还有什么能比国际顶会更能反映图像技术的最前沿进展?
在这篇文章中,亲历了ECCV 2018的机器学习研究员Tetianka Martyniuk挑选了6篇ECCV 2018接收论文,概述了超分辨率(Super-Resolution, SR)技术的未来发展趋势。
量子位将文章要点翻译整理如下与大家分享。

论文:
To learn image super-resolution, use a GAN to learn how to do image degradation first
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Adrian_Bulat_To_learn_image_ECCV_2018_paper.html
为什么超分辨率经常被认为是个相当简单的问题?我曾经说过,因为它能够轻松得到训练数据(只需要降低获取图像的清晰度即可),所以和图像修复任务相比,超分辨率可能显得有些无聊。
但人工生成的低分辨率图像,和真实自然存在的图像一样吗?答案是否定的。和通过双三次插值生成的图像不同,真实世界的低分辨率图像明显属于不同类别。
因此,有人认为用这些人工生成的图像训练GAN并不能生成真实的图像。
为了处理这个问题,这篇论文的作者建议了两步走的方法:首先,用未配对的图像训练一个降低分辨率的GAN,所以它学习了如何减小高分辨率图像的规模。
当图片有多级退化或未知退化(比如运动模糊)时,能够帮我们获取真实结果的并不是建模过程,而是图像退化的学习过程。此外,它还解决的重建图像时的“老大难”问题:难以获取配对图像。
所以,在第一阶段,我们可以使用不同的未配对数据集,比如由Celeb-A、AFLW、LS3D-W和VGGFace2组成的高分辨率图像数据集,或者低分辨率图像数据集Widerface。第二阶段,用上一步的输出结果,用成对训练数据从低分辨率到高分辨率地训练GAN。
论文作者还提到,作者表示,唯一的另外一种写到了真实低分辨率面部图像超分辨率结果的方法,也出自自己实验室,而且中了CVPR 18。这些结果只包含面部图像,因为它用到了面部标记,因此不能被应用到其他物体分类中。
