丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
在IDEA中借助满血版 DeepSeek 提高编码效率
详解大模型应用可观测全链路
【自定义插件系列】0基础在阿里云百炼上玩转大模型自定义插件
大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
解决隐式内存占用难题
监控vLLM等大模型推理性能
阿里云资深架构师经验分享——DevSecOps最佳实践
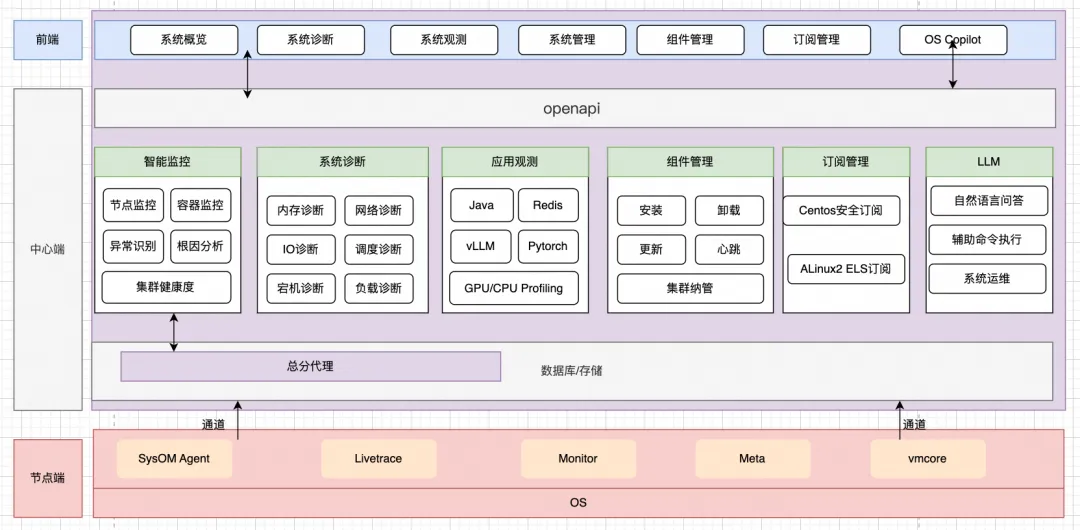
AI 推理场景的痛点和解决方案
PaperBench:OpenAI开源AI智能体评测基准,8316节点精准考核复现能力
DeepSite:基于DeepSeek的开源AI前端开发神器,一键生成游戏/网页代码
Mini DALL·E 3:设计师福音!开源AI绘画神器:对话式修图+智能问答,草图秒变商业大作
Dolphin:40语种+22方言!清华联合海天瑞声推出的语音识别大模型,识别精度超Whisper两代
DreamActor-M1:字节跳动推出AI动画黑科技,静态照片秒变生动视频
WorldScore:斯坦福开源世界生成模型评估新标杆:3000样本+九维指标,视频/4D/3D模型一网打尽
SWEET-RL:8B小模型暴打GPT-4?Meta开源强化学习黑科技,多轮任务成功率飙升6%
OPPO联合港科大推出多模态推理优化框架 OThink-MR1:让AI学会『举一反三』,几何推理准确率暴增
EasyControl Ghibli:在线体验一键生成宫崎骏动画风,开源AI模型让你的照片秒变吉卜力
[oeasy]python083_类_对象_成员方法_method_函数_function_isinstance
在CentOS 7.9中安装sshpass教程
Ubuntu中dpkg和apt命令:debian包安装详解
如何克服HTTP协议的无状态问题
利用PHP压缩音频:Linux环境下的ffmpeg简易安装指南
Java LinkedList集合的深度剖析
Python + 腾讯云,多页PDF发票识别一键搞定!
《敏感数据的保护伞:SQL数据脱敏全解析》
《深度剖析Spark SQL:与传统SQL的异同》
《深度洞察:Hadoop生态系统与SQL的奇妙联动》
《深度探秘:SQL助力经典Apriori算法实现》
《深度剖析:关联规则挖掘与SQL的奇妙融合》
开箱即用的可视化AI应用编排工具 Langflow,可调用魔搭免费API作为tool
一文掌握 MCP 上下文协议:从理论到实践
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
Apache Doris 2.1.9 版本正式发布
Text2SQL圣经:从0到1精通Text2Sql(Chat2Sql)的原理,以及Text2Sql开源项目的使用
【产品小贴士】: 智能搜索
Vim操作指令全解析
从命名约定到特殊方法,Python下划线符号的妙用!
