运行平台: Windows
Python版本: Python3.x
IDE: Sublime text3
1 前言
暑假回家,”小皇帝”般的生活持续了几天,头几天还挺舒服,闲久了顿时觉得好没意思。眼看着10天的假期就要结束,曾信誓旦旦地说要回家学习,可拿回家的两本书至今一页未翻,强烈的负罪感一直催促着:”你该学习了,你该学习了…”
我之前的爬虫博客,爬的都是网页的信息,什么下载小说啊,下载动漫啊,下载帅哥图、妹子图啊。玩这些东西的时候,你想过爬取手机APP里面的东西吗?
2 实战背景
程序员的鄙视链,您听说过吗?话说:老婆漂亮的程序员,鄙视老婆不漂亮的程序员;有老婆的程序员,鄙视没有老婆的程序员;没有老婆有女朋友的程序员,鄙视单身狗;在单身狗之间,才有语言、编辑器和操作系统的互相鄙视。不知为何,看到这句话的时候,我的内心阵阵绞痛。现在看看,这游戏也是如此。玩星际的,鄙视玩dota的;玩dota的,鄙视玩lol的;玩lol的,鄙视玩王者荣耀的。虽说王者荣耀处于游戏鄙视链的低端,但是不得不说,它确实有自己独到的魅力,正因为它降低了玩家的门槛,才有了如今的全民王者的热潮。你永远不知道自己匹配的队友和对手是老人,还是小孩。或者换种说法,是人,还是动物?

毫无疑问,王者荣耀从全民热度等诸多表现上看,是非常成功的游戏。可谓男女老少通吃,本文不讨论到底是女大学生坑,还是小学生坑,这样高难度的问题。咱玩点简单的,让我先看一款王者荣耀神器-王者荣耀盒子。《王者荣耀盒子》是专门为《王者荣耀》玩家量身打造的一款攻略应用,可谓上分必备神器,这里有职业选手教你英雄出装、铭文搭配和各种对线团战技巧,同时它也整合最全的游戏咨询以及游戏实时动态。先看看它长什么样:
APP下载地址:APP下载–>点我