这是一些让人印象深刻的结果:

论文:
Face Super-resolution Guided by Facial Component Heatmaps
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Xin_Yu_Face_Super-resolution_Guided_ECCV_2018_paper.html
在这篇论文中,作者认为自己的Face SR方法的结果优于SOTA,是因为它考虑到了人脸的面部特征,因此可以捕捉到动作的变化。此外,这大大降低了训练样例的数量。
他们主要的方法是借助提升采样的多任务CNN和辨别网络。这个提升采样的网络包含两个分支:一个提升采样的分支和一个相互协作的面部五官热力图分支。
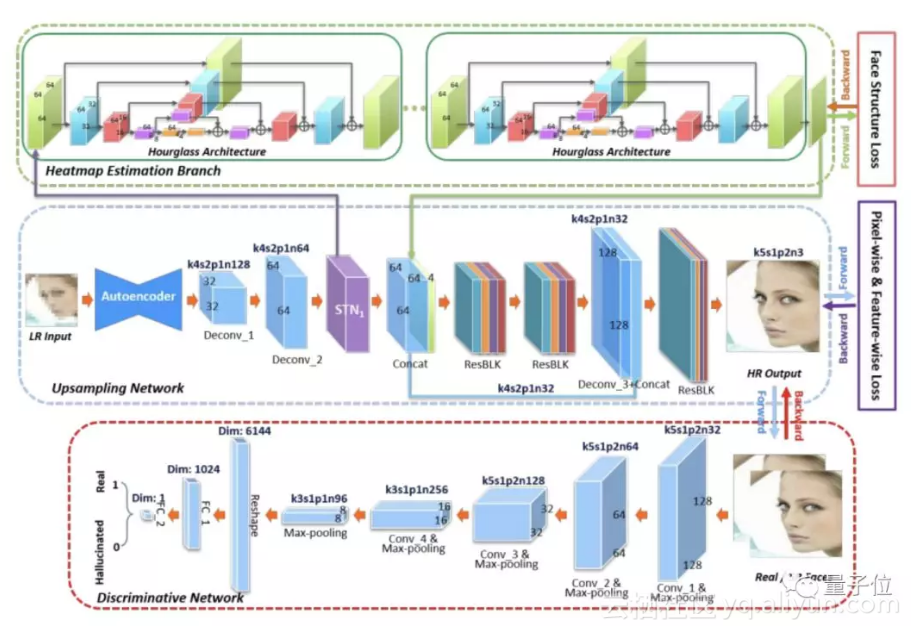
在16*16的图像中检测面部五官是一个颇具挑战性的任务,所以作者首先拿到了低分辨率图像的超分辨率版本,然后部署空间变换网络配准特征图,随后,用经过上采样的特征图来预估面部五官的热力图。
配准特征图是可以减少训练数据规模的重要原因之一,预计的面部热力图也提供了可视化信息,这些是无法从像素级信息推断出来的。
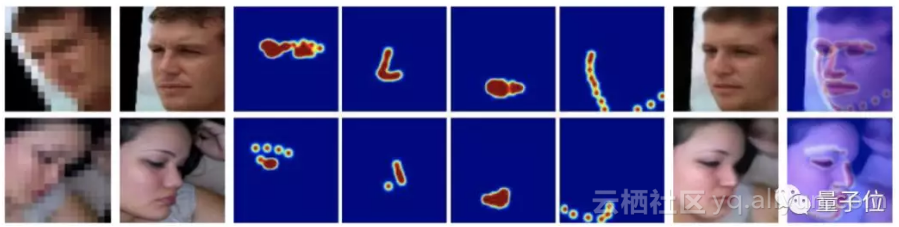
这里还有一些结果:

△ a:未配准的低像素的输入,b:原始高清图像,c:配准低分辨率人脸的最近邻,d:级联Bi-Network结果,e:TDAE(Transformative Discriminative Autoencoders)结果,f:用作者的训练数据训练过的TDAE结果,g:作者的结果
总的来说,与其他满量程(Full scale range,FSR)方法主要的不同点是,作者不仅应用到了相似强度映射,并且将收集的结构信息当作额外的先验。
三:用深度残差通道的注意网络的图像超分辨率
论文:
Image Super-Resolution Using Very Deep Residual Channel Attention Networks
