使用MySQL JDBC读取过较大数据量的人应该清楚(例如超过1GB),在读取的时候内存很可能会Java堆内存溢出,而我们的解决方案是statement.setFetchSize(Integer.MIN_VALUE)并确保游标是只读向前滚动的即可(为游标的默认值),也可以强制类型转换为com.mysql.jdbc.StatementImpl,然后调用其内部方法:enableStreamingResults()这样读取数据内存就不会挂掉了,这两者达到的效果是一致的。当然也可以使用useCursorFetch,但是这种方式测试结果性能要比StreamResult慢很多,为什么?在本文会阐述其大致的原理。
我在前面的部分文章和书籍中都有介绍过其MySQL JDBC在这一块内部处理的代码分成三个不同的类来完成的,不过我一直没有去深究过数据库和JDBC之间到底是如何通信的过程。有一段时间我一直认为这都属于服务端行为或者是客户端与服务端配合的行为,然后并不其然,今天我们来讲一下这个行为是怎么回事。
【先回顾一下简单的通信】:
JDBC与数据库之间的通信是通过Socket完成的,因此我们可以把数据库当成一个SocketServer的提供方,因此当SocketServer返回数据的时候(类似于SQL结果集的返回)其流程是:服务端程序数据(数据库) -> 内核Socket Buffer -> 网络 -> 客户端Socket Buffer -> 客户端程序(JDBC所在的JVM内存)
到目前为止,IT行业中大家所看到的JDBC无论是:MySQL JDBC、SQL Server JDBC、PG JDBC、Oracle JDBC。甚至于是NoSQL的Client:Redis Client、MongoDB Client、Memcached,数据的返回基本也是这样一个逻辑。
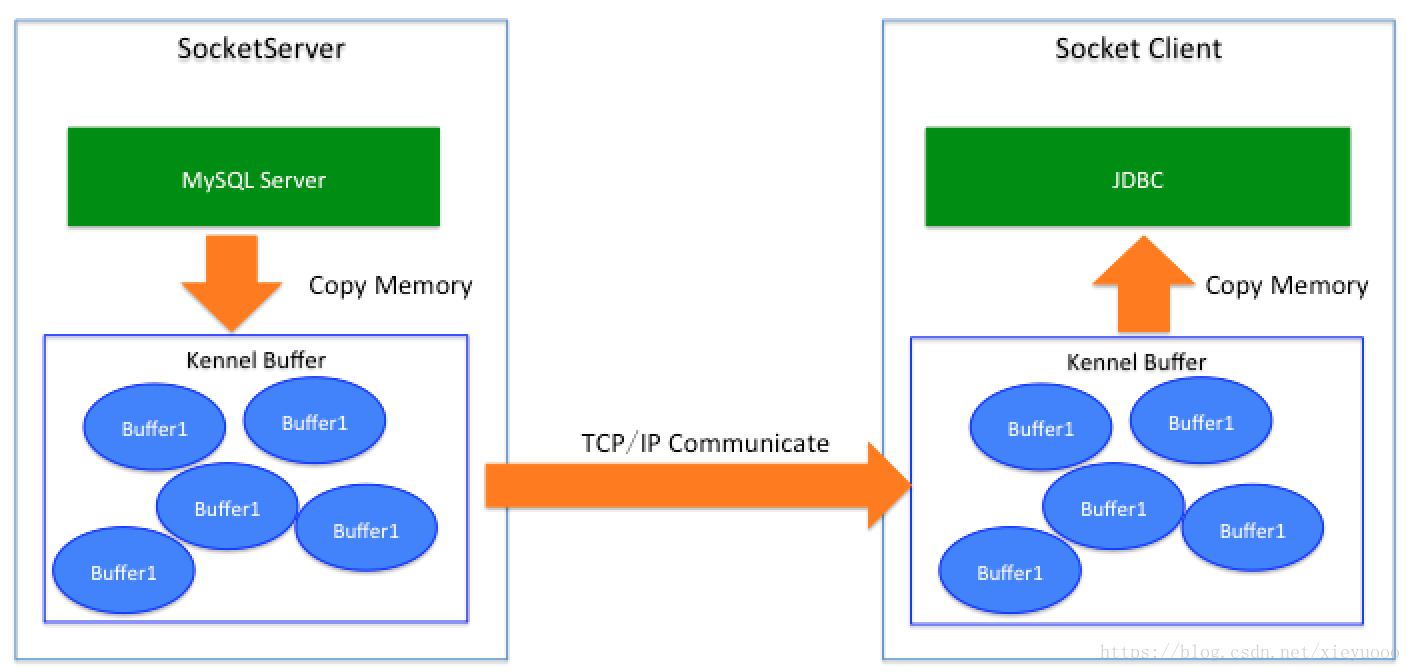