本节课的内容,就是爬取《王者荣耀盒子》这款APP上的信息,废话不多说,直接开始实战!
3 准备工作
1 什么是Fiddler?
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。使用了Fiddler之后,web客户端和服务器的请求如下所示:
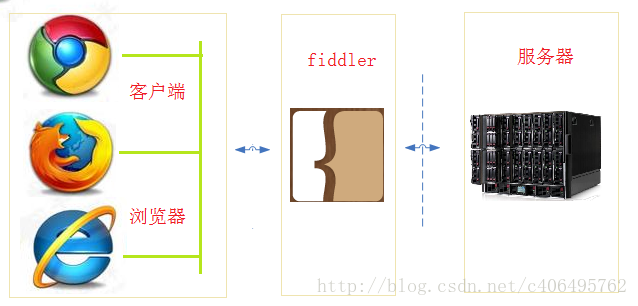
利用可以设置代理的这个特点,我们就可以对手机APP进行抓包了。怎么设置?不急不急,让我先把Fiddler安装上吧!
Fiddler下载地址:Fiddler下载–>点我
傻瓜式安装,一键到底。Fiddler软件界面如图所示:
2 手机APP抓包设置
1 Fiddler设置
打开Fiddler软件,打开工具的设置。(Fiddler软件菜单栏:Tools->Options)
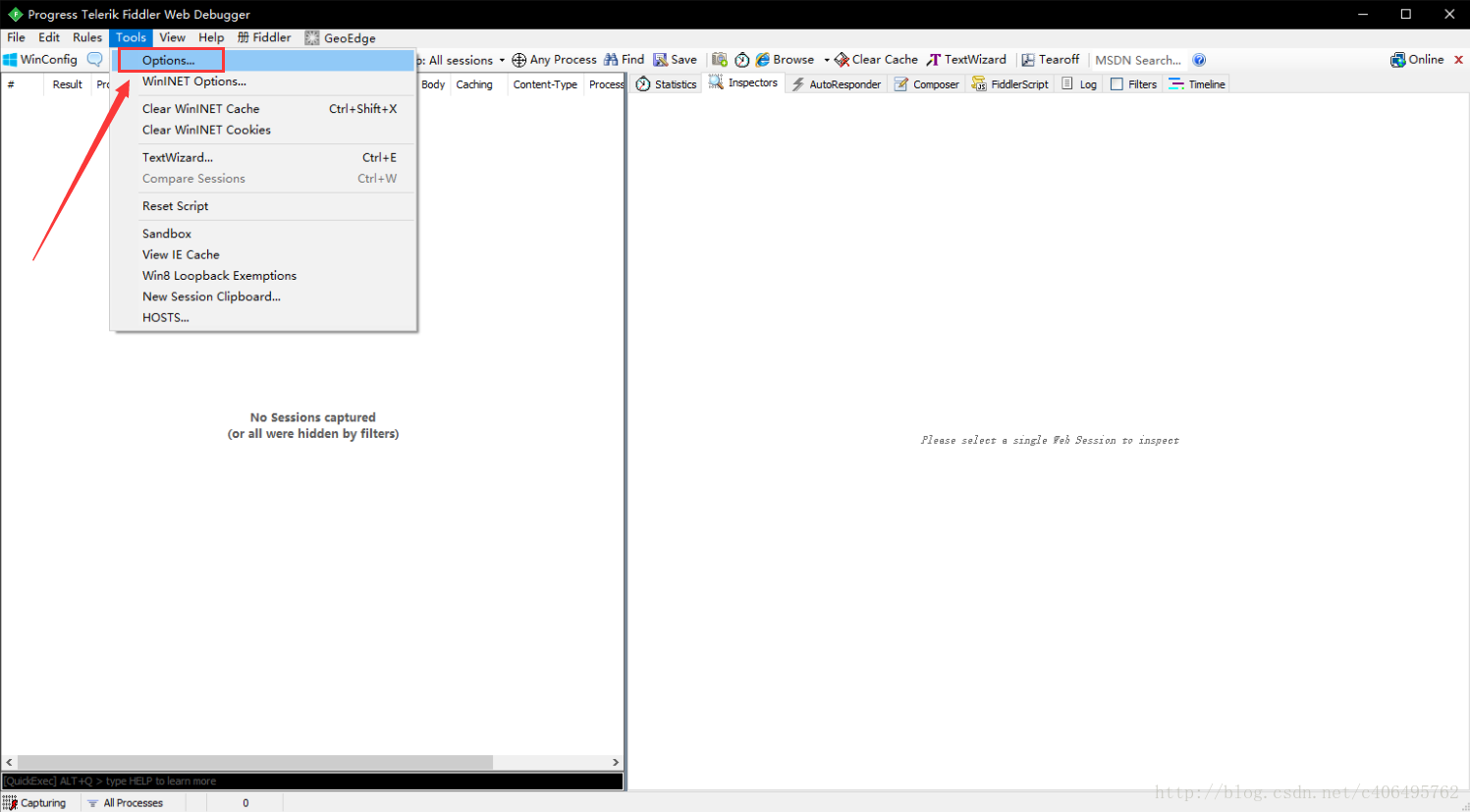
在HTTPS中设置如下:
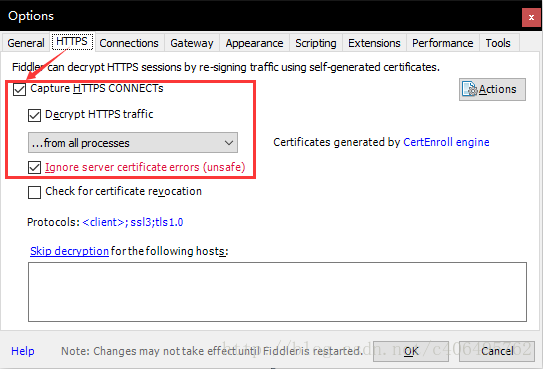
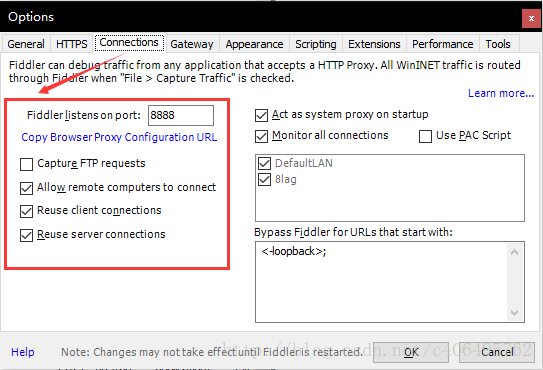
在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突:
2 安全证书下载
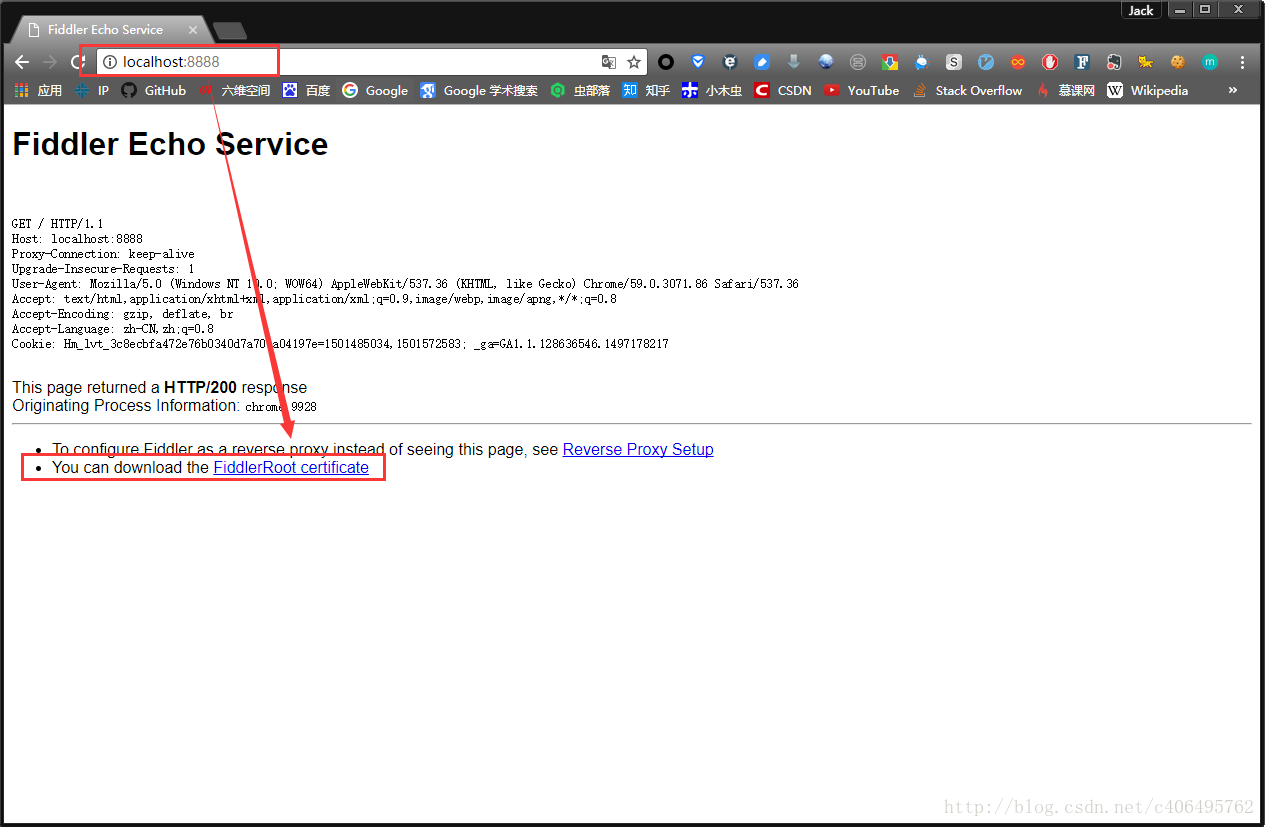
在电脑浏览器中输入地址:http://localhost:8888/,点击FiddlerRoot certificate,下载安全证书:
3 安全证书安装
证书是需要在手机上进行安装的,这样在电脑Fiddler软件抓包的时候,手机使用电脑的网卡上网才不会报错。