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Yulun_Zhang_Image_Super-Resolution_Using_ECCV_2018_paper.html
在这篇文章中,作者提出了一种让CNN更深的方法:首先要做的就是,准备10个残差组,其中每组包含20个残差通道注意模块。
研究人员表示网络的深度很重要,我们也认为如此,也见证过EDSR和MDSR带来的一波浪潮。然而,通过简单堆叠残差块来构建更深的网络可能很难得到更大的提升,需要在架构方面有更多进展。
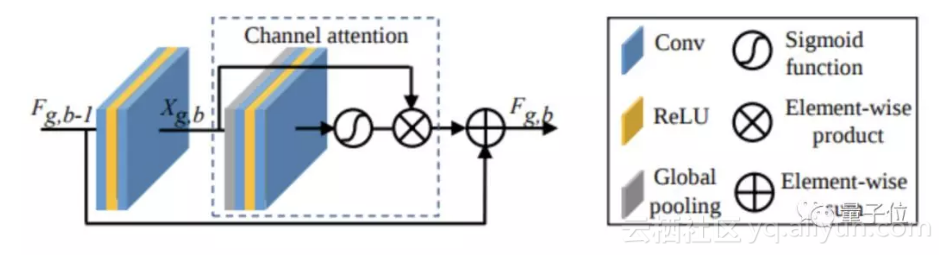
所以,他们提出了RIR(residual in residual)架构,堆叠的每个残差组里包含很多残差块,因此我们也可以获得长跳过连接和短跳过连接。
上述提到的映射和残差块中的快捷键可以绕开低频信息。
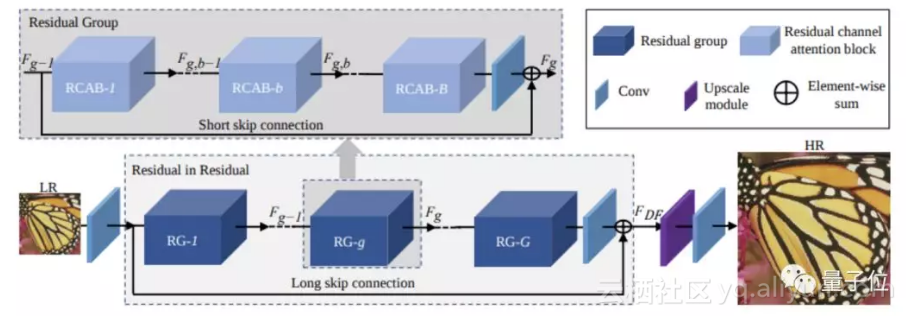
△ 网络架构
这篇论文中第二个亮点是通道注意机制,基于CNN的方法主要的问题是,他们会平均对待每个通道特征,缺少分辨跨特征通道的学习能力。所以,引入的通道注意自适应性重新调整每个通道的特征,可以将注意力集中到更有用的通道中。
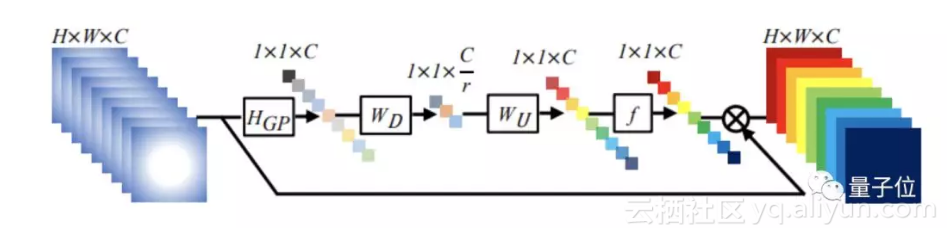
基本模组如下:
结果如下:

四:用于图像超分辨率的多尺度残差网络
论文:
Multi-scale Residual Network for Image Super-Resolution
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Juncheng_Li_Multi-scale_Residual_Network_ECCV_2018_paper.html
在这篇论文中,作者从重建经典的超分辨率模型开始讲起,包括SRCNN、EDSR和SRResNet这些已知的经典模型。基于这些重建实验,研究人员认为这些模型具有一些共同点:
● 难以重现● 特征利用率不足
● 可扩展性差
所以,研究人员提出了一种新型的网络架构,并称之为多尺度残差网络(Multi-scale residual network,MSRN)。
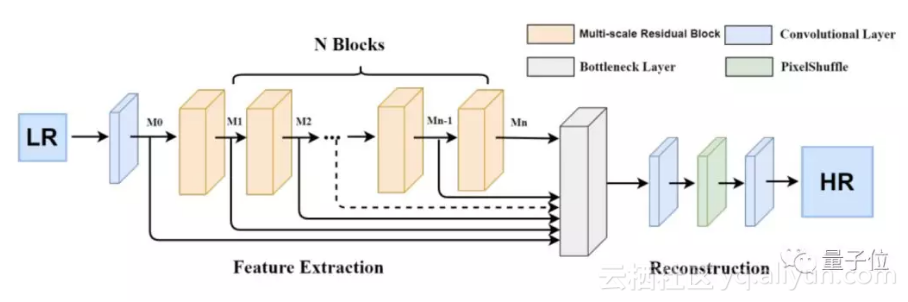
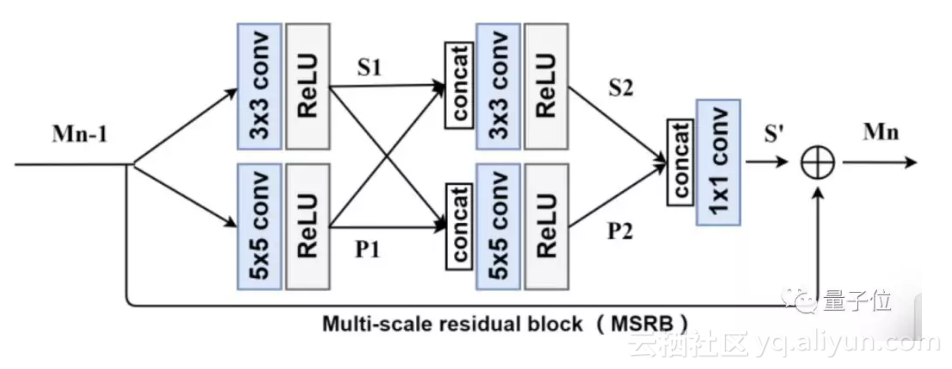
它由两部分构成:多尺度特征融合和局部残差学习,可以用不同大小的卷积核来适应性检测不同规模的图像特征。采用残差学习法可以让神经网络更高效。
每个多尺度残差网络的输出都被用作全局特征融合的分层特征,最终,所有这些特征都在重建模型中用于修复高分辨率图像。
作者在没有任何初始化或技巧的情况下,用DIV2K数据集训练网络,证明了这可以解决我们上述提到的第一问题:复现性差。
可以看看论文中给出的结果:

在其他低级计算机视觉的任务中的结果也可以拿来对比,这个方法对作者来说最大的意义就是开创了一个用于图像修复的单个多任务模型。

论文:
Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Namhyuk_Ahn_Fast_Accurate_and_ECCV_2018_paper.html
首先向大家展示不同基准算法在Mult-Adds和参数数量方面的对比:
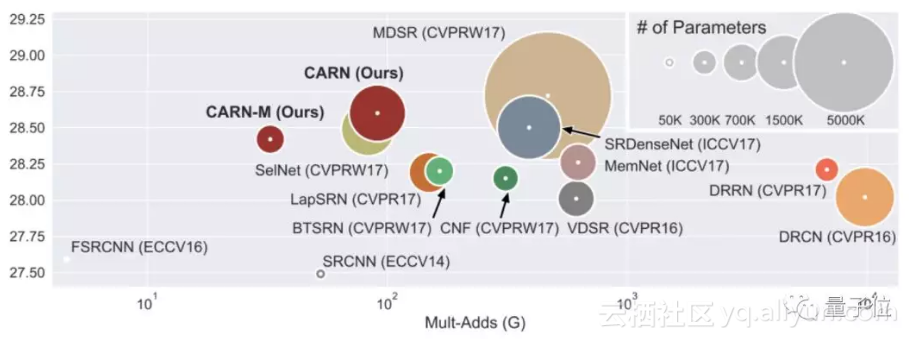
这篇文章的主要贡献也显而易见,就是提供了一个轻量级的网络,作者称之为CARN(Cascading Residual Network,级联残差网络)。
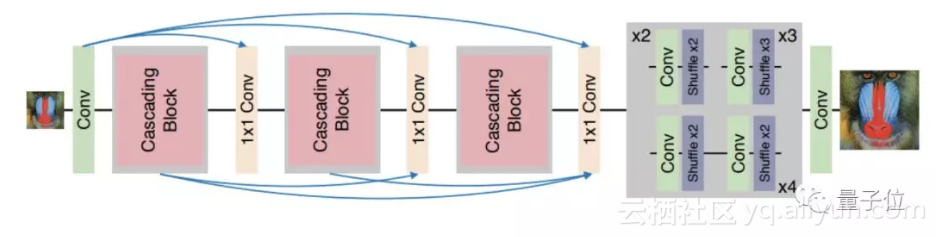
它具有以下三个特征:
● 全局和局部级联连接● 中间特征是级联的,且被组合在1×1大小的卷积块中
● 使多级表示和快捷连接,让信息传递更高效
然而,多级表示的优势被限制在了每个本地级联模块内部,比如在快捷连接上的1×1卷积这样的乘法操作可能会阻碍信息的传递,所以认为性能会下降也在情理之中。
高效的CARN