如何删除Debian中的用户?删除Debian用户方法
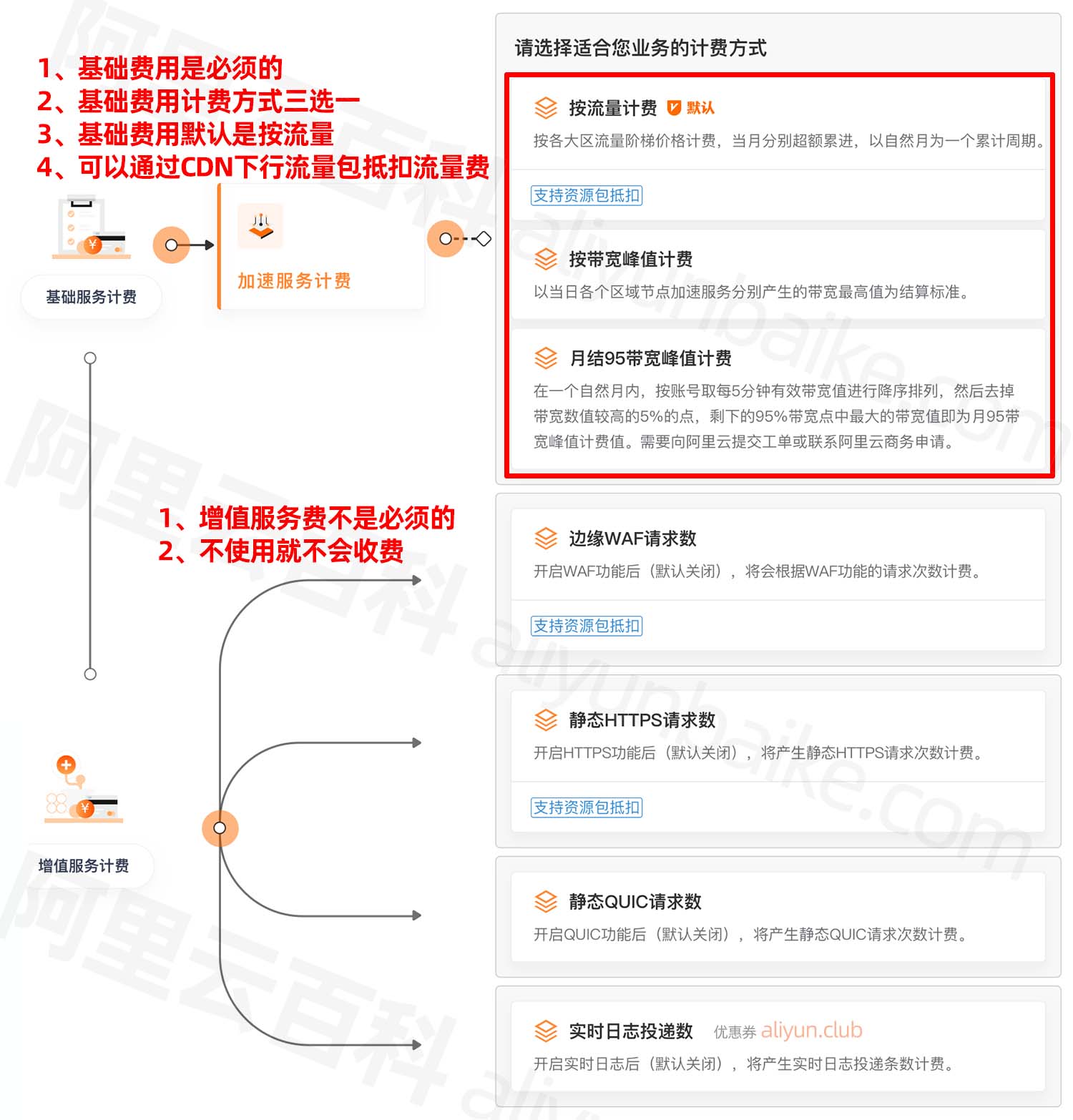
阿里云CDN怎么收费?看这一篇就够了,CDN不同计费模式收费价格全解析
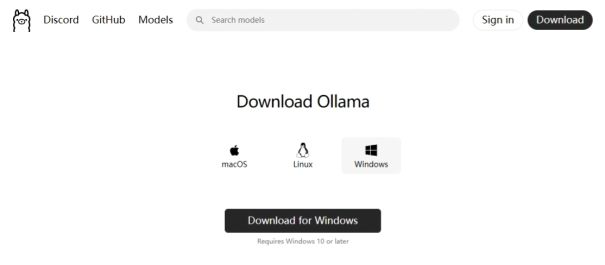