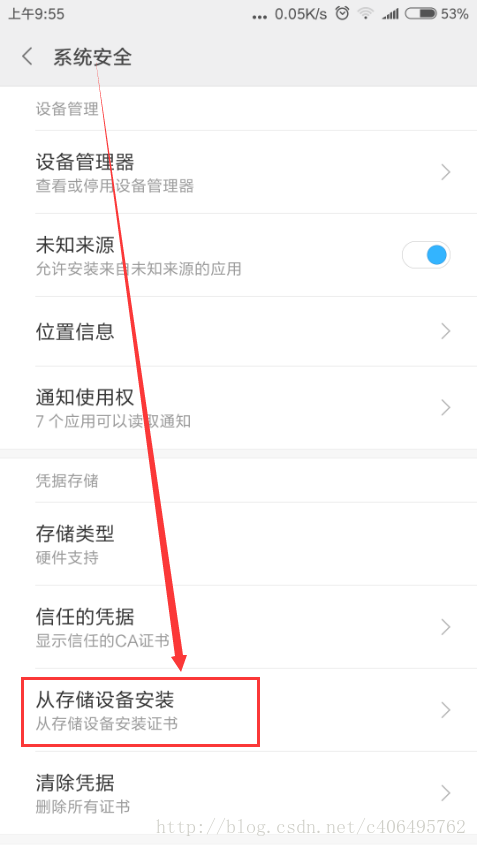
将下载好的FiddlerRoot.cer安装证书拷贝到手机中,然后进行证书安装(以小米5手机为例),设置(Settings)->(系统和设备中的)更多设置->系统安全->从存储设备安装:
然后找到拷贝的FiddlerRoot.cer进行安装即可。安装好之后,可以在信任的凭证中找到我们已经安装好的安全证书,在用户中可以看到证书如下:

4 局域网设置
想要使用Fiddler进行手机抓包,首先要确保手机和电脑的网络在一个内网中,可以使用让电脑和手机都连接同一个路由器。当然,也可以让电脑开放WIFI热点,手机连入。这里,我使用的方法是,让手机和电脑同时连入一个路由器中。最后,让手机使用电脑的代理IP进行上网。
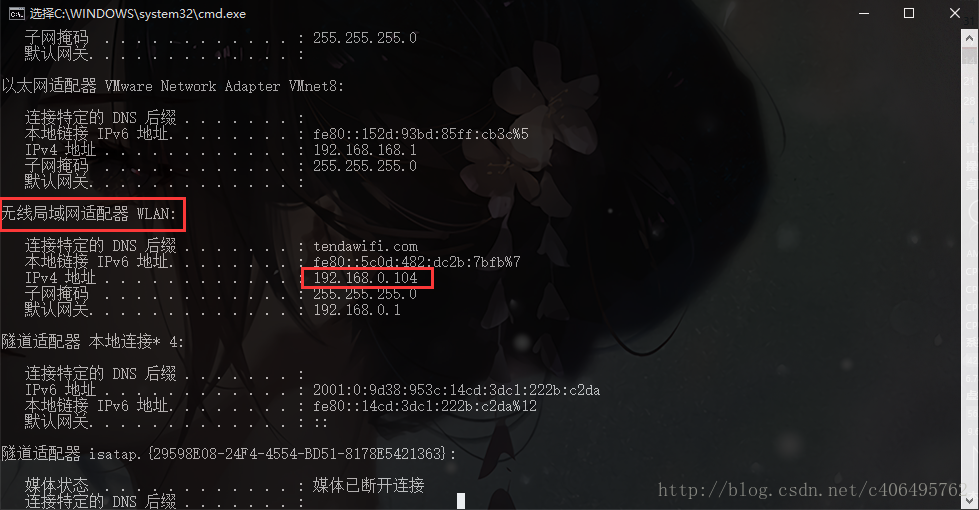
首先,查看电脑的IP地址,在cmd中使用命令ipconfig查看电脑IP地址。找到无线局域网WLAN的IPv4地址,记下此地址。
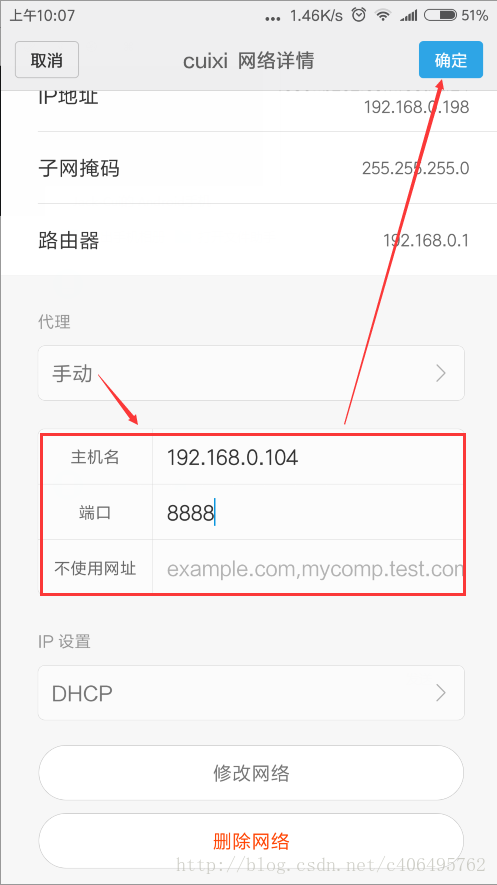
在手机上,点击连接的WIFI进行网络修改,添加代理。进行手动设置,主机名即为上图中找到的IP地址,端口号即为Fiddler设置中的端口号8888:
5 Fiddler手机抓包测试
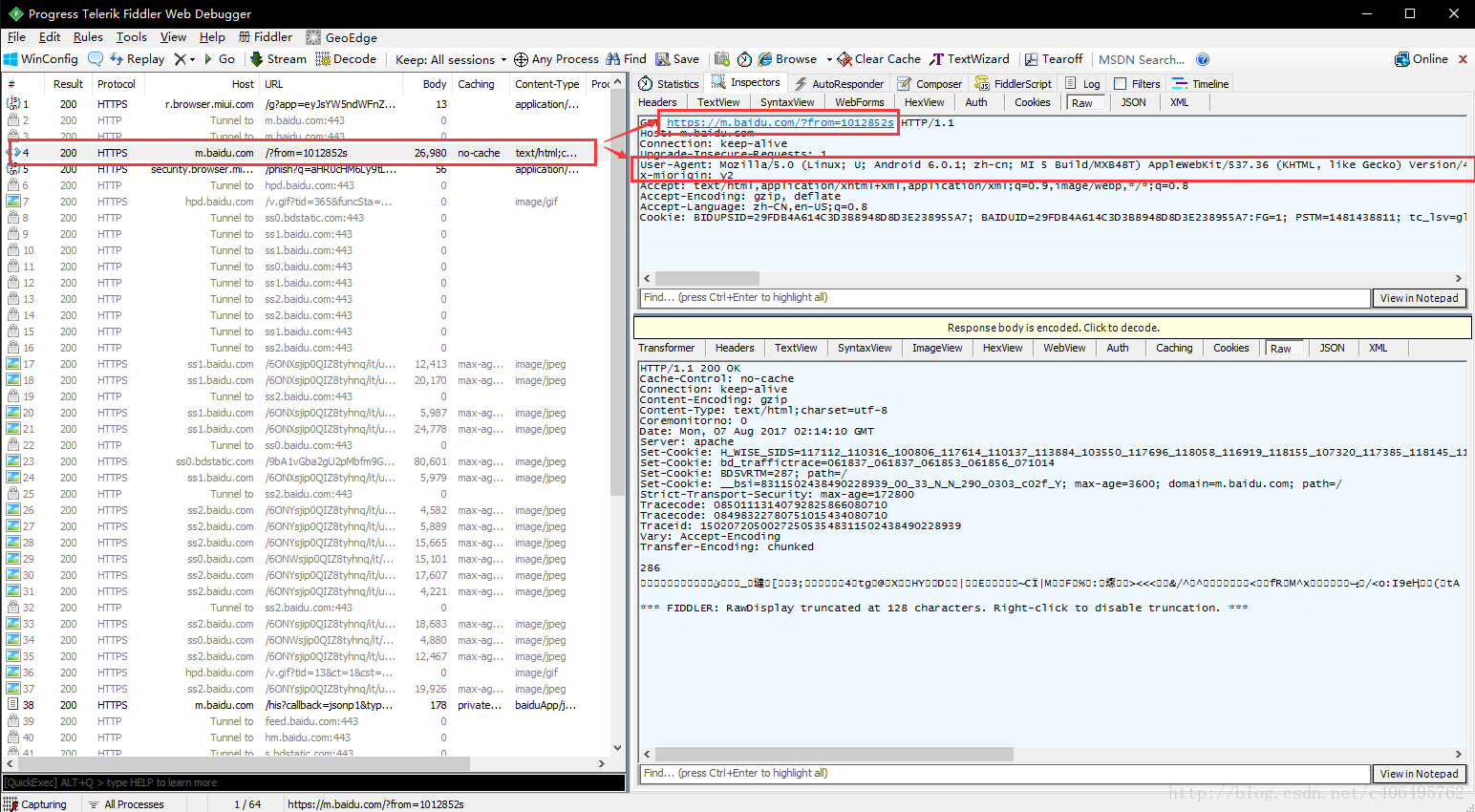
上述步骤都设置完成之后,用手机浏览器打开百度首页,我们就可以顺利抓包了,截图如下:
4 实战走起
1 下载英雄图片
先来个简单的例子热热身,我想将《英雄联盟盒子》中的英雄图片下载下来,该如何操作?

