丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
Hi3DGen:2D照片秒变高精度模型,毛孔级细节完爆Blender!港中文×字节×清华联手打造3D生成黑科技
《深度探索:运用游标遍历数据库树形结构数据的艺术》
《深度剖析:SQL中游标与临时表的数据处理对决》
《深度探秘:借助游标解锁SQL数据批量更新的高阶玩法》
《深度洞察:MySQL与Oracle中游标的性能分野》
《深度剖析SQL游标:复杂数据处理场景下的智慧抉择》
RAG 调优指南:Spring AI Alibaba 模块化 RAG 原理与使用
AReaL-boba:仅用200条数据复现32B模型效果!蚂蚁清华联手打造强化学习+数据蒸馏框架,7B模型数学推理碾压同级
OpenDeepSearch:搜索引擎革命!这个开源深度搜索工具让AI代理直接读懂网页,复杂问题一键拆解
异步读取HTTP响应体的Rust实现
HTTP代理:网页加速的隐形引擎
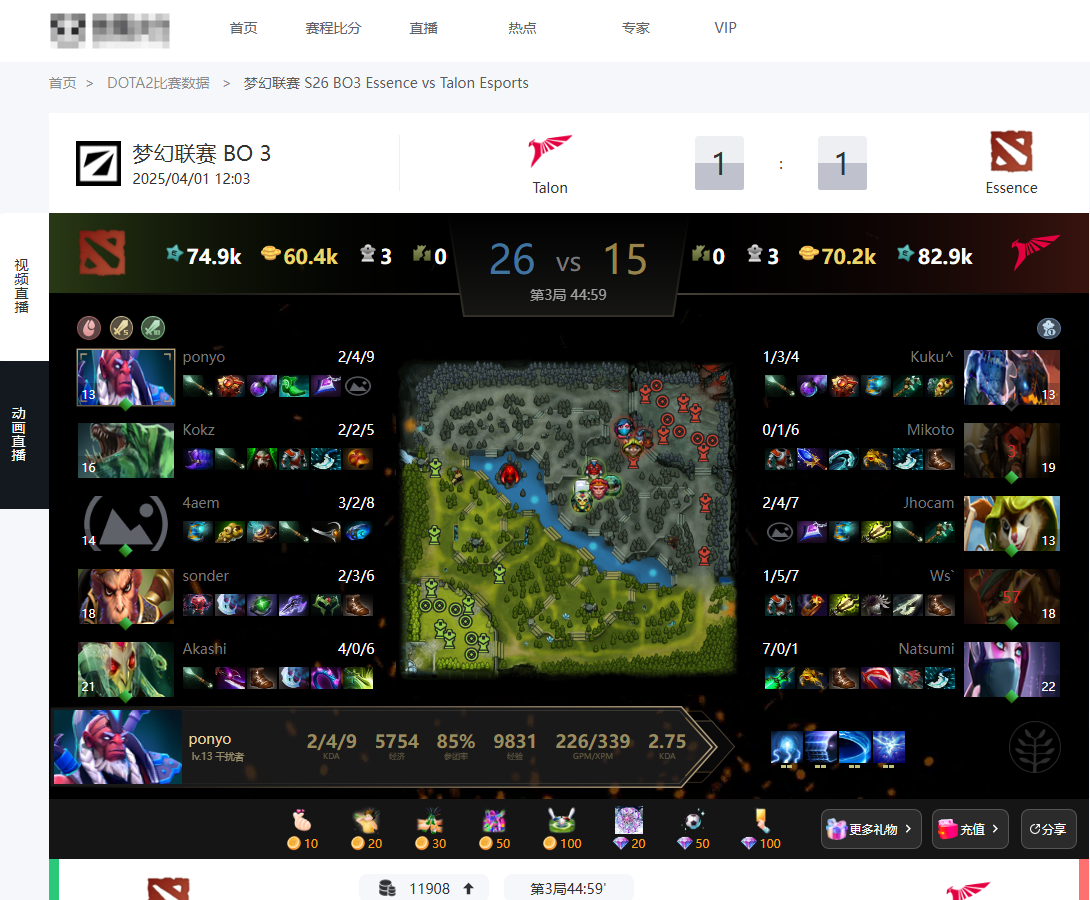
怎么实现实时无延迟的体育电竞动画直播
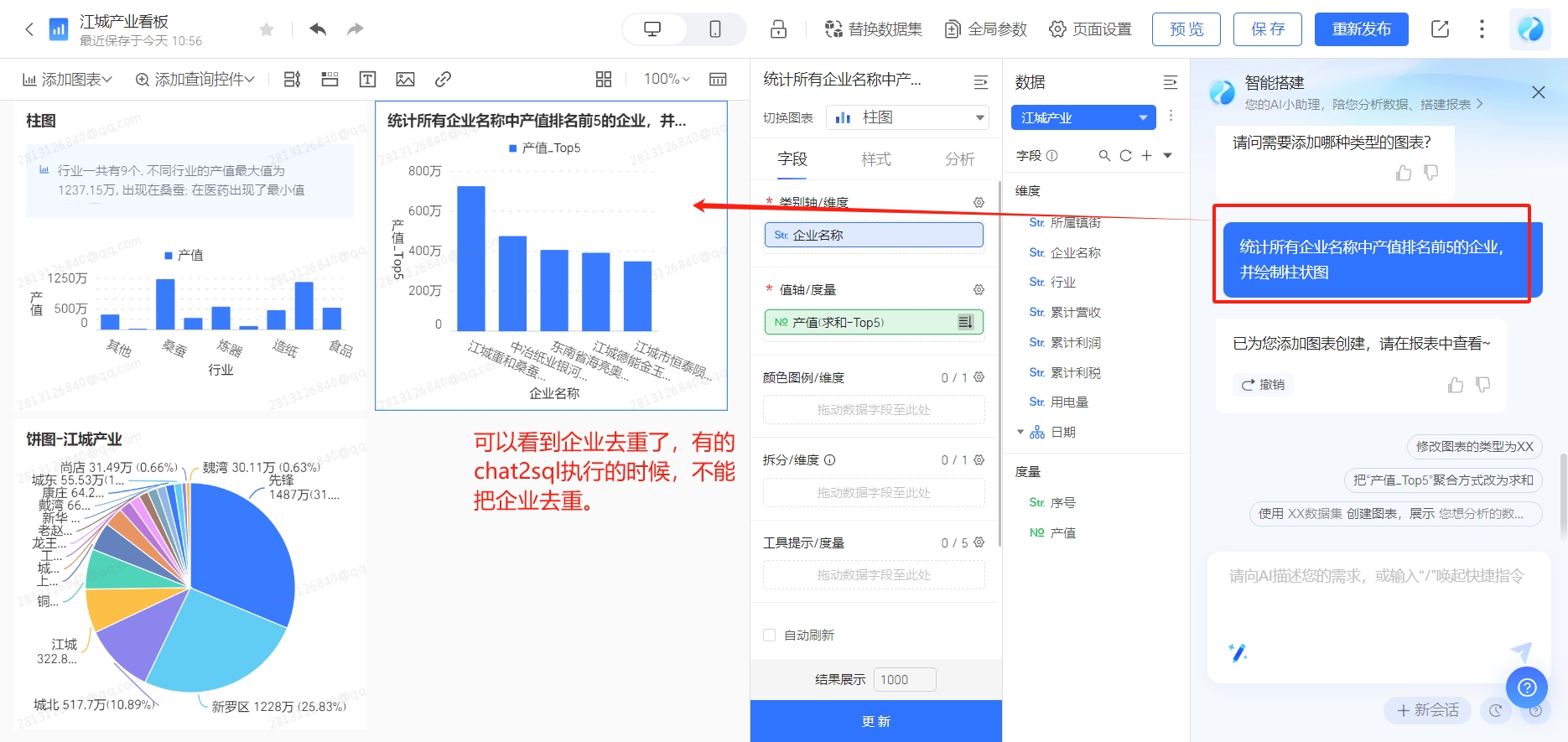
Chat2报表2图表!!业务管理系统智能化升级、满足创新需求的必备
云工开物高校激励计划|第十期获奖名单
AI的出现,让月入几万的程序员,要被AI取代了?
5款知名度不高,但很好用的软件
官网突然“涉黄”,一场安全漏洞引发的品牌危机
AI的出现,如何判定程序员的水平高不高?
幻兽帕鲁服务端性能优化mod
AI训练师入行指南(六):模型部署
【AI大模型】使用Python调用DeepSeek的API,原来SDK是调用这个,绝对的一分钟上手和使用
没有好的学历,Java开发未来的路应该怎么走?