本地部署DeepSeek教程:一键远程访问,还能解决Ollama安全隐患
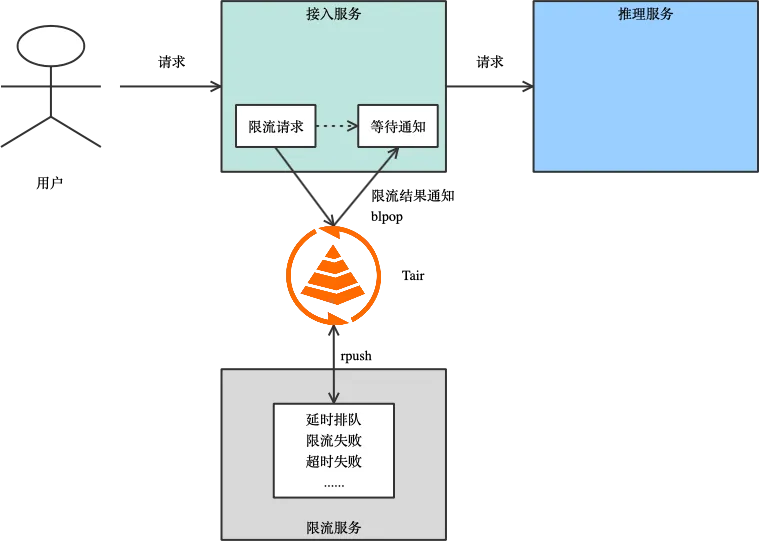
文生图架构设计原来如此简单之交互流程优化
一文了解:阿里云对象存储OSS是什么?
函数计算支持热门 MCP Server 一键部署