先使用Fiddler抓包看一下,在手机APP《英雄联盟盒子》中的菜单中点击英雄,电脑Fiddler就会抓包如下:
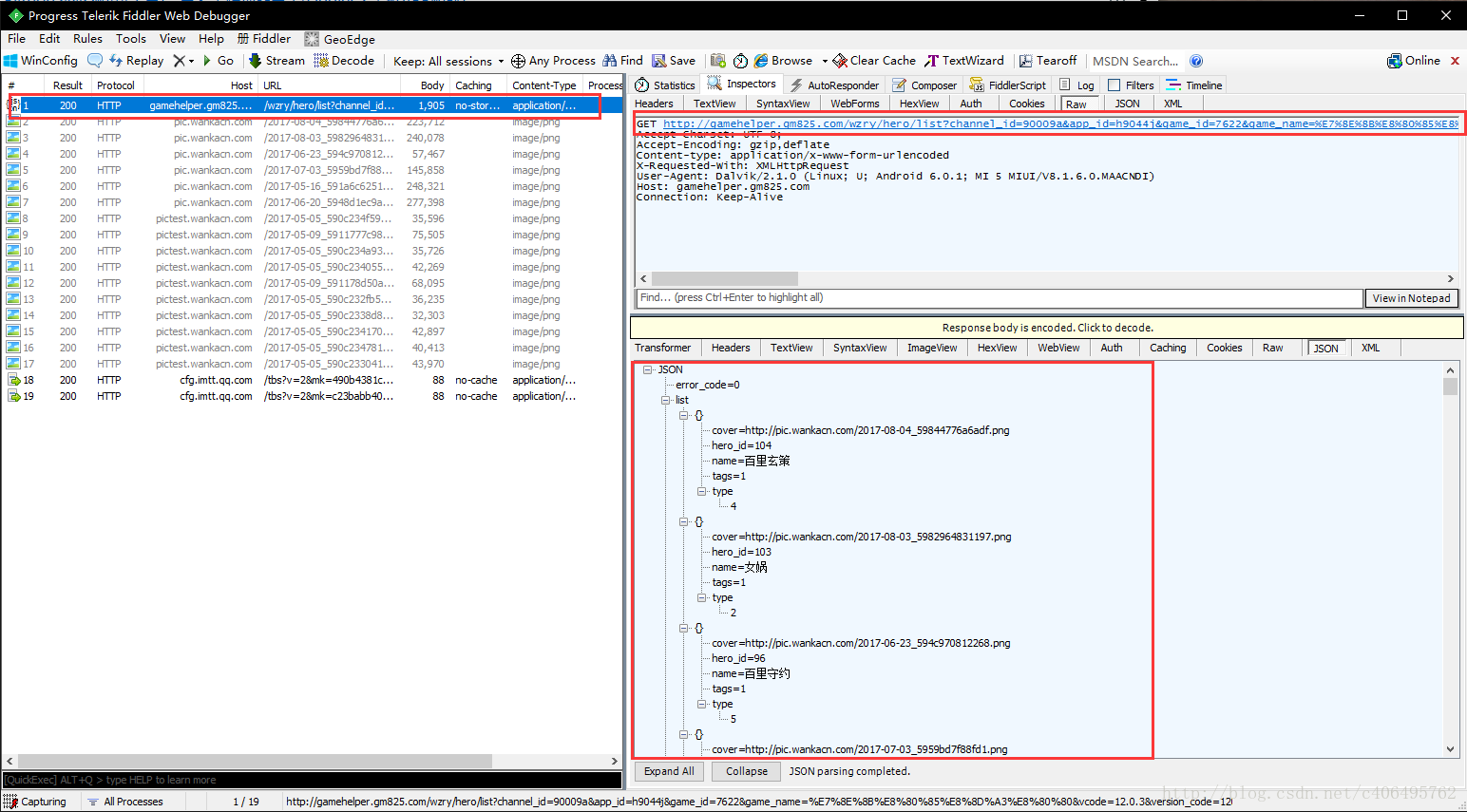
可以看到,GET请求的url地址,和返回的JSON格式的信息。那么编写代码如下:
#-*- coding: UTF-8 -*-
import requests
if __name__ == '__main__':
headers = {'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip,deflate',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 5 MIUI/V8.1.6.0.MAACNDI)',
'X-Requested-With': 'XMLHttpRequest',
'Content-type': 'application/x-www-form-urlencoded',
'Connection': 'Keep-Alive',
'Host': 'gamehelper.gm825.com'}
heros_url = "http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8"
req = requests.get(url = heros_url, headers = headers).json()
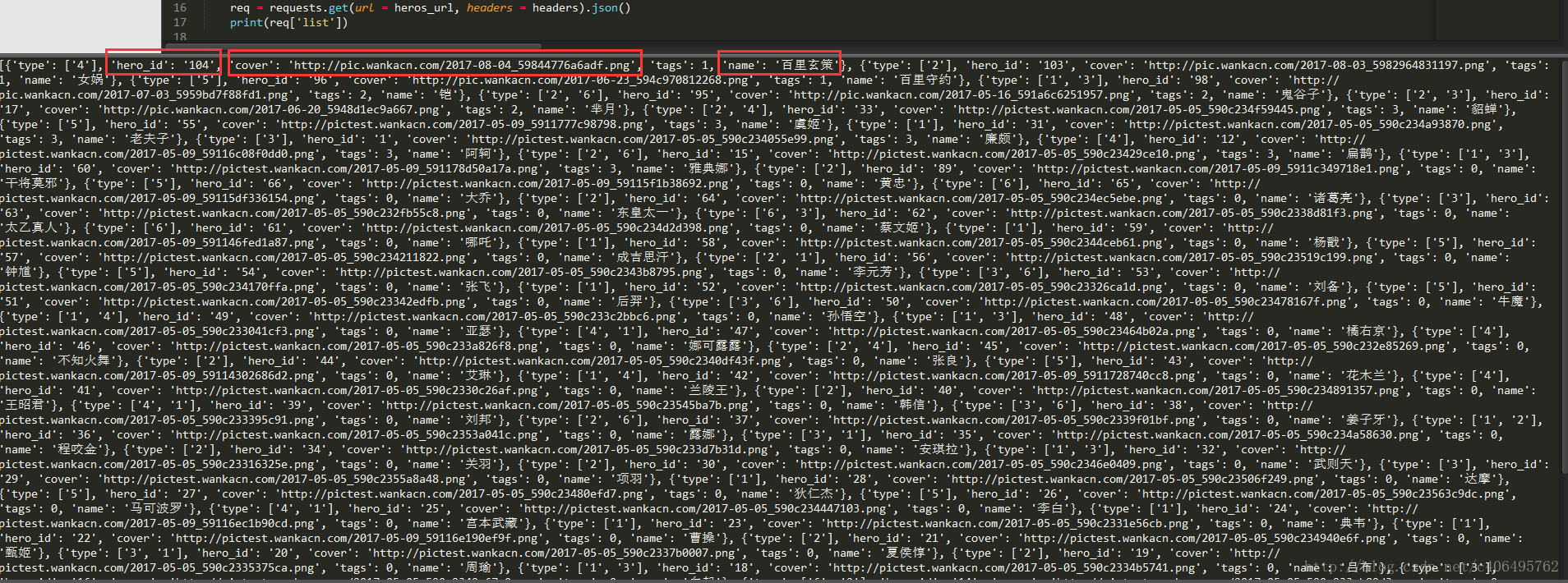
print(req['list']) 从代码运行结果中可以看到,百里玄策的英雄ID为104,他的图片存放地址为http://pic.wankacn.com/2017-08-04_59844776a6adf.png:
