5 综合案例
实际业务中,多表关联运算十分常见,外键表、同维表、主子表这几种关联类型可能会混合出现。下面我们来看一个综合案例。
5.1 表结构和查询目标
某电商平台中和订单编号这个字段相关的有6个表,主要表结构如下:
他们都靠订单编号字段进行关联,下面是订单表和另外5个表的对应关系
用户表和用户地址表,这两个表是按照用户编号字段1对1的关系,这是同维表情况。
商品信息表和类别信息表是通过类别编码进行关联,这是外键表的情况。
最后还有一个卖家信息表。这里一共有11个表,假设要做这样一个查询:现在想知道江浙沪三省的VIP用户在6月份内从5星级卖家那里购买的所有电脑类商品的详情,并且要求只统计那些优惠总金额大于100元、用户评分4分以上的使用邮政配送的订单,而且这些订单不能是分期付款的。
使用SQL实现:
SELECT * FROM
订单表,
(SELECT用户编号 FROM 用户信息表 用户,用户地址信息表 地址 WHERE 用户.用户编号=地址.用户编号 AND 用户.VIP级别>0 AND (地址.省=江苏 OR 地址.省=浙江 OR 地址.省=上海) ) 用户,
(SELECT卖家编号 FROM 卖家信息表 WHERE 卖家信息表.等级=5) 卖家,
(SELECT订单编号 FROM 订单优惠表 GROUP BY 订单编号 HAVING SUM(优惠金额)>100) 优惠,
(SELECT订单编号 FROM 订单发货表 WHERE 快递编码=1) 快递,
(SELECT订单编号 FROM 订单支付表 WHERE 是否分期=false) 支付,
(SELECT订单编号 FROM 订单评价表 WHERE 评分>=4) 评价,
(SELECT订单编号 FROM 订单明细表,(SELECT * FROM 商品信息表 JOIN 类别信息表 ON 商品信息表.类别编号=类别信息表.类别编号 WHERE 大类名称='电脑') WHERE 订单明细表.商品编号=商品信息表.商品编号) 明细
WHERE
订单表.用户编号=用户.用户编号
AND 订单表.卖家编号=卖家.卖家编号
AND 订单表.订单编号=优惠.订单编号
AND 订单表.订单编号=快递.订单编号
AND 订单表.订单编号=支付.订单编号
AND 订单表.订单编号=评价.订单编号
AND 订单表.订单编号=明细.订单编号
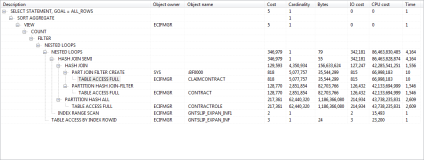
这个SQL看上去似乎很清楚,理解起来也不难,但是性能却可能惨不忍睹。为了优化查询的性能,我们需要先对这个查询进行拆分,得到以下几个子步骤:
P1=对用户表、用户地址表关联,得到江浙沪三省VIP用户的用户编号,这是同维表情况;
P2=卖家信息表取游标,条件是信用级别=5,得到卖家编码;
P3=对订单优惠表按照订单编号分组,按条件(优惠总金额>=100元)过滤;
P4=订单发货表取游标,条件是快递编码=1(邮政快递编码);
P5=订单支付表取游标,条件是是否分期=false;
P6=订单评价表取游标,条件是评分>=4;
P7=商品信息表和类别信息表用类别编码做外键关联,用条件(大类=电脑)过滤;
P8=订单明细表通过商品编号字段对P7做外键关联;
P9=订单表依次对P1、P2做外键关联;
这时P3、P4、P5、P6、P8、P9这几个子查询都是同维或者主子表的关系,对它们通过订单编码字段做有序归并,就得到了需要查询的结果。
5.3 数据预处理
得到关联类型后就可以有针对性地进行预处理。
首先,对无序的同维表、主子表进行排序处理,比如订单发货表、订单支付表、订单评价表通常是无序的,就要先对这些表进行排序;
第二步,还可以对外键表进行外键序号化,比如卖家信息表是订单表的外键表,就可以外键序号化。
5.4 查询实现
用户信息表很大,但查询目标是VIP级别的用户,符合VIP这个条件的用户并不多,进行过滤后就可以装入内存,所以P1子查询可以全部装入内存;同样,用户地址信息表作为用户信息表的同维表也很大,但属于江浙沪三省的用户并不多,经过过滤后可以全部导入内存。把这两个同维表关联后,然后再完成订单表的关联计算,来看看这个子查询的写法:
A1,得到用户信息表的游标,并按条件过滤;
A2,得到用户地址信息表的游标,并按条件过滤;
A3,对A1、A2按照用户编号字段进行有序归并,返回的结果只取用户编号;
A4,得到订单表的游标,并按条件过滤;
A5,把A4和A3做外键关联;
A6,返回结果只取订单编号、卖家编号和用户编号字段;
A7,返回执行结果;
把这个脚本保存为P9.dfx。
接下来实现商品信息表和类别信息表的关联。类别信息表是商品信息表的外键,这个表很大无法装入内存。但是大类是电脑的类别信息就不多了,所以用大类等于电脑这个条件先过滤一下后就可以装入内存。下面是个子查询,把大类是电脑的所有商品的编码全部导入内存:
A1,得到类别信息表的数据,并按条件过滤后取出;
A2,得到商品信息表游标,并按条件过滤;
A3,把A2的商品编号字段替换为A1的对应记录;
A4,结果只取商品编号字段;
A5,返回执行结果;
这个脚本保存为P7.dfx。
上面是两个子查询的处理,整个查询的实现是这样:
A1,得到订单优惠表游标;
A2,得到订单发货表游标;
A3,得到订单支付表游标;
A4,得到订单评价表游标;
A5,得到卖家信息表数据(这里认为卖家信息表的数据可以导入内存);
A6,调用P9.dfx;
A7,把A6的结果的卖家编号替换成卖家信息表里的对应记录,按条件(信用级=5)进行过滤,并排序;
A8,调用P7.dfx,得到大类是电脑的所有商品的编码;
A9,得到订单明细表游标;
A10,把订单明细表的商品编号替换成A8结果里的对应记录;
A11,对A7、A10、A1、A2、A3、A4进行有序归并;
5.5 查询技巧
技巧一:如果维表在内存中放不下,先别着急,可以看看总的查询条件里是否对这个维表进行了过滤。如果有,那么就可以把条件提取出来对维表进行过滤,很多时候过滤之后的结果就可以装入内存了。
技巧二:如果维表可以装入内存,并且已经外键序号化,那么就不要先过滤维表。因为能装入内存时用序号化做外键关联是最快的。例子中就是对卖家信息表先做关联,然后再进行条件过滤。
总结
使用集算器解决 JOIN 运算性能问题时,可以按照这个流程来处理:首先判断 JOIN 运算类型;如果是外键表,就装入内存并做外键序号化,如果无法装入内存也要尽量先用条件过滤,有条件的尽量做外键序号化;如果是同维表或主子表,要判断是否有序,有序则可以直接做有序归并,如果无序的则要先进行排序。同时,如果几个表是同步分段的还可以通过并行来提高性能。
作者:liwei
链接:http://c.raqsoft.com.cn/article/1535869053716
来源:乾学院
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。