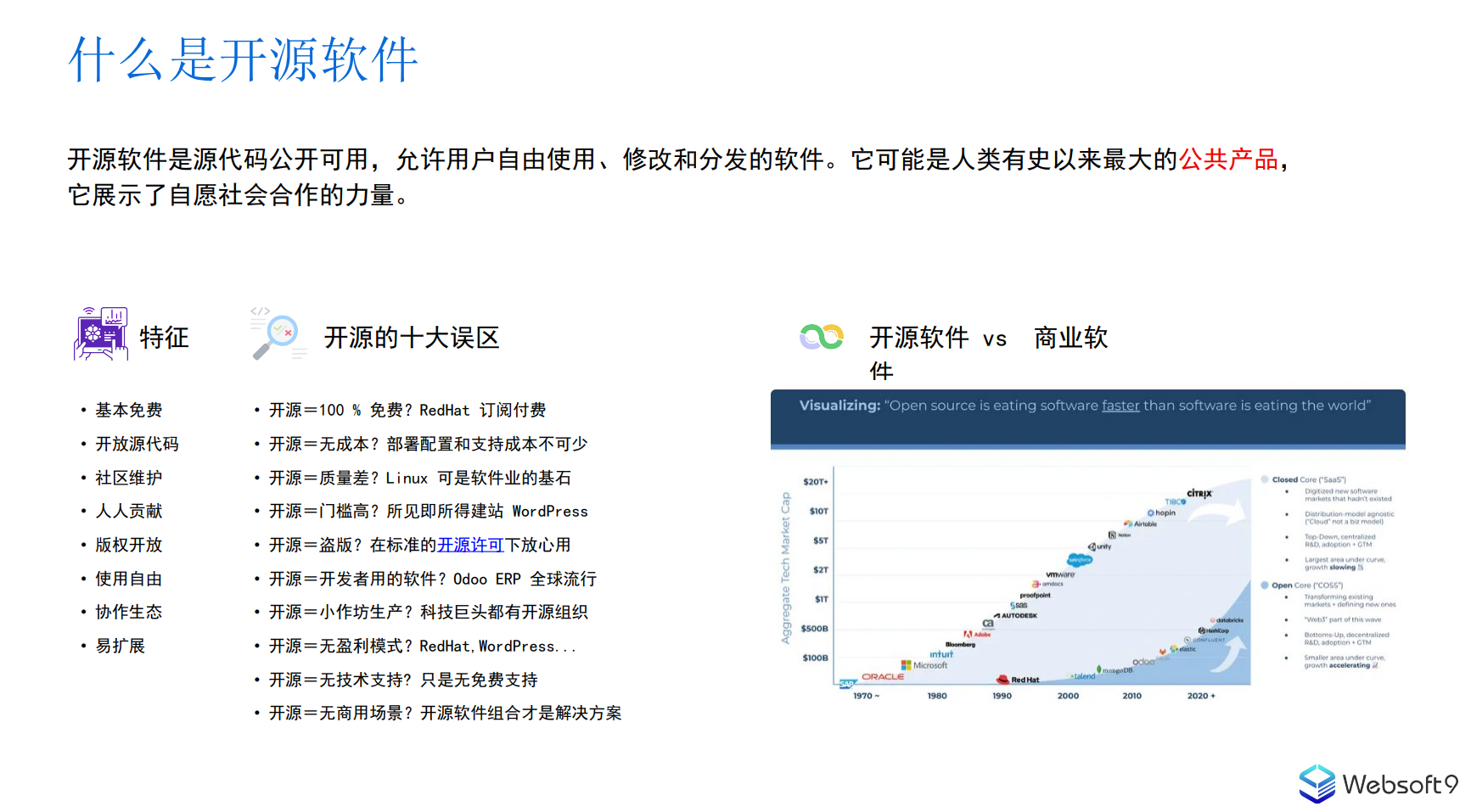
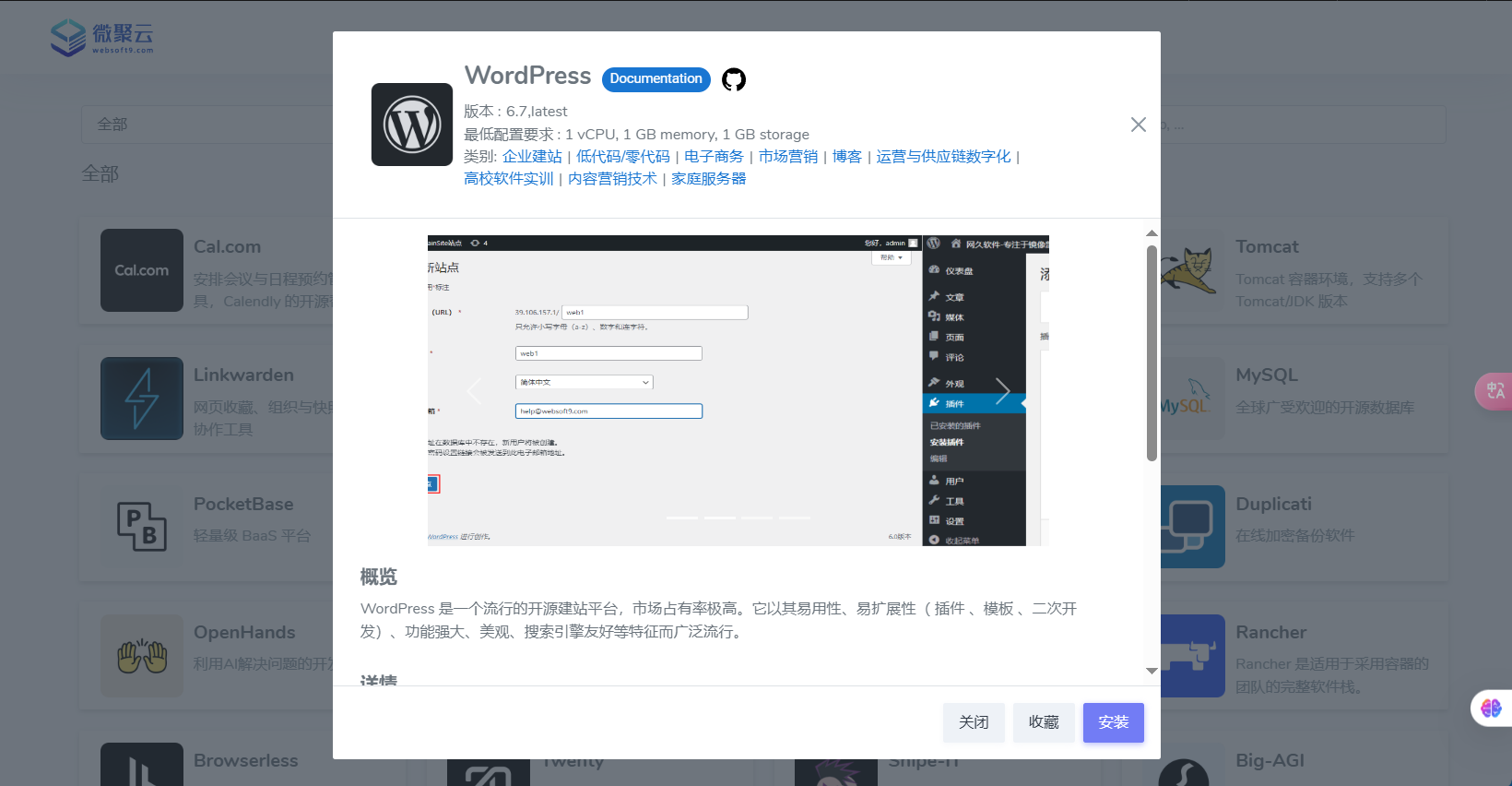
Websoft9分享:在数字化转型中选择开源软件可能遇到的难题
中小企业数字化转型的本质:在Websoft9应用平台上实现开源工具与商业软件的统一