知道了这些信息,我们就可以将这些英雄的图片进行下载了,编写代码如下:
#-*- coding: UTF-8 -*-
from urllib.request import urlretrieve
import requests
import os
"""
函数说明:下载《英雄联盟盒子》中的英雄图片
Parameters:
heros_url - GET请求地址,通过Fiddler抓包获取
header - header信息
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-07
"""
def hero_imgs_download(heros_url,header):
req = requests.get(url = heros_url, headers = header).json()
hero_num = len(req['list'])
print('一共有%d个英雄' % hero_num)
hero_images_path = 'hero_images'
for each_hero in req['list']:
hero_photo_url = each_hero['cover']
hero_name = each_hero['name'] + '.jpg'
filename = hero_images_path + '/' + hero_name
if hero_images_path not in os.listdir():
os.makedirs(hero_images_path)
urlretrieve(url = hero_photo_url, filename = filename)
if __name__ == '__main__':
headers = {'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip,deflate',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 5 MIUI/V8.1.6.0.MAACNDI)',
'X-Requested-With': 'XMLHttpRequest',
'Content-type': 'application/x-www-form-urlencoded',
'Connection': 'Keep-Alive',
'Host': 'gamehelper.gm825.com'}
heros_url = "http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8"
hero_imgs_download(heros_url,headers)运行上述代码,看下结果,72个英雄的图片,分分钟搞定:
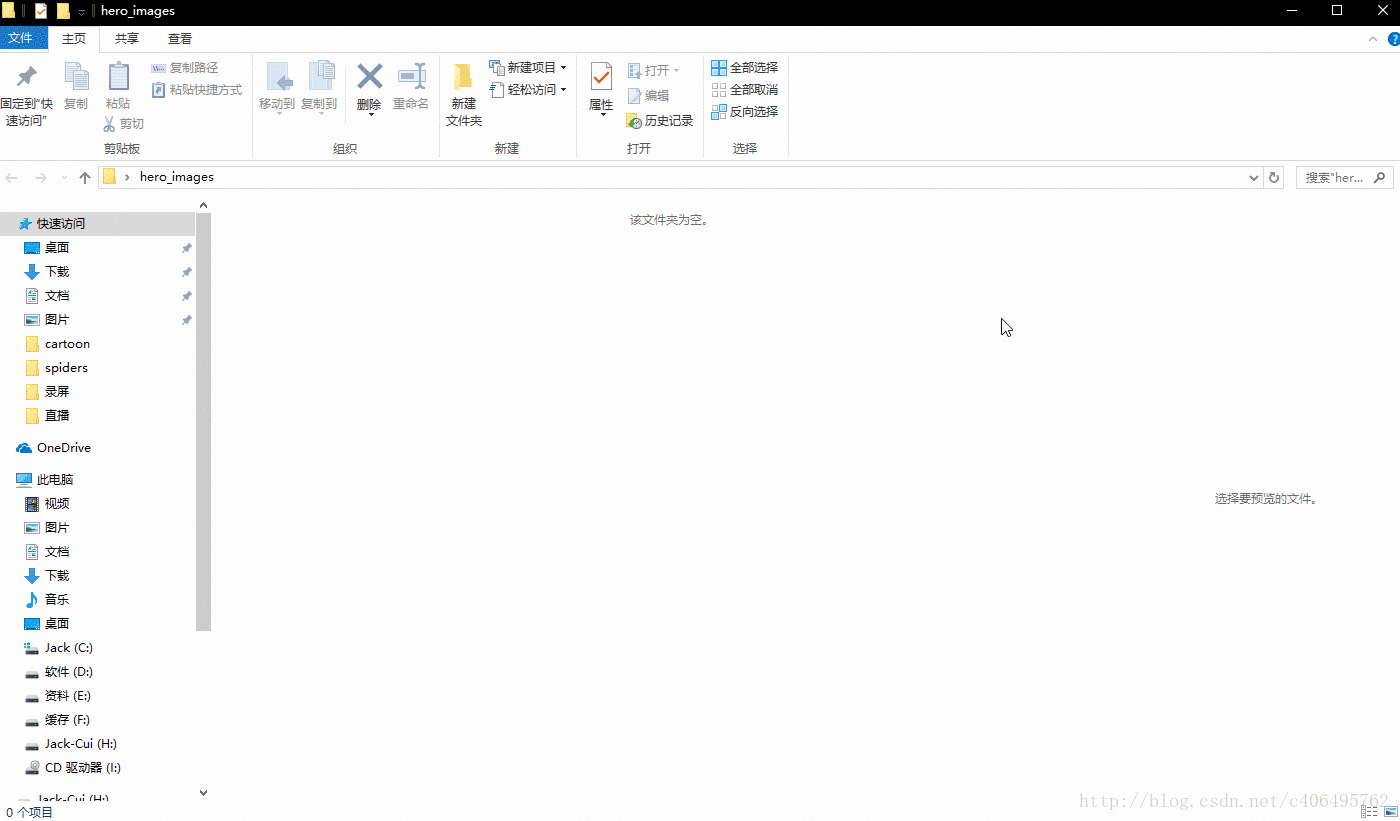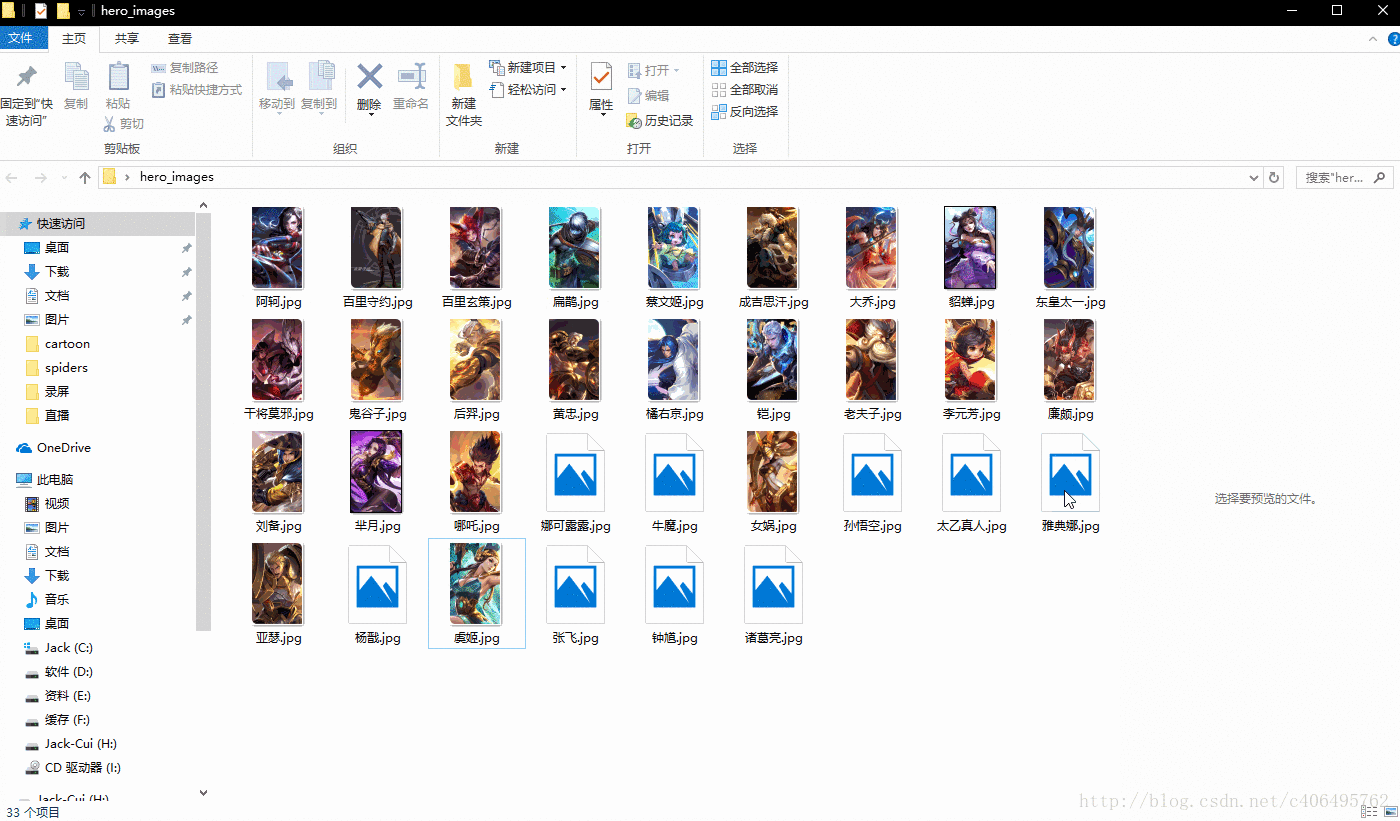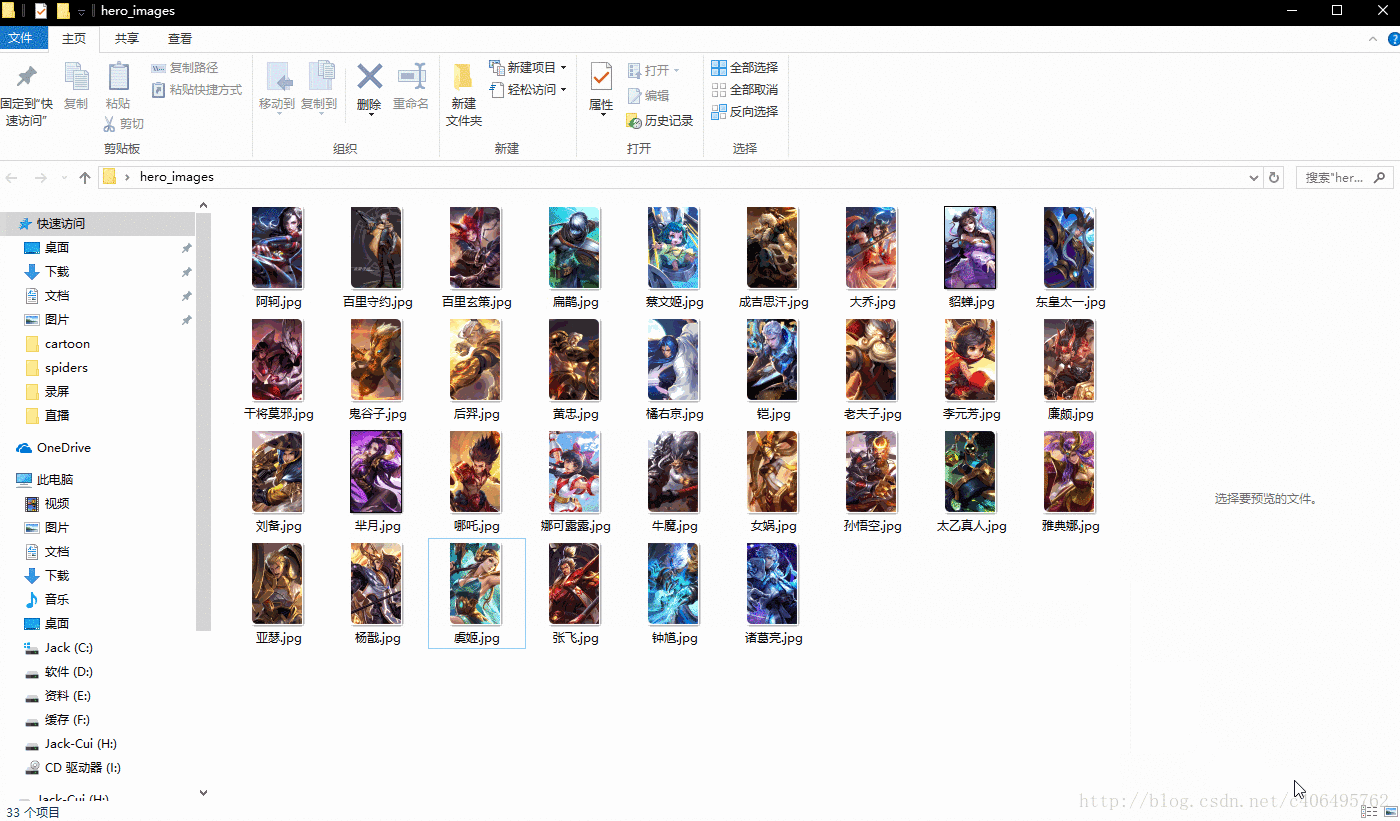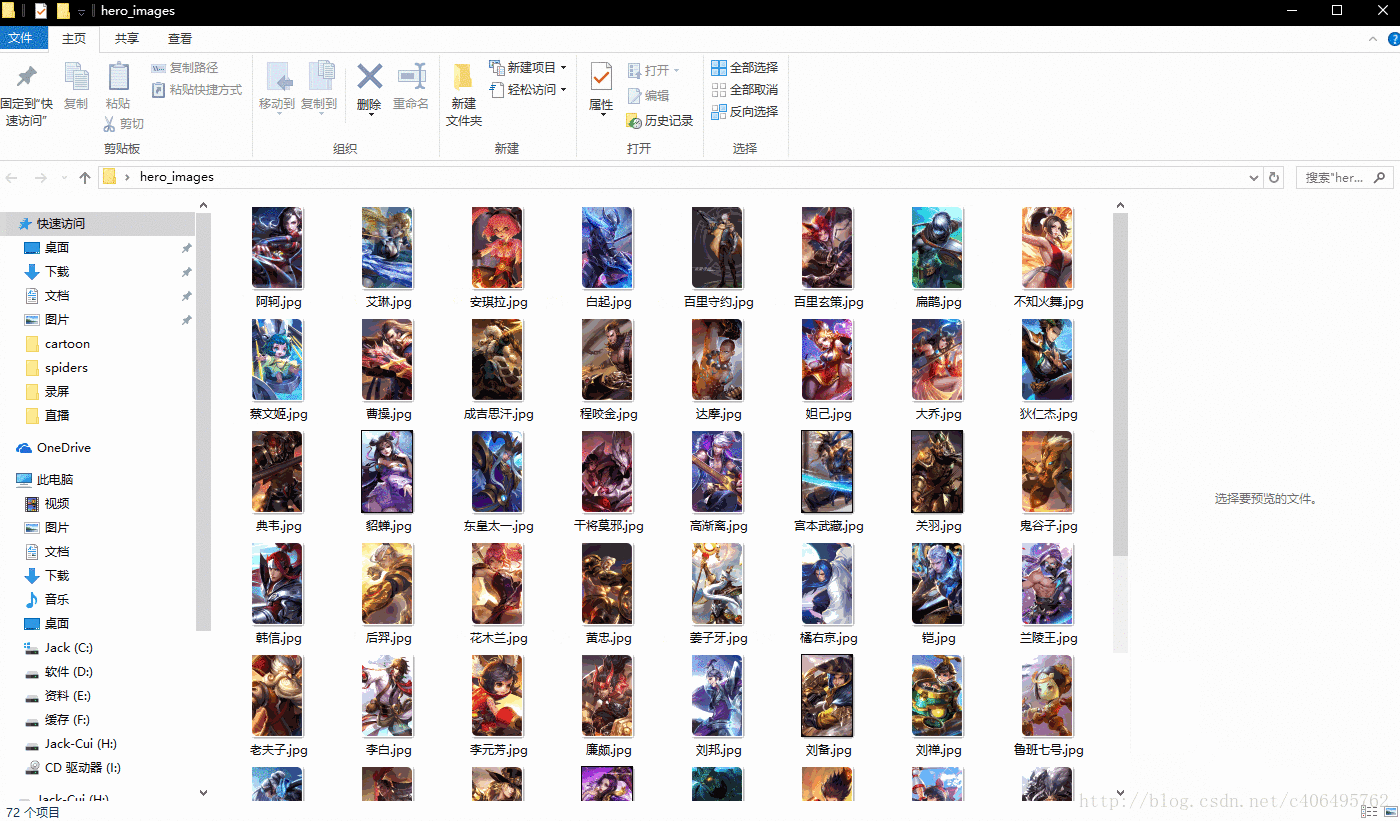
是不是很简单?接下来,再玩一个加点难度的。
2 英雄推荐出装查询助手
点击百里玄策这个英雄,可以看到,里面有他的简介,包括技能介绍,以及推荐出装等。那么,我们就了利用这个做一个自己的英雄出装查询小助手吧。