【方式1:直接使用MySQL JDBC默认参数读取数据,为什么会挂?】
(1)MySQL Server方在发起的SQL结果集会全部通过OutputStream向外输出数据,也就是向本地的Kennel对应的socket buffer中写入数据,这是一次内存拷贝(内存拷贝这个不是本文的重点)。
(2)此时Kennel的Buffer有数据的时候就会把数据通过TCP链路(JDBC主动发起的Socket链路),回传数据,此时数据会回传到JDBC所在机器上,会先进入Kennel区域,同样进入到一个Buffer区。
(3)JDBC在发起SQL操作后,Java代码是在inputStream.read()操作上阻塞,当缓冲区有数据的时候,就会被唤醒,然后将缓冲区的数据读取到Java内存中,这是JDBC端的一次内存拷贝。
(4)接下来MySQL JDBC会不断读取缓冲区数据到Java内存中,MySQL Server会不断发送数据。注意在数据没有完全组装完之前,客户端发起的SQL操作不会响应,也就是给你的感觉MySQL服务端还没响应,其实数据已经到本地,JDBC还没对调用execute方法的地方返回结果集的第一条数据,而是不断从缓冲器读取数据。
(5)关键是这个傻帽就像一把这个数据读取完,根本不管家里放不放的下,就会将整个表的内容读取到Java内存中,先是FULL GC,接下来就是内存溢出。
【方式2:JDBC参数上设置useCursorFetch=true可以解决问题】
这个方案配合FetchSize设置,确实可以解决问题,这个方案其实就是告诉MySQL服务端我要多少数据,每次要多少数据,通信过程有点像这样:
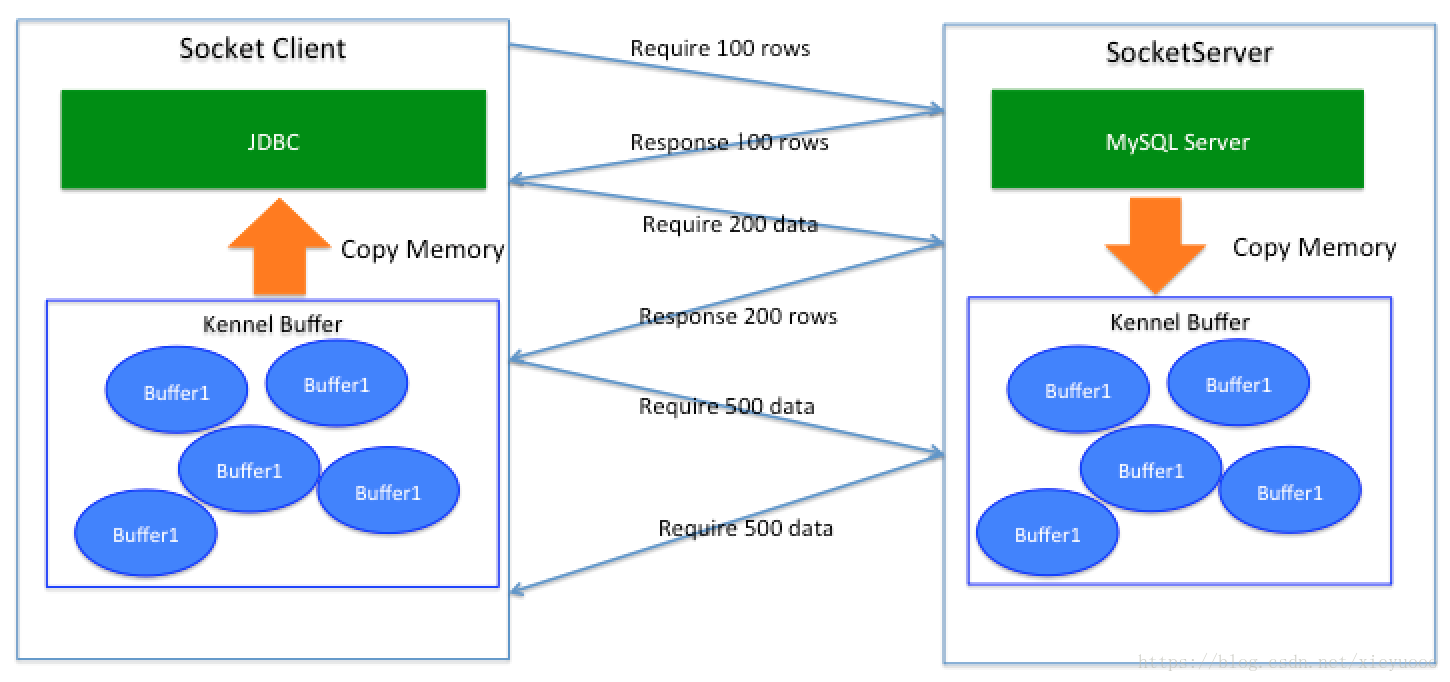