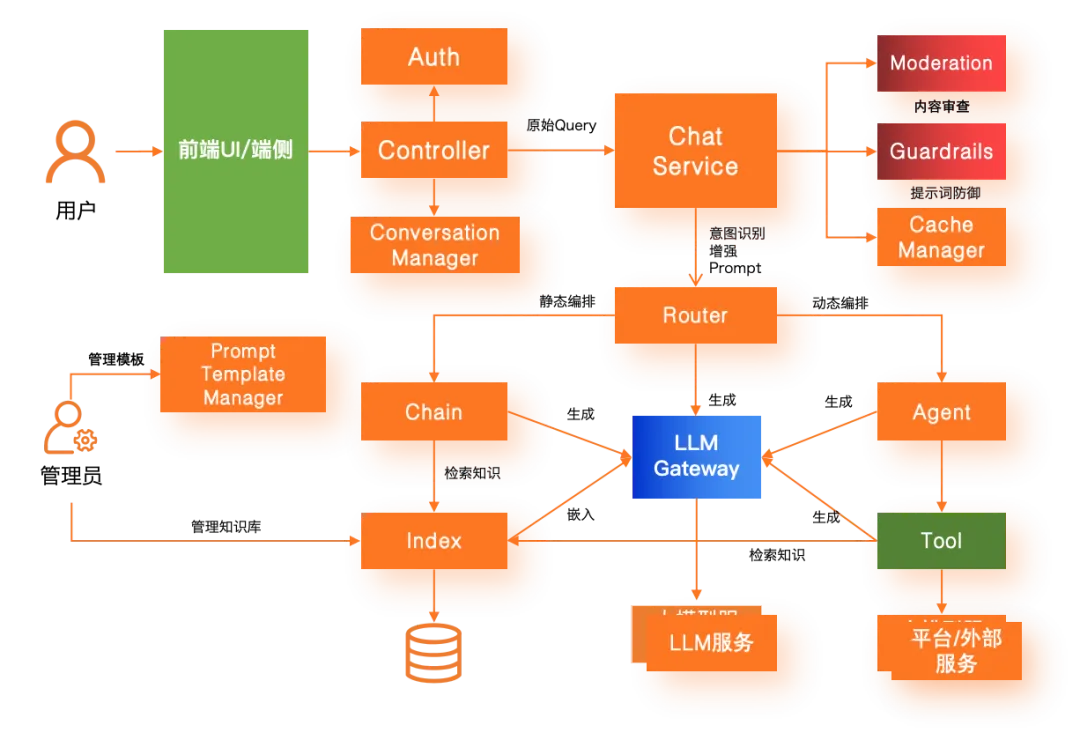
AI 网关代理 LLMs 最佳实践
借助 Websoft9 的开源应用平台,中小企业数字化转型无需犹豫等待
撤了!6天搬走500台VMware虚拟机
推荐一款医疗级心电采集处理模块
普通人用DeepSeek的20个神仙操作,看完效率翻倍!
社区积分兑好礼