka-sec";
};
jaas 文件配置好后,server.properties 文件也要做对应的修改:
$ cat /opt/kafka/config/server.properties
......
listeners=SASL_PLAINTEXT://kafka-<id>:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
allow.everyone.if.no.acl.found=true
advertised.listeners=SASL_PLAINTEXT://kafka-<id>:9092
因为 Kafka 配置了密码,Kafka 的客户端连接 broker 也需要设置响应的密码,所以 consumer 和 producer 的配置里也要加上这些信息才能正常使用。
$ cat /opt/kafka/config/producer.properties
......
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="kafka" \
password="kafka-sec";
$ cat /opt/kafka/config/consumer.properties
......
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="kafka" \
password="kafka-sec";
2.3 systemd service 文件
要保证 Kafka 能够每次虚拟机重启后都能自动启动,并且服务失败后,也会尝试重启,就要使用 systemd 来进行管理了,添加如下文件,并重启 Kafka。
$ cat /lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
Documentation=http://kafka.apache.org/documentation.html
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=root
Group=root
Environment=JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
Environment=KAFKA_OPTS=-Djava.security.auth.login.config=/opt/kafka/config/jaas.conf
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target
$ sudo systemctl enable kafka.service
$ sudo systemctl start kafka.service
2.4 验证 Kafka 是否正常工作
运行以下命令查看 Kafka broker 节点列表,如果显示如下,证明已经三个节点都已经运行成功了。
$ /opt/kafka/bin/zookeeper-shell.sh localhost:2181 <<< "ls /brokers/ids"
Connecting to localhost:2181
Welcome to ZooKeeper!
JLine support is disabled
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[1, 2, 3]
3. 自动化
在 OpenStack 环境下使用 Kafka 集群必然不会是装好了就完事,而是需要把 Kafka 做成模板镜像,可以自动化的启动。经过上面的安装步骤,我们已经有了可用的 Kafka 虚拟机,虚拟机做快照,然后上传成镜像即可,接下来看看在镜像启后如何修改 Kafka 实例的信息,让其组成集群。下面这个 shell 脚本可以实现在启动时修改个性化信息的作用,需要在 OpenStack 启动实例时,通过 CloutInit 注入到虚拟机实例中。需要提前将该脚本放在虚拟机的 /usr/bin/ 目录下,调用方式如下:
$ /usr/bin/kafka-init.sh <server-id> <cluster-name> <kafka-1-ip> <kafka-2-ip> <kafka-3-ip> ......
解释一下上面命令参数的含义:
-
<server-id>:虚拟机在 kafka 集群中的唯一标识,取值范围为:1~255。 -
<cluster-name>:Kafka 集群的名字,主要用来配置集群中虚拟机的主机名,和<server-id>配合使用,例如<server-id>取值为 1,<cluster-name>取值为 "Kafka",那么该主机的主机名就会设置为:Kafka-1。 -
<kafka-1-ip>:Kafka 集群中虚拟机节点的 IP 地址。
该脚本支持启动多于多于个节点的 Kafka 实例自动创建,最大值限制为 10 个节点,只要资源足够,也可以放宽上限的限制。
#!/bin/bash
PARAM_NUM=$#
if [[ "$PARAM_NUM" -le 4 ]] || [[ "$PARAM_NUM" -gt 12 ]]; then
echo "Failed. Kafka cluster require at least 3 nodes and no more than 10 nodes. Your input is: $@"
exit 0
fi
MYID=$1
CLUSTER_NAME=$2
HOST_NAME=$CLUSTER_NAME"-"$MYID
sudo echo $MYID > /etc/zookeeper/conf/myid
sudo hostname $HOST_NAME
sudo bash -c "echo $HOST_NAME > /etc/hostname"
sudo sed -i "s/kafka\-1/$HOST_NAME/g" /opt/kafka/config/server.properties
sudo sed -i "s/broker.id=0/broker.id=$MYID/g" /opt/kafka/config/server.properties
declare -a servers
index=0
for param in $@
do
if [[ $index -gt 1 ]]; then
eval "KAFKA_$((index-1))_IP=$param"
echo "$param $CLUSTER_NAME-$((index-1))"
echo "$param $CLUSTER_NAME-$((index-1))" >> /etc/hosts
echo "server.$((index-1))=$CLUSTER_NAME-$((index-1)):2888:3888"
echo "server.$((index-1))=$CLUSTER_NAME-$((index-1)):2888:3888" >> /etc/zookeeper/conf/zoo.cfg
servers=("${servers[@]}" "$CLUSTER_NAME-$((index-1)):2181")
echo ${servers[@]}
fi
index=$((index+1))
echo $param
done
function join_by { local IFS="$1"; shift; echo "$*"; }
zookeeper_connect_str="zookeeper.connect="`join_by , ${servers[@]}`
echo $zookeeper_connect_str
echo $zookeeper_connect_str >> /opt/kafka/config/server.properties
sudo systemctl restart zookeeper.service
sleep 2
sudo systemctl restart kafka.service
sudo rm -f /usr/bin/kafka-init.sh
4. 连接测试
Kafka 集群已经就绪,接下来让我们用自带的 consumer 和 producer 客户端实际测试一下,看看 Kafka 能不能正常工作。先来创建一个名为 test 的 topic。
$ /opt/kafka/bin/kafka-topics.sh --create --zookeeper kafka-1:2181 --topic test --partitions 3 --replication-factor 3
$ /opt/kafka/bin/kafka-topics.sh --list --zookeeper kafka-1:2181
test
再非别启动 consumer 和 producer,在 producer 启动后出现的命令行中输入一些信息,consumer 中能正常读取到,那么就证明 Kafka 的基本功能没有问题了。
$ /opt/kafka/bin/kafka-console-producer.sh --broker-list kafka-1:9092,kafka-2:9092,kafka-3:9092 --topic test --producer.config /opt/kafka/config/producer.properties
> abc
> def
> ghi
$ /opt/kafka/bin/kafka-console-consumer.sh --consumer.config /opt/kafka/config/consumer.properties --bootstrap-server kafka-1:9092,kafka-2:9092,kafka-3:9092 --from-beginning --topic test
abc
def
ghi
3. 参考文档
- Setting up Apache ZooKeeper Cluster | Apache ZooKeeper Tutorials
- how to check if zookeeper is running or up from command prompt
- How to Configure an Apache Kafka Cluster on Ubuntu 16.04
- Kafka And Zookeeper Multi Node Cluster Setup
- Client-Server mutual authentication
- 集群Kafka配置SASL用户名密码认证
- Kafka认证处理,ACL访问控制
- Authentication using SASL
- Zookeeper权限管理之坑
- Introduction to Apache Kafka Security
- Zookeeper - Super User Authentication and Authorization