这样做就像我们生活中的那样,我需要什么就去超市买什么,需要多少就去买多少。不过这种交互不像现在网购,坐在家里就可以把东西送到家里来,它一定要走路(网络链路),也就是需要网络的时间开销,假如数据有1亿数据,将FetchSize设置成1000的话,会进行10万次来回通信;如果网络延迟同机房0.02ms,那么10万次通信会增加2秒的时间,不算大。那么如果跨机房2ms的延迟时间会多出来200秒(也就是3分20秒),如果国内跨城市10~40ms延迟,那么时间将会1000~4000秒,如果是跨国200~300ms呢?时间会多出十多个小时出来。
在这里的计算中,我们还没有包含系统调用次数增加了很多,线程等待和唤醒的上下文次数变多,网络包重传的情况对整体性能的影响,因此这种方案看似合理,但是性能确不怎么样。
另外,由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时表空间来存放需要拿走的数据。因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
(1)IOPS飙升,因为存在大量的IO读取,如果是普通硬盘,此时可能会引起业务写入的抖动
(2)磁盘空间飙升,这块临时空间可能比原表更大,如果这个表在整个库内部占用相当大的比重有可能会导致数据库磁盘写满,空间会在结果集读取完成后或者客户端发起Result.close()时由MySQL去回收。
(3)CPU和内存会有一定比例的上升,根据CPU的能力决定。
(4)客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数据,这个等待与原始的JDBC不设置任何参数的方式也表现出等待,在内部原理上是不一样的,前者是一直在读取网络缓冲区的数据,没有响应给业务,现在是MySQL数据库在准备临时数据空间,没有响应给JDBC。
【userCursor原理说明】:
(1)在设置JDBC参数useCursorFetch=true后,通过Driver创建Connection的时候会自动将:detectServerPreparedStmts设置为true,这个对应JDBC参数是:useServerPrepStmts=true,也就是当设置useCursorFetch=true时useServerPrepStmt会被自动设置为true,源码片段(ConnectionPropertiesImpl类的postInitialization()中,也就是连接初始化的时候会用的):

内部多提供了另一个方法名,下面会提到:

(2)当执行SQL时,会调用到使用prepareStatment方法去执行(即使你自己用Statement内部也会转换成PrepareStatemet,因为它要用服务端预编译),代码如下:

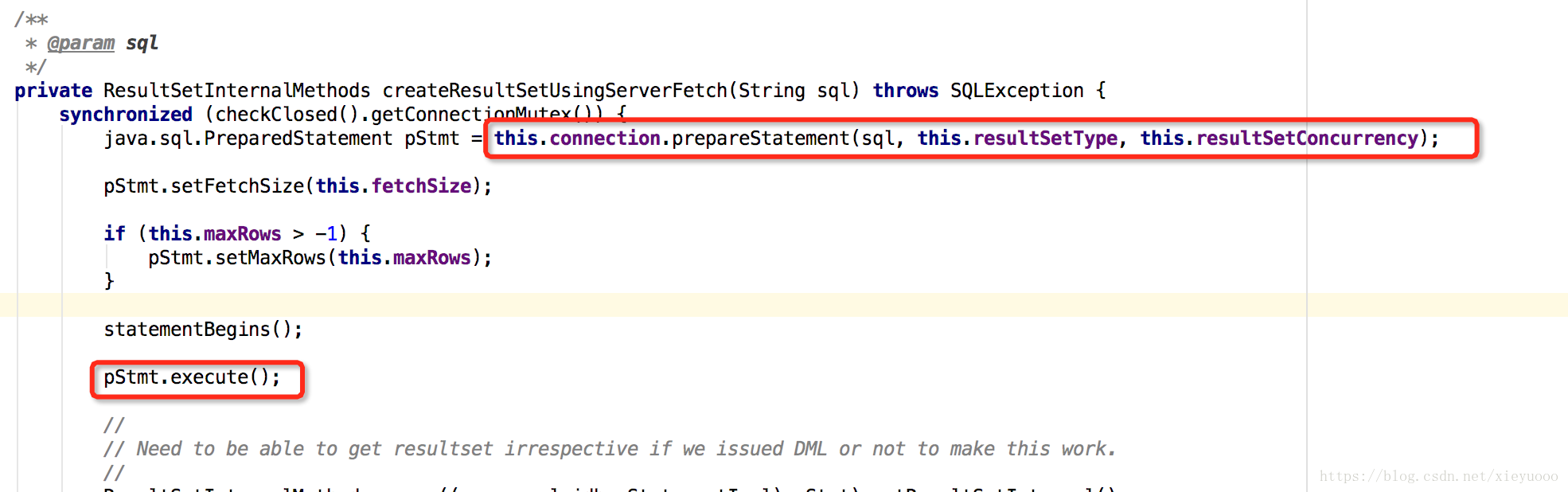
跟下代码,这里的userServerFetch()就是useCursorFetch参数的判定以及游标类型和版本的判定,而游标类型判定的就是为默认值。
(3)步骤1已提到detectServerPreparedStmts被设置为true,在prepareStatement的时候会选择其ServerPreparedStatement作为实现类:具体请参考ConnectionImpl.prepareStatement(String , int , int)的代码,代码太长也不难,就不贴了。
(4)我要说的是ServerPreparedStatement在创建的时候,会在SQL发送前加一个指令在前面,让服务器端预编译,这个指令就是1个int值:22(MysqlDefs.COM_PREPARE),如下:

(5)这里仅仅是告知服务端预编译SQL,还没有指定游标也在服务器端,在真正发生execute、executeQuery,会调用到ServerPreparedStatement的serverExecute方法中。
(6)在步骤5描述的方法ServerPreparedStatement.serverExecute()方法中,会再一次判定useCursorFetch的判定,如果useCursorFetch成立,则在发送给服务端的package中,开启游标的指令:1(MysqlDefs.OPEN_CURSOR_FLAG),如下:
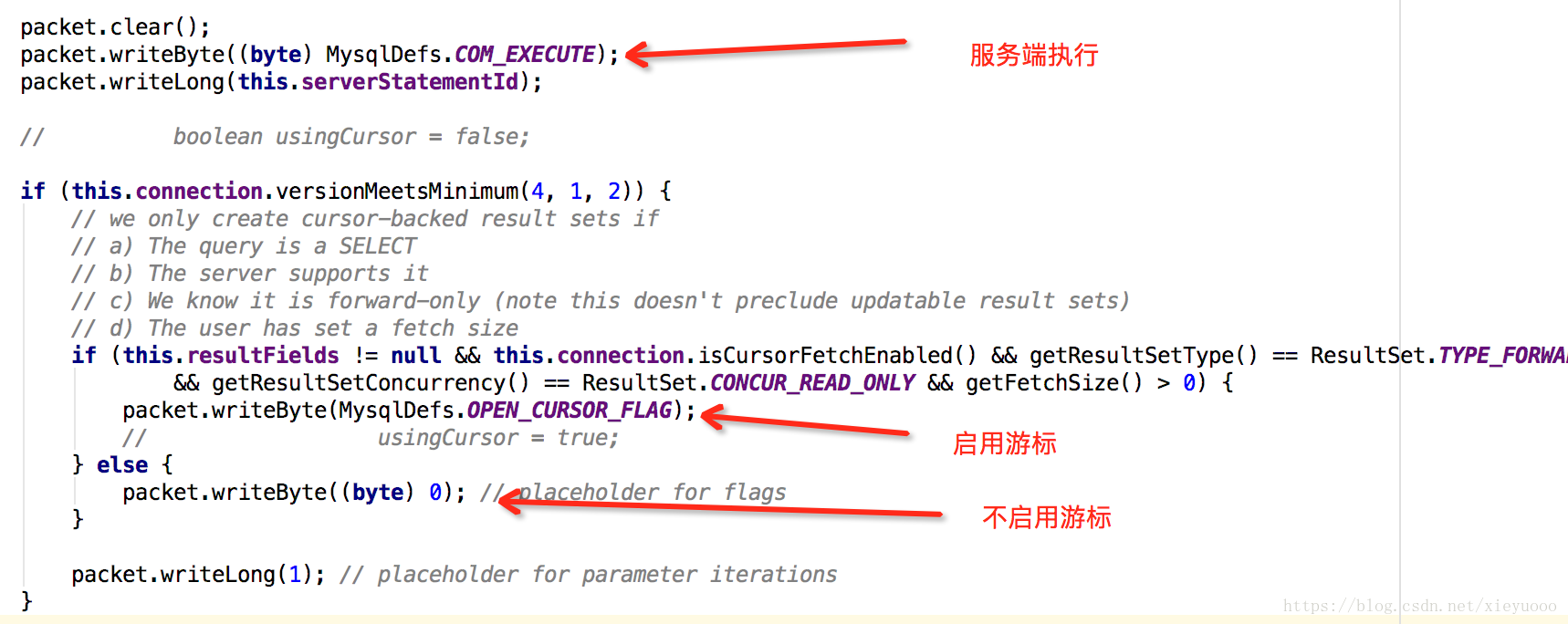
当开启游标的时候,服务端返回数据的时候,就会按照fetchSize的大小返回数据了,而客户端接收数据的时候每次都会把换缓冲区数据全部读取干净(可复用不开启游标方式的代码)。
PS:关于PreparedStatement在MySQL JDBC当中是有潜在问题的,无论是否开启服务端Prapare都有一些坑存在,这些我会在后续的一些文章当中逐步讲到。
【方式3:Stream读取数据】
我们知道第1种方式会导致Java挂掉,第2种方式效率低而且对MySQL数据库的影响较大,客户端响应也较慢,仅仅能够解决问题而已,那么现在来看下Stream读取方式。
前面提到当你使用statement.setFetchSize(Integer.MIN_VALUE)或com.mysql.jdbc.StatementImpl.enableStreamingResults()就可以开启Stream读取结果集的方式,在发起execute之前FetchSize不能再手工设置,且确保游标是FORWARD_ONLY的。
这种方式很神奇,似乎内存也不挂了,响应也变快了,对MySQL的影响也变小了,至少IOPS不会那么大了,磁盘占用也没有了。以前仅仅看到JDBC中走了单独的代码,认为这是MySQL和JDBC之间的另一种通信协议,殊不知,它竟然是“客户端行为”,没错,你没看错,它就是客户端行为。
它在发起enableStreamingResults()的时候,几乎不会做任何与服务端的交互工作,也就是服务端会按照方式1回传数据,那么服务端使劲向缓冲区怼数据,客户端是如何扛得住压力的呢?