手机点击百里玄策这个英雄,可以在电脑Fiddler看到如下抓包内容:
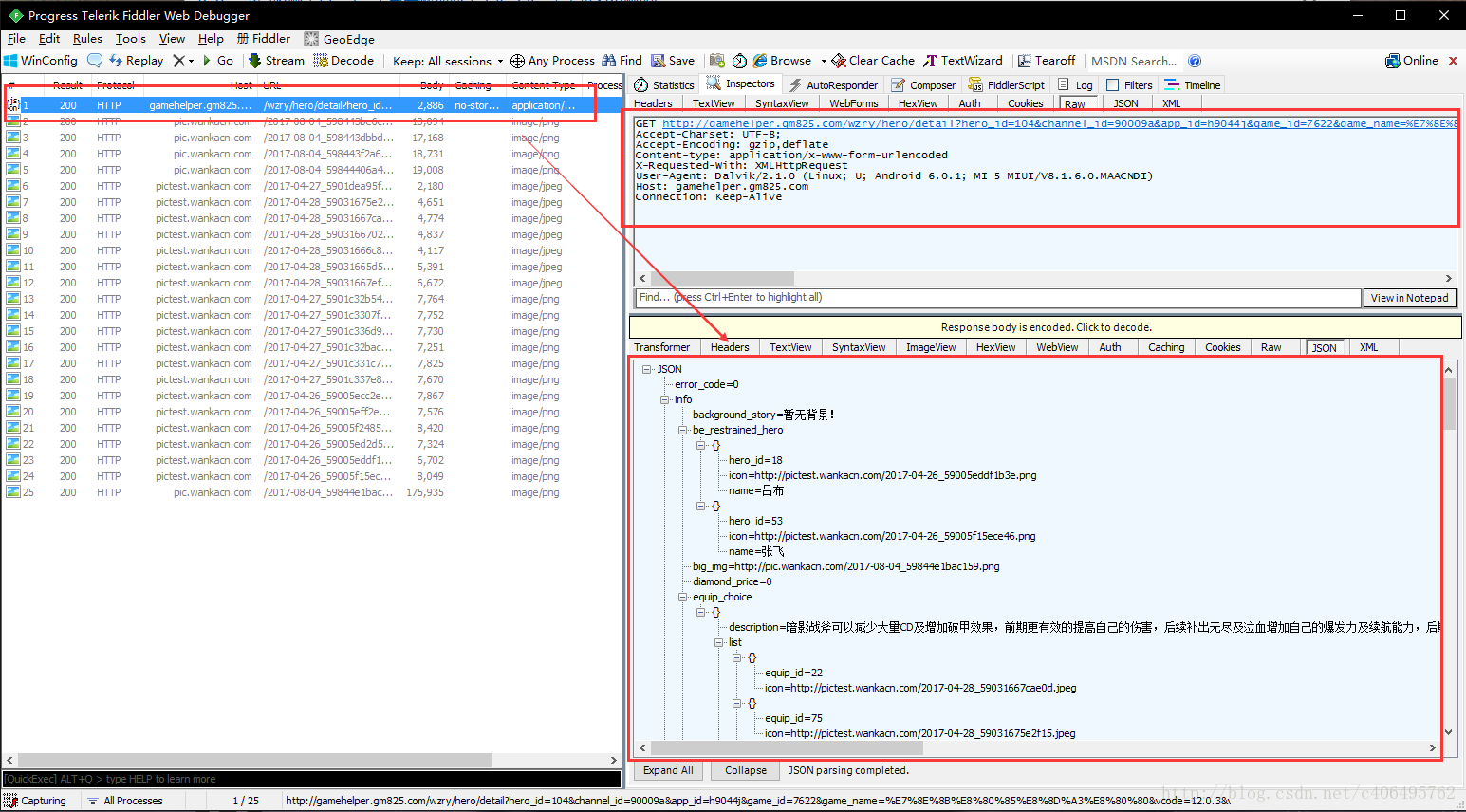
我们看下GET请求的URL:
http://gamehelper.gm825.com/wzry/hero/detail?hero_id=104&channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8 很有特点发现了吗?在url的hero_id为104,在上个小实例中,我们发现,这个104正好是英雄的id,那么是不是可以通过设置这个id来访问不同的英雄界面呢?测试一下答案就出来了,我们将id改为103,也就是女娲的hero_id,编写代码如下:
#-*- coding: UTF-8 -*-
import requests
if __name__ == '__main__':
headers = {'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip,deflate',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 5 MIUI/V8.1.6.0.MAACNDI)',
'X-Requested-With': 'XMLHttpRequest',
'Content-type': 'application/x-www-form-urlencoded',
'Connection': 'Keep-Alive',
'Host': 'gamehelper.gm825.com'}