蓝耘智算:开启智能算力新时代
Java程序员在AI时代必会的技术:Spring AI
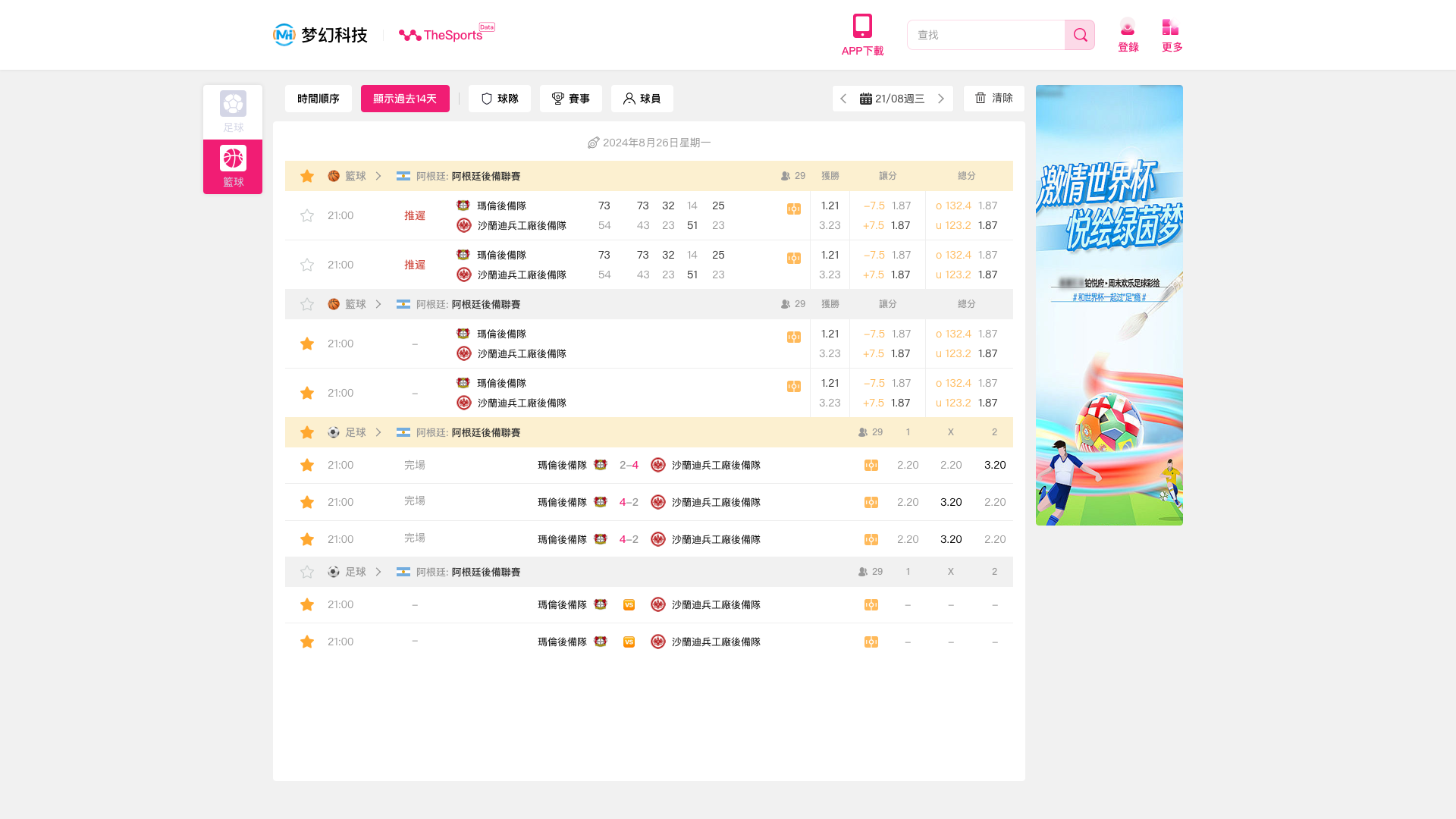
开发体育直播即时比分系统:赛事收藏功能的技术实现方案
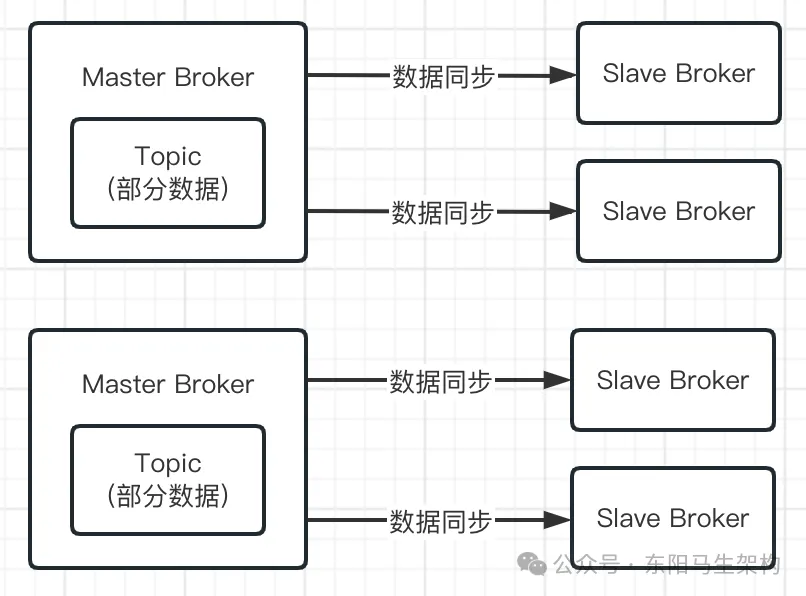
RocketMQ原理—1.RocketMQ整体运行原理
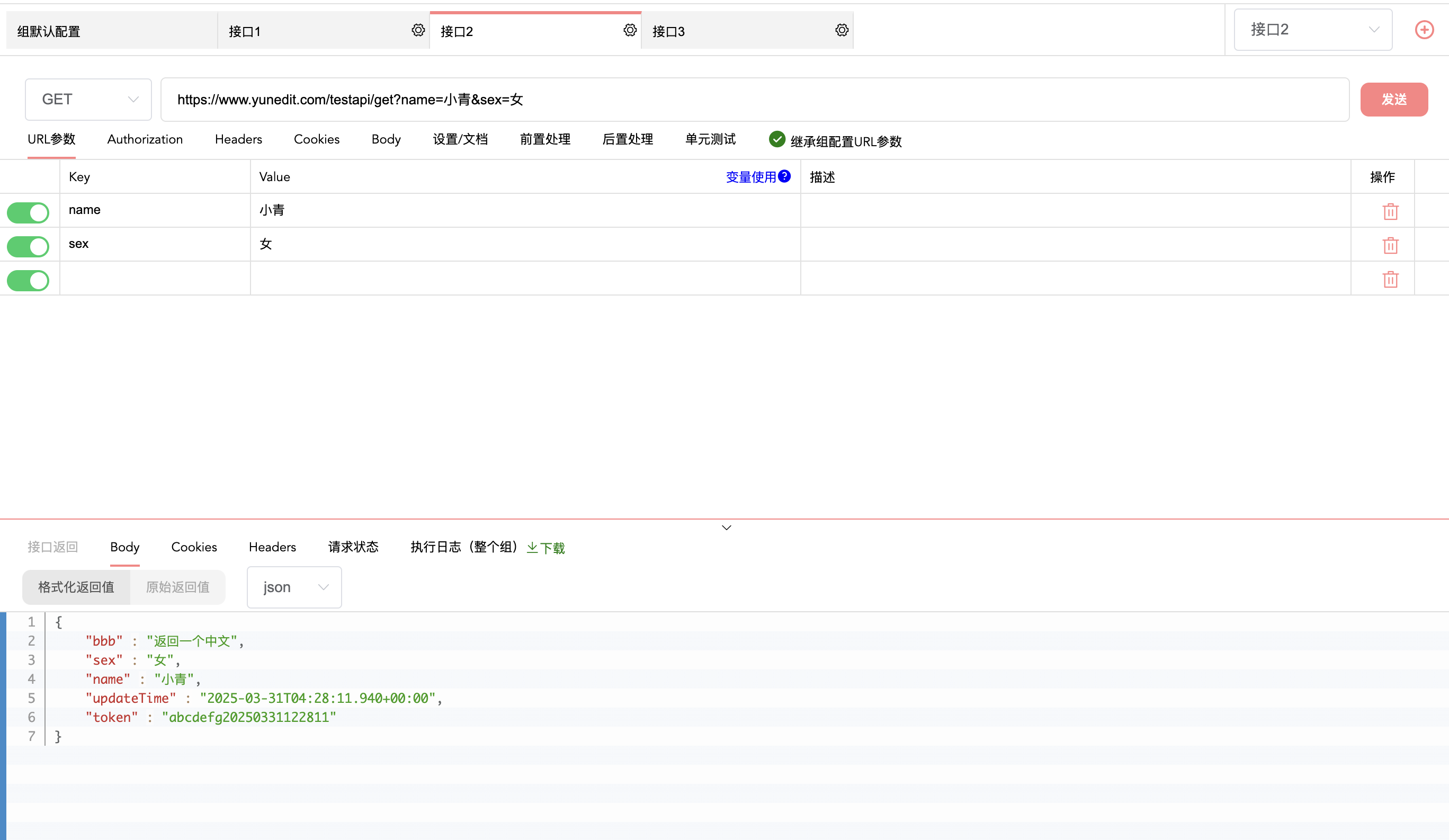
除了postman还有什么接口测试工具
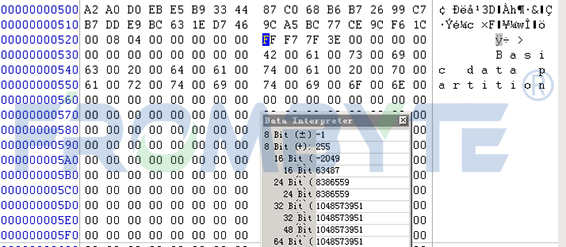
服务器数据恢复—NTFS分区误格式化数据怎样挽回?
通义灵码助力技术求职:如何成为笔试面试冲刺的“超级助手”
基于Python+Vue开发的鲜牛奶订购管理系统源码+运行
CALIPSO激光雷达1B级剖面数据 - CAL_LID_L1-Standard-V4-10
OpenCore Legacy Patcher 2.3.0 发布,重点优化对 macOS Sequoia 15.4 的支持
Xcode 16.3 (16E140) - Apple 平台 IDE
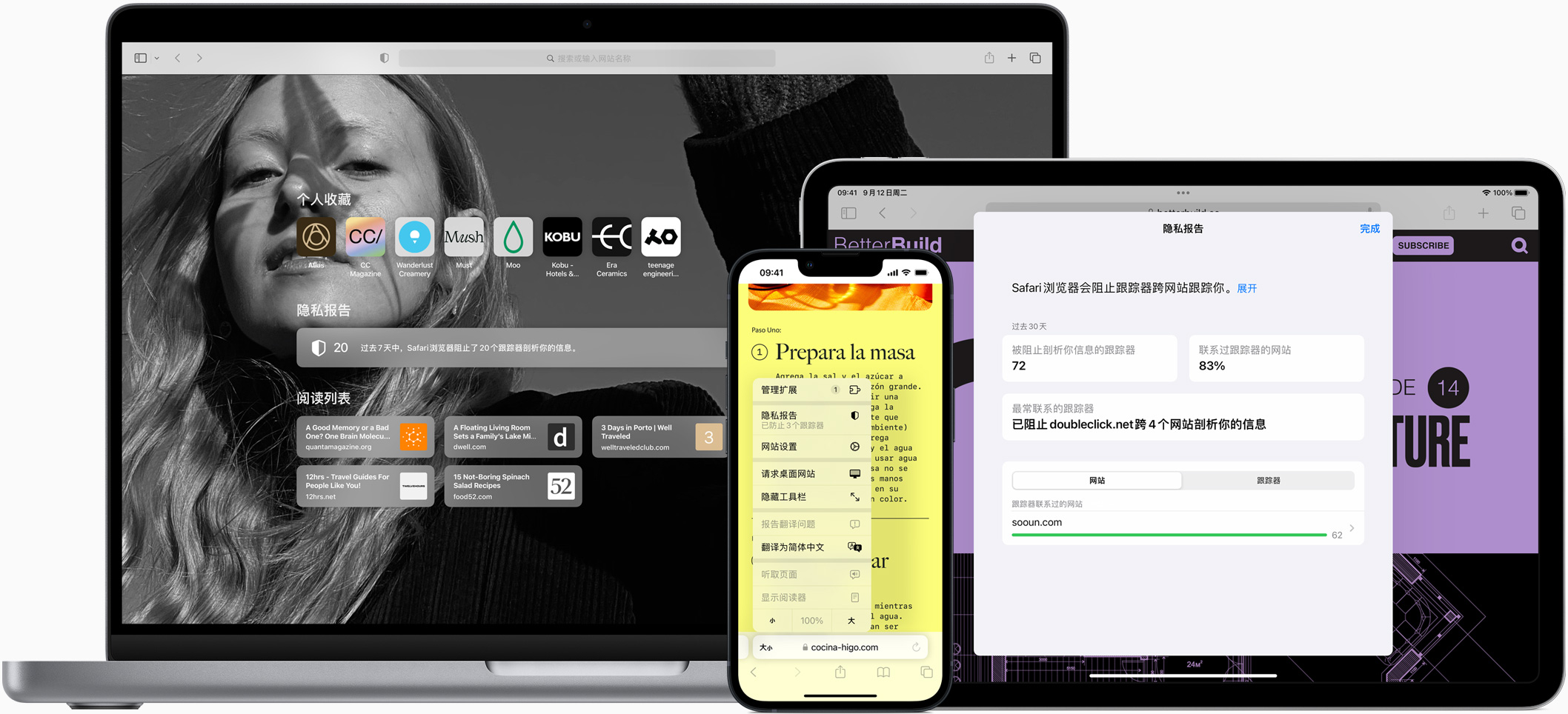
Apple Safari 18.4 - macOS 专属浏览器 (独立安装包下载)
macOS Ventura 13.7.5 (22H527) Boot ISO 原版可引导镜像下载
macOS Ventura 13.7.5 (22H527) 正式版 ISO、IPSW、PKG 下载
macOS Sonoma 14.7.5 (23H527) Boot ISO 原版可引导镜像下载
macOS Sonoma 14.7.5 (23H527) 正式版 ISO、IPSW、PKG 下载
macOS Sequoia 15.4 (24E248) Boot ISO 原版可引导镜像下载
macOS Sequoia 15.4 (24E248) 正式版 ISO、IPSW、PKG 下载
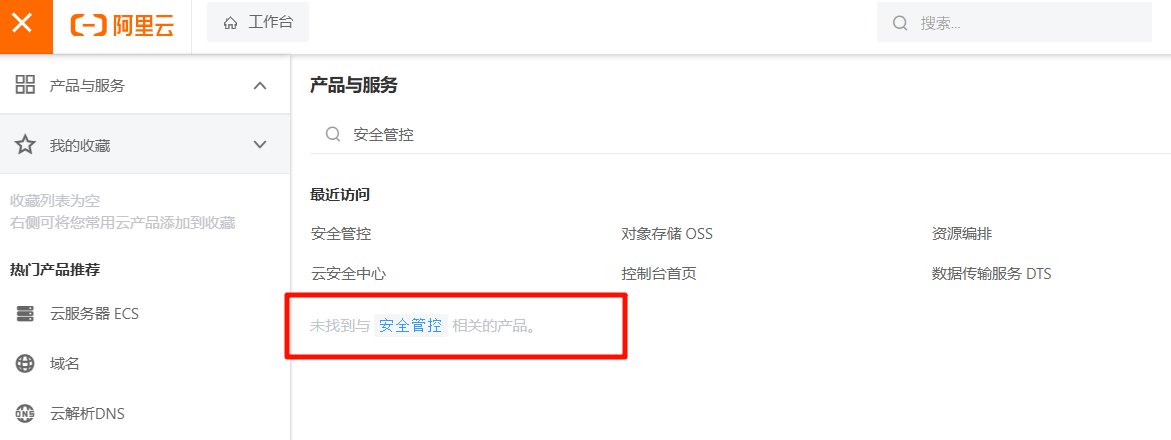
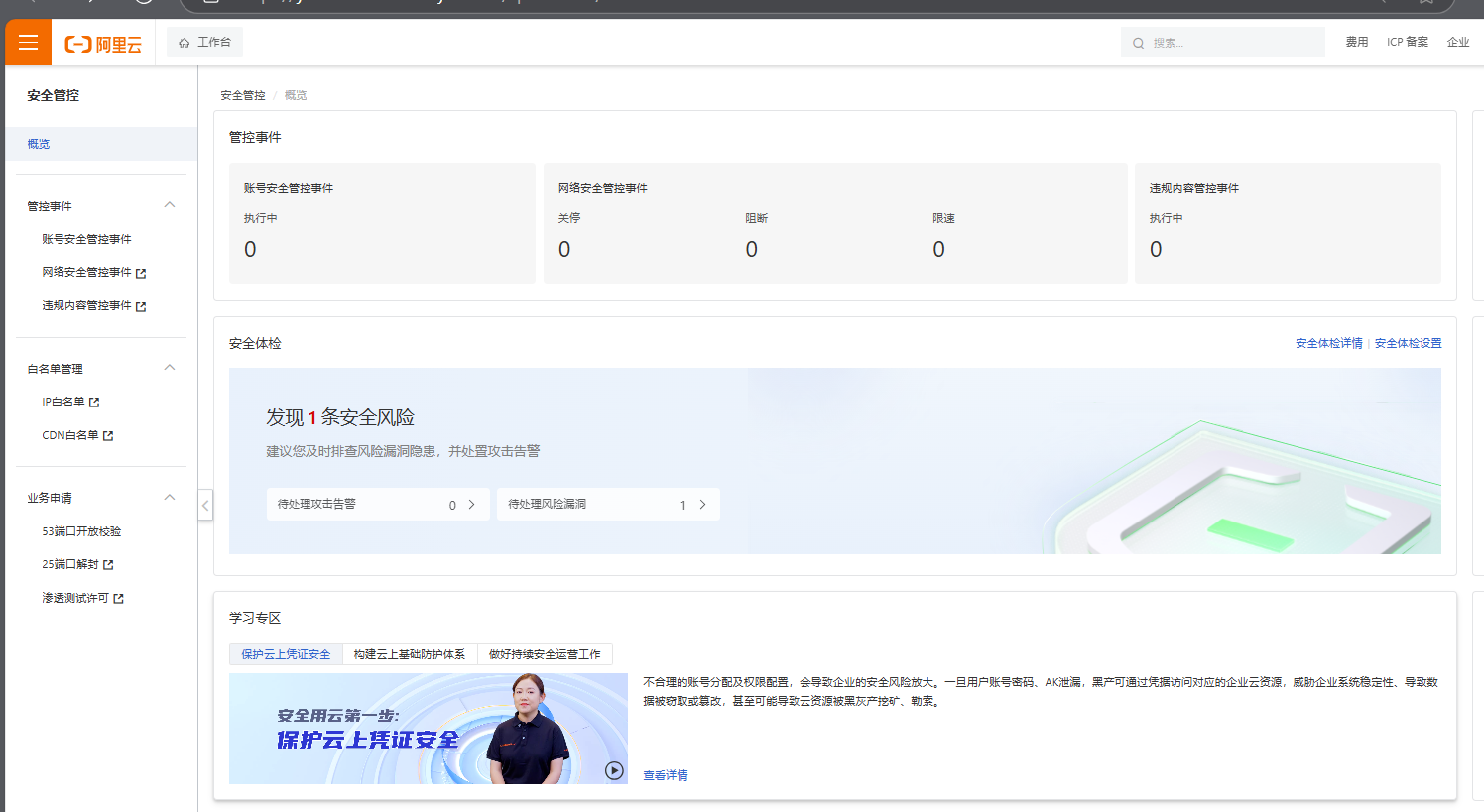
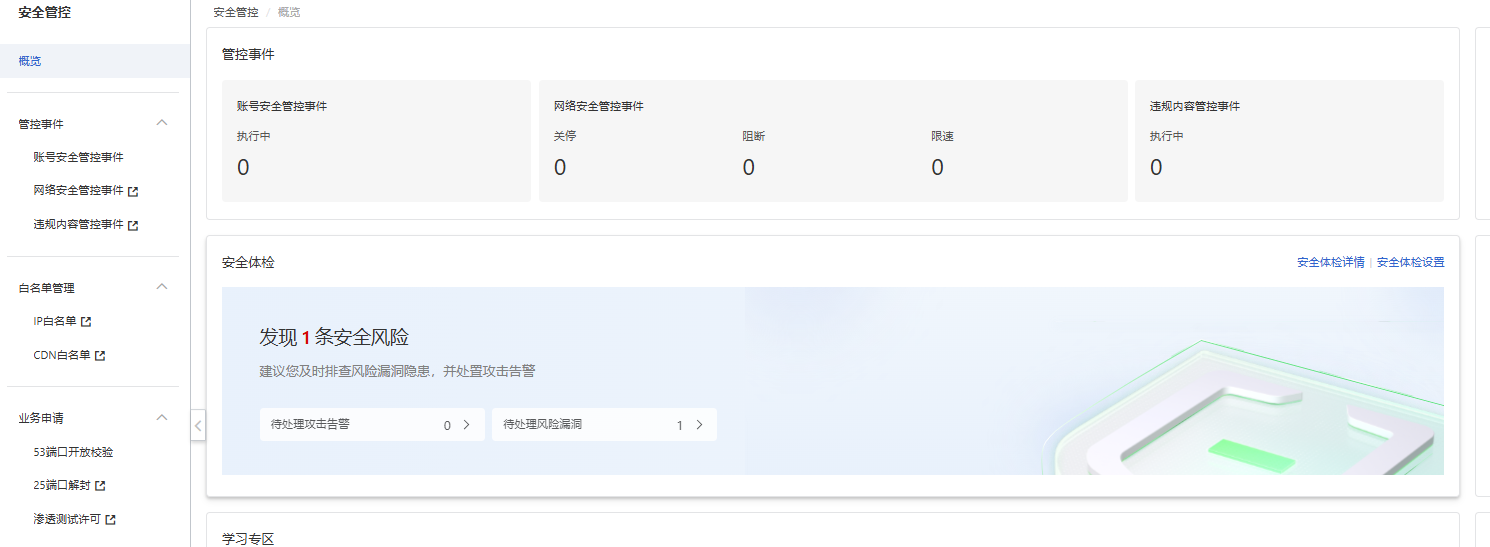
安全体检有必要,这是信息安全生命线
云产品测评——安全体检
云产品——安全体检
从 DeepSeek 敏感信息泄露谈可观测系统的数据安全预防
全球人工智能产业迎来新机遇,这些就业方向别错过,生成式人工智能认证(GAI认证)助力
推动人工智能技术和产业变革,啥是核心驱动力?生成式人工智能认证(GAI认证)揭秘答案
1688API最新指南:商品详情接口接入与应用
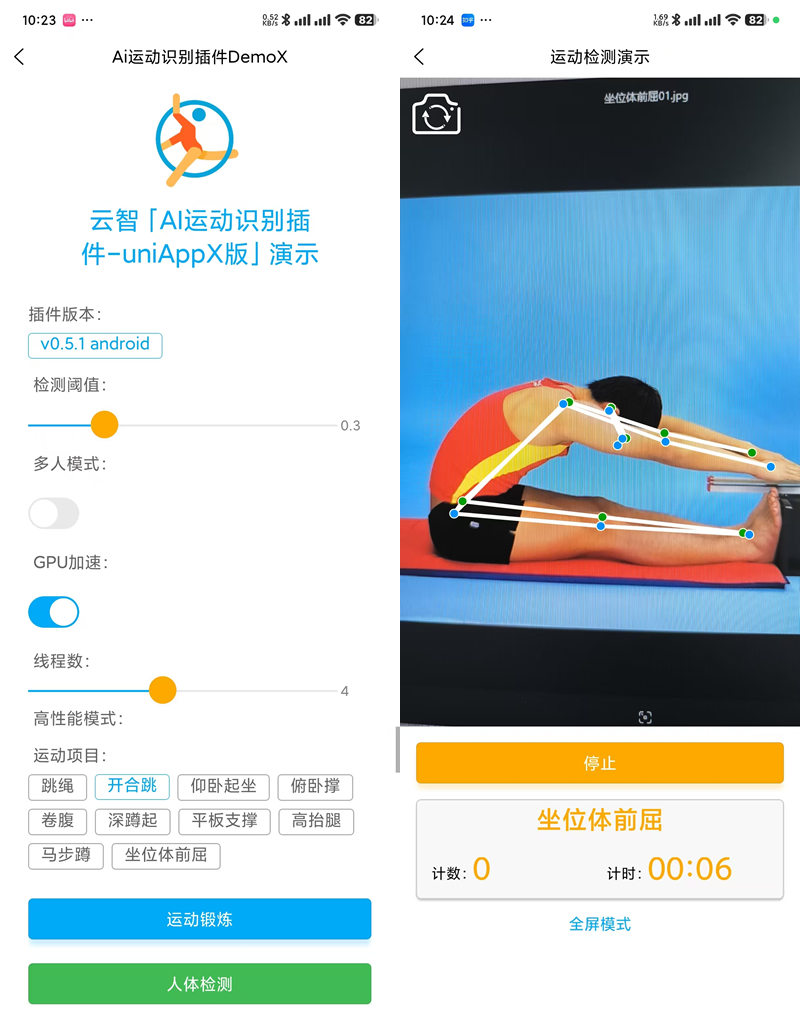
【一步步开发AI运动APP】一、写在最前
如何使用免费网站模版创建网站?
【赵渝强老师】Oracle的闪回数据库