在JDBC当中,当你开启Stream结果集处理的时候,它并不是一把将所有数据读取到Java内存中的,也就是图1中并不是一次性将数据读取到Java缓冲区的,而是每次读取一个package(这个package可以理解成Java中的一个byte[]数组),一次最多读取这么多,然后会看是否继续向下读取保证数据的完整性。业务代码是按照字节解析成行也业务方使用的。
服务端刚开始使劲向缓冲区怼数据,这些数据也会怼满客户端的内核缓冲区,当两边的缓冲区都被怼满的时候,服务端的1个Buffer尝试通过TCP传递数据给接收方时,此时由于消费方的缓冲区也是满的,因此发送方的线程会阻塞住,等待对方消费,对方消费一部分,就可以推送一部分数据过去。连起来看就是JDBC的Stream数据未来得及消费之前,缓冲区数据如果是满的,那么MySQL发送数据的线程就阻塞住了,这样确保了一个平衡(关于这一点,大家可以使用Java的Socket来尝试下是否是这样的)。
对于JDBC客户端,数据获取的时候每次都在本地的内核缓冲区当中,就在小区的快递包裹箱拿回家一个距离,那么自然比起每次去超市的RT要小得多了,而且这个过程是准备好的数据,所以没有IO阻塞的过程(除非MySQL服务端传递的数据还不如消费端处理数据来得快,那一般也只有消费端不做任何业务,拿到数据直接放弃的测试代码,才会发生这样的事情),这个时候不论:跨机房、跨地区、跨国家,只要服务端开始响应就会源源不断地传递数据过来,而这个动作即使是第1种方式也是必然需要经历的过程。
Stream读取方式是不是就没有问题了呢?肯定是有的,而且还不止一个两个坑,这篇文章我没法一一说清楚,也和每一个人所遇到的情况有所不同,也会遇到一些比较偏的问题和坑,在本文中主要针对对业务的影响程度来看:
【优缺点对比】:
| 读取方式 | 优点 | 缺点 |
| 默认参数读取 | 1、代码简单、JDBC逻辑简单 2、OLTP单行操作速度最佳 3、对MySQL的业务影响小 |
1、数据量大的时候内存会溢出 2、需要Java程序将所有的数据读取到JVM中才响应程序 3、一旦服务端开始返回数据(不是JDBC响应,是MySQL的服务端准备一条数据开始)无法cancel,且在数据准备好以前,cancel会被阻塞 |
| useCursorFetch | 1、相对方式1不会导致内存溢出 2、相对方式3对数据库影响时间更短 |
1、会占用数据库磁盘空间 2、占用更多的IOPS 3、需要MySQL Server将所有数据准备好,才会响应程序 4、网络RT会根据数据量产生数百倍乃至数千倍的放大。 5、数据准备阶段发起cancel操作会阻塞(可在MySQL服务端数据准备前cancel掉) 6、数据传输阶段发起cancel操作无效 |
| stream读取 | 1、相对方式1不会内存溢出 2、相对方式3整体速度更快 3、在几种方式中,读取大数据量,响应第一条数据的时间是最短的 4、跨地域传送大量数据,不会放大RT |
1、相对方式2,对数据库影响时间会更长一些 2、相对方式1,会多一些系统调用次数。 3、cancel无效,cancel不阻塞 |
【对业务的影响对比】:在MySQL 5.7下分别测试MyISAM、InnoDB两种存储引擎:
| MyISAM | InnoDB | |
| useCursor | 数据准备阶段:
单条操作:可读、可DDL、写操作阻塞 交叉操作:发起写操作阻塞,接着读操作会阻塞 交叉操作:DDL后,写操作阻塞,读操作不阻塞,但此时写操作阻塞阶段不同,不会阻塞读操作
PS:DDL需要等待数据准备阶段完成后才能执行下去,但在数据准备阶段DDL已在运行中。
读取数据过程中: 单条操作:可读、可做DDL、可写操作 交叉操作:写入后,可读、可DDL 交叉操作:DDL后,写操作阻塞,读操作不阻塞 |
数据准备阶段: 单条操作:可读、可写、可DDL 交叉操作:写操作,再读取和DDL不会阻塞 交叉操作:先DDL,读、写均会被阻塞
PS:DDL需要等待数据准备阶段完成后才能执行下去,但在数据准备阶段DDL已在运行中。
读取数据过程中: 单条操作:可读、可写、可DDL 交叉操作:写操作,再读取和DDL不会阻塞 交叉操作:先DDL,读、写均不会被阻塞 |
| stream读取 | 整个Stream读取过程:
1、单条操作:可读、可做DDL、写操作阻塞 2、交叉操作:发起写操作阻塞,接着读操作会阻塞 3、交叉操作:先做DDL,读操作不阻塞,写操作阻塞,但此时写操作阻塞阶段不同,不会阻塞读操作 4、交叉操作:步骤3阻塞了写操作,此时将DDL Kill掉,写操作会进入步骤2的阻塞状态,阻塞掉所有的读取操作。 |
整个Stream读取过程:
单条操作:可读、可写、可DDL 交叉操作:写操作后,不阻塞读取和DDL 交叉操作:DDL后,读操作阻塞、写操作阻塞
PS:DDL本身可以在这个过程中运行但在Stream读取完成前它无法结束,要等待数据读取完成才结束(如果DDL本身比Stream要快),但DDL已到最后阶段,也就是说Stream读取的时候,DDL是在运行的,只是在最后阶段需获取meta锁时阻塞住了。 |
【理论上可以更进一步,只要你愿意】
理论上这种方式是比较好的了,但是就完美主义来讲,我们可以继续探讨一下,对于懒人来讲,我们连到小区楼下快递包裹箱去拿一下的动力也是没有的,我们心里想的就是要是谁给我拿到家里来送到我嘴巴里,连嘴巴都给我掰开多好。
在技术上理论上确实可以做到这样,因为JDBC从内核拷贝内存到Java当中是需要花时间的,要是有另一个人把这个事情做了,我在家里干别的事情的时候它就给我送到家里来了,我要用的时候就直接从家里来,这个时间岂不是省掉了。每错,对于你来讲确实省掉了,不过问题就是谁来送?
在程序中一定需要加一个线程来干这个事情,把内核的数据拷贝到应用内存,甚至于解析成行数据,应用程序直接使用,但这一定完美吗?其实这个中间就有个协调问题了,例如家里要炒菜,缺一包调料,原本可以自己到楼下买,但是非要让别人送家里,这个时候其它的菜都下锅了,就剩一包调料,那么你没别的办法,只能等这包调料送到家里来以后才能进行炒菜的下一道工序。所以,在理想情况下,它可以节约很多次内存拷贝时间,会增加一些协调锁的开销。
那么可以不可以直接从内核缓冲区读取数据呢?
理论上也是可以的,在解释这个问题之前,我们先了解下除了这一次内存拷贝还有那些:
JDBC按照二进制将内核缓冲区的数据读取后,也会进一步解析成具体的结构化数据,由于此时要给业务方返回ResultSet的具体行的结构化数据,也就是生成RowData的数据一定会有一次拷贝,而且JDBC返回某些对象类型数据的时候(例如byte []数组),在某些场景的实现,它不希望你通过结果集修改返回结果中的byte []的内容(byte[1] = 0xFF)去修改ResultSet本身内容,可能还会再做1次内存拷贝,业务代码使用过程中还会存在拼字符串,网络输出等,又是一堆的内存拷贝,这些在业务层面是无法避免的,相对这点点拷贝来讲,简直微不足道,所以我们也没去干这事情,以为从整体上看几乎微不足道,除非你的程序瓶颈在这里。
因此从整体上看内存拷贝是无法避免的,多的这一次无非是系统级的调用,开销会更大一点,从技术上来讲,我们是可以做到直接从内核态直接读取数据的;但这个时候就需要按照字节将Buffer从的数据拿走才能让远程更多的数据传递过来,没有第三个位置存放Buffer了,否则又回到了内核到应用的内存拷贝上来了。
相对来讲,服务端倒是可以优化直接将数据通过直接IO的方式传递(不过这种方式数据的协议就和数据的存储格式一致了,显然只是理论上的), 要真正做到自定义的协议,又要通过内核态数据直接发送,需要通过修改OS级别的文件系统协议,来达到转换的目的。
