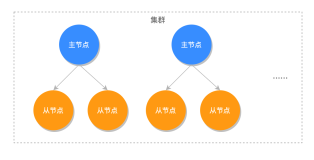
由于Scrapy本身是不支持分布式的,故引入Scrapy-redis组件,Scrapy-redis替换掉Scrapy的调度器,从而把rquests放入redis队列,将Scrapy从单台机器扩展到多台机器,实现较大规模的爬虫集群。
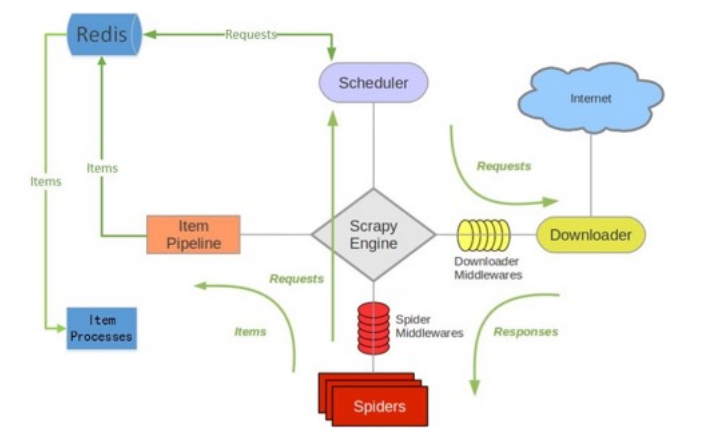
Scrapy-redis.png
Scrapy-Redis
Scrapy的Redis组件.
文档: https://scrapy-redis.readthedocs.org.
特点
- 分布式抓取
你可以启动多个蜘蛛实例共享一个单一的redis队列。最适合广泛的多域抓取。 - 分布式处理
把项目被推到一个redis排队意味着你可以开始需要处理多进程共享的项目队列。 - Scrapy即插即用的组件
调度程序+复制过滤器,项目管道,基蜘蛛。
要求
- Python2.7,3.4 or 3.5
- Redis >= 2.8
- Scrapy >=1.1
- redis-py >= 2.10
用法
在你的项目使用以下设置
# 允许在redis中存储请求队列.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 确保所有的蜘蛛通过redis共享相同的重复过滤器.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#警告:在Python 3 x中,序列化程序必须返回字符串键和支持。
#字节作为值。因为这个原因,JSON或msgpack模块不拖欠工作。
#在Python 2中,没有这样的问题,您可以使用“json”或“msgpack的序列化程序。
#SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 不要清理Redis队列,允许暂停/恢复爬行.
#SCHEDULER_PERSIST = True
# 使用优先队列调度请求。(默认)
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 选择队列
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
#马克斯空闲时间防止蜘蛛在分布式爬行时被关闭。
#这仅在队列类是spiderqueue或spiderstack,
#也可能在第一次启动蜘蛛时(因为队列是空的)阻塞相同的时间。
#SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 在redis中存储被刮过的项目,用于后期处理
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# 项目管道序列化并将项目存储在这个红色的关键字中.
#REDIS_ITEMS_KEY = '%(spider)s:items'
#该项目是默认的序列化程序ScrapyJSONEncoder 你可以用任何一个可调用对象的重要路径
#REDIS_ITEMS_SERIALIZER = 'json.dumps'
# 在连接到Redis时指定要使用的主机和端口(可选
#REDIS_HOST = 'localhost'
#REDIS_PORT = 6379
# 为连接指定完整的Redis URL(可选).
#如果设置,这将优先于REDIS主机和REDIS端口设置。
#REDIS_URL = 'redis://user:pass@hostname:9001'
# 定制的redis客户端参数(例如:套接字超时等。)
#REDIS_PARAMS = {}
# 使用定制的redis客户端类.
#REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
#如果是真的,它使用redis的` ` SPOP ` `操作。你必须使用` ` Sadd ` `
#命令添加URL到redis队列。如果你有这个可能有用
#要避免重复在您的起始URL列表和顺序处理无所谓。
#REDIS_START_URLS_AS_SET = False
# 用于redis蛛和re椎间盘爬行器的默认启动url键
#REDIS_START_URLS_KEY = '%(name)s:start_urls'
#为redis使用其他编码,而不是使用utf-8
#REDIS_ENCODING = 'latin1'
注意:
3.0版本修改了从编组到cPickle的请求序列化,因此,使用版本2.0的请求无法使用3.0
运行示例项目
这个例子说明了如何在多个爬虫实例之间共享一个爬虫请求队列,这非常适合广泛的爬虫。
类RedisSpider。redis爬虫能够从redis读取url。redis队列中的url将依次处理,如果第一个请求产生更多请求,那么爬虫处理这些请求,然后从redis获取另一个url。
例如,创建一个文件myspider。下面的代码
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
name = 'myspider'
def parse(self, response):
# do stuff
pass
然后,
1.运行爬虫:
scrapy runspider myspider.py
2.把url放进redis
redis-cli lpush myspider:start_urls http://google.com
注意:
这些爬虫依赖于爬虫的空闲信号来获取开始的url,因此在您推送一个新的url且爬虫开始爬行时,它可能会有几秒钟的延迟