为了提升CARN的效率,作者提出了一种残差-E模块。
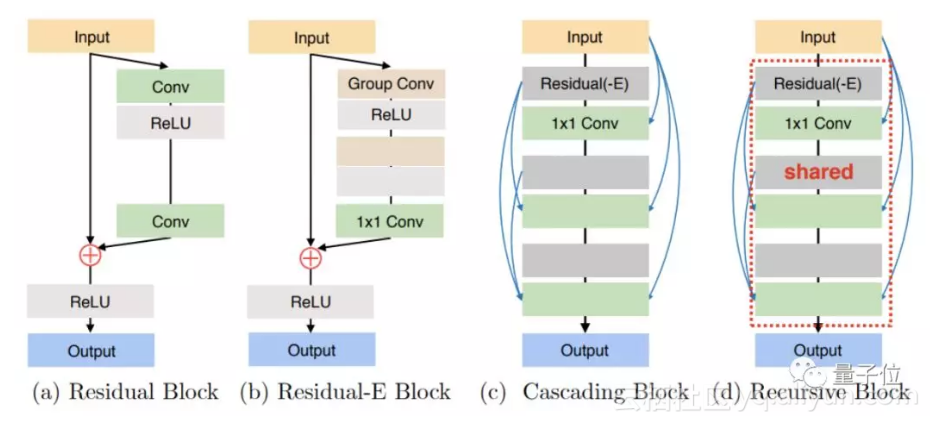
这种方法和MobileNet类似,但是深度卷积被替换为了分组卷积。因为分组卷积中间必然有trade-off,因此在用户可以选择合适的分组大小。
为了进一步降低参数,论文中用到了一种与递归神经网络相似的技巧,就是将级联模块的参数共享,让模块高效递归。
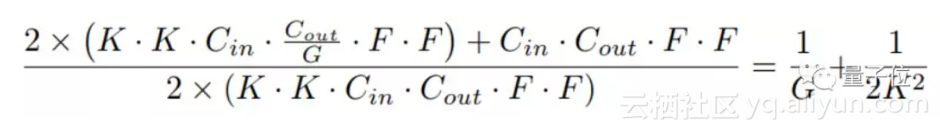
△ 通过将普通残差块更改为高效残差块,可以精简操作数量
CARN的处理结果如下:

论文:
SRFeat: Single Image Super-Resolution with Feature Discrimination
地址:
http://openaccess.thecvf.com/content_ECCV_2018/html/Seong-Jin_Park_SRFeat_Single_Image_ECCV_2018_paper.html
在这篇论文中,作者主要提出了一种方法,部署一个可以在特征域中起作用的额外的辨别器。
作者表示,与像素上的均方误差相似,VGG特征中的均方误差不足以用来完全表示特征图的真实特点。所以,他们在特征图中加入了对抗性损失,并将其命名为“SRFeat”。
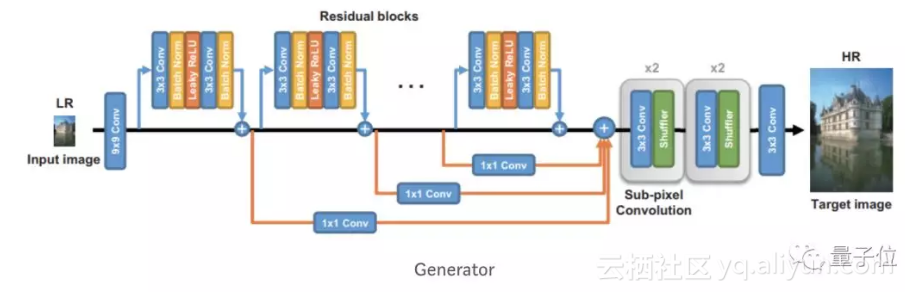
作者通过两个步骤训练了生成器:即预训练和对抗训练。
在预训练阶段,作者通过最小化均方误差损失来训练网络,通过预训练步骤得到的网络已经能够实现高PSNR,然而,它不能产生看起来令人满意的带理想高频信息的结果。
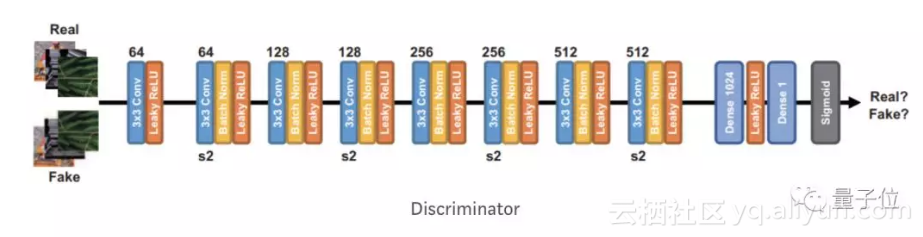
在随后的对抗训练阶段,需要最小化这样一个损失函数:它包含了视觉上看起来相似的损失、图像图像GAN损失和特征GAN损失。
使用ImageNet预训练生成器,再用DIV2K进行进一步训练后,结果如下:

SRFeat的结果看起来更优秀一些。
原文发布时间为:2018-10-13
本文作者:关注前沿科技