hero_url = "http://gamehelper.gm825.com/wzry/hero/detail?hero_id={}&channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8".format('103')
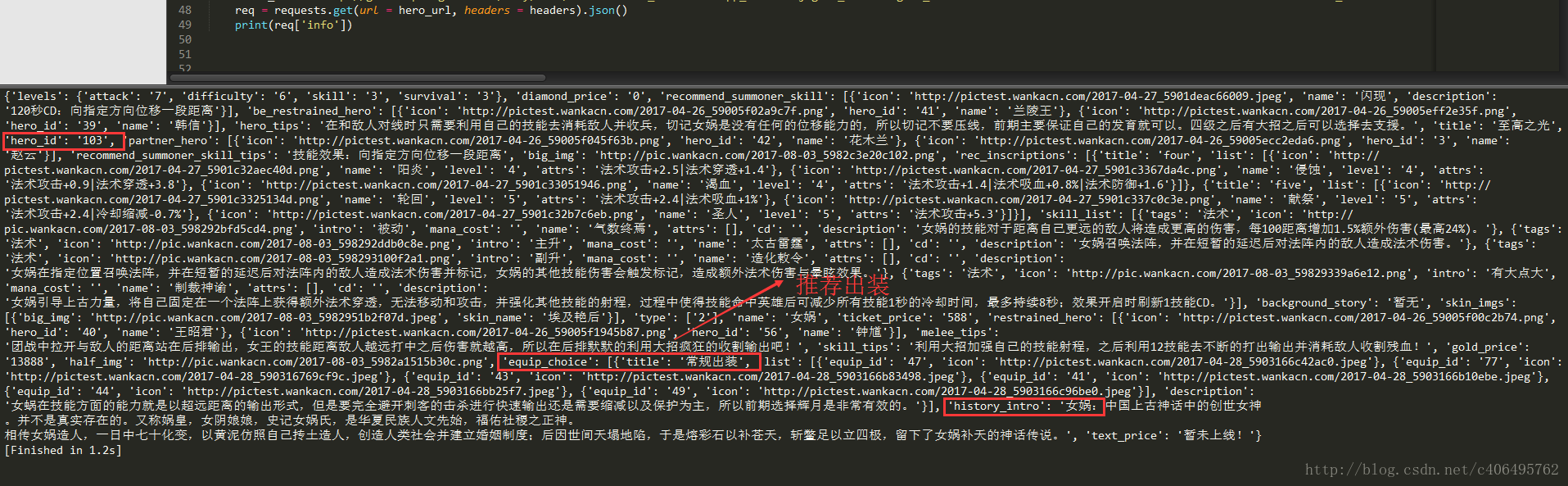
req = requests.get(url = hero_url, headers = headers).json()
print(req['info']) 运行上述代码,我们可以看到,打印的信息确实是英雄女娲的信息,返回的信息显示,这个英雄还没有上线。推荐出装保存在equip_choice中,可以看到这里没有给出装备的名字,只有装备的equip_id,那么在写推荐出装小程序之前,我们需要获取所有装备的ID。
怎样获取武器的信息?抓包方法同上,点击装备大全:

通过Fiddler抓包信息,编写代码如下:
#-*- coding: UTF-8 -*-
import requests
if __name__ == '__main__':
headers = {'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip,deflate',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 5 MIUI/V8.1.6.0.MAACNDI)',
'X-Requested-With': 'XMLHttpRequest',
'Content-type': 'application/x-www-form-urlencoded',
'Connection': 'Keep-Alive',
'Host': 'gamehelper.gