
从本章开始,逐步引入数据库相关知识点。
关于数据库的工具以及一些入门的知识请自行查找资料学习(例如:创建数据表,数据库可视化工具)。
数据表创建方式

对于我们开发人员来说,一般推荐使用Code First ,因为可以专注业务模型的设计 而不是数据库设计 , 数据库只是用来存数据的 ,它的表关系应该由我们业务来决定。
那么其他两种数据表创建方式可以自己上网查询相关资料,这里不再赘述。
定义一个模型类
之前提过一个叫做验证层,现在引入模型层(MVC中的M:模型层)
设计模型的思维,应该考虑业务模型,而不要去过多注意数据库的设计,数据库只是存数据的。
app文件夹下新建models文件夹并新建一个名为book.py的模型:
这里使用sqlalchemy这个包来做模型映射,还有一个包叫做flask_sqlalchemy,是flask在sqlalchemy的基础上做了一些自己的封装,待会我们也要用到。
再介绍一个第三方的独立的包:WTFORMS,Flask也针对这个包做了封装并有一个新的包叫做Flask_WTFORMS,以上两个(sqlalchemy、WTFORMS)是独立的两个包,可以用在任何时候而不仅仅在Flask中。
Flask的路由是在werkzeug基础上封装的
Flask是微框架,只提供最核心的功能其他部分可以自由组装
所有flask插件都必须和flask核心对象app绑定在一起
安装两个包:pip install sqlalchemypip install flask-sqlalchemy
编辑book.py:
from sqlalchemy import Column, Integer, String
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Book(db.Model):
# 主键 自增
id = Column(Integer, primary_key=True, autoincrement=True)
# 长度50 不为空
title = Column(String(50), nullable=False)
author = Column(String(30), default="未知")
# unique : 不重复, 会加一个索引, 不重复
uid= Column(String(15), nullable=False, unique=True)
以上代码就是一个简单的创建数据表的模型,包含四个字段,
之前提到过,所有的Flask的插件都需要和Flask的核心对象app来关联起来,那么怎么做关联呢?
在app文件夹下的__init__.py中:
from flask import Flask
from app.models.book import db
def create_app():
app = Flask(__name__)
app.config.from_object("app.setting")
app.config.from_object("app.secure")
register_blueprint(app)
db.init_app(app)
db.create_all(app=app)
return app
def register_blueprint(app):
from app.web import web
app.register_blueprint(web)
首先把db对象导入,
再使用db.init_app(app)做关联,init_app这个方法很重要,后边所有的Flask插件都使用这个方法做关联。
接着,
需要把数据库的配置信息放到配置文件中,因为数据库配置信息是属于比较机密的,所以我们放在secure.py中。
SQLALCHEMY_DATABASE_URI = 'mysql+cymysql://root:123456@127.0.0.1:3306/demo'
上边配置信息的变量名SQLALCHEMY_DATABASE_URI这个是不可以更改的,必须使用这个,
后边参数的意思是使用cymysql这个驱动来做数据库操作,用户名root 密码 123456,ip 端口是127.0.0.1 3306,数据库名为demo。
cymysql需要安装:pip install cymysql
运行代码查看结果,数据库确实多了一张名为book的表。
ORM与Code First
ORM 对象关系映射 : 包含的层面更广阔 不仅仅是创建 还包含查询 更新 删除
与
Code First : 解决的是数据表创建的问题,专注业务模型设计而不是数据库设计,数据库只是存数据的,表关系应该有业务来决定
业务逻辑最好写在MVC中M中
Flask中上下文管理
- 应用上下文(AppContext)
- 请求上下文(RequestContext)
上下文本质来说其实就是对象
应用上下文:对核心对象Flask的封装
请求上下文:对请求对象Request的封装
为什么会需要上下文?直接操作Flask核心对象不行吗?
其实这个就是一个设计思想的问题,有时候对于一个对象来说,有一些信息是属于这个对象外部的,并不是属于对象本身,那么此时我们可以设计一个所谓的上下文(上下文就是一个对象),把Flask核心对象和外部的这些数据一起组成一个整体,这个整体就是我们说的上下文对象。
Flask核心对象:承载着各种各样的功能,例如:保存配置文件信息、提供注册路由\视图函数等这样的功能。
AppContext :把Flask核心对象做了一系列封装,并且附加了一些额外的参数
Request :保存了一些请求信息,例如: URL参数,完整的URL等等一切的请求信息都在这个对象中。
RequestContext : 对Request对象的封装。
在我们编码过程中,真正想去使用的是Flask核心对象或者是Request这个对象,但是我们要使用它并不一定要直接直接导入这俩核心对象,正确的做法是:
从AppContext或RequestContext间接的去拿Flask核心对象或者是Request。
Flask中,采用了LocalProxy模式(本地代理)的模式提供了间接去操作上下文的能力,也就是current_app和request这两个对象。
这里Flask使用了设计模式里边的代理模式。
Flask上下文与出入栈
Flask如何操作上下文?看下图:
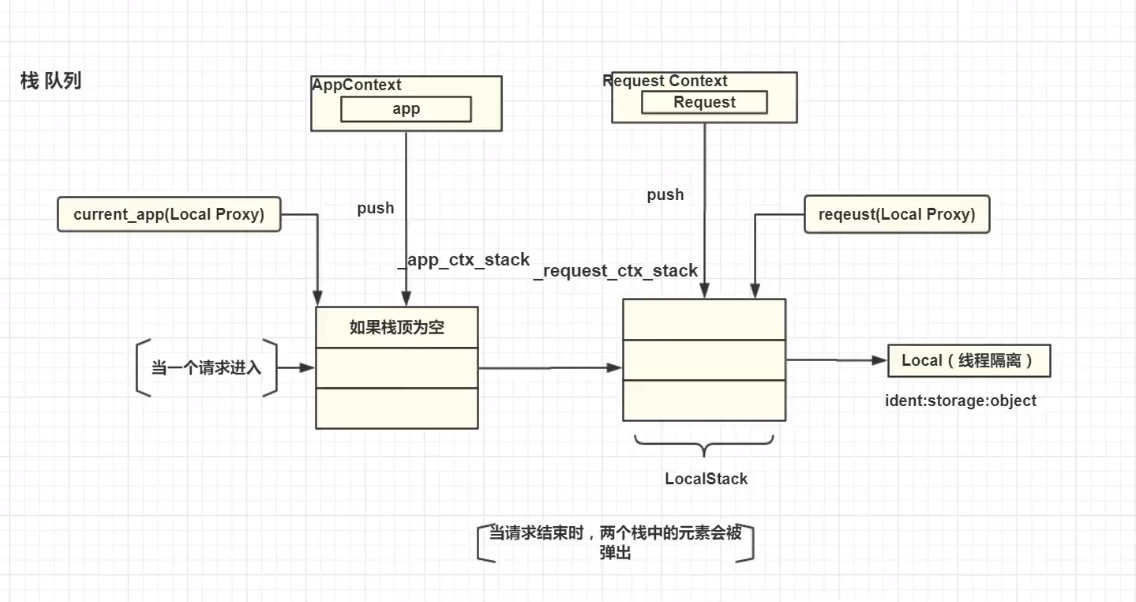
当一个请求进入Flask框架中时,首先会实例化一个RequestContext(请求上下文),这个请求上下文封装了这次请求的相关信息,请求的相关信息在Request中,然后会把请求上下文使用push方法推入到栈中(栈:先入后出),Flask中使用 LocalStack 来表示一个栈,LocalStack 是一个对象,实例化之后,用 _request_ctx_stack 来表示RequestContext推入的栈,同样的,还有一个 _app_ctx_stack 也是一个栈,
RequestContext在入栈之前,Flask会去检查一下 _app_ctx_stack 这个栈的栈顶的元素,如果是空或者不是当前对象,那么Flask会把AppContext推入_app_ctx_stack这个栈中
然后才会把RequestContext推入_request_ctx_stack栈中。
current_app(Local Proxy) 和 request(Local Proxy) 永远都是指向栈顶的,所以当你去使用current_app或request,其实就是在操作这两个栈的栈顶元素。
欲知后事如何,请看下回分解,记得点个赞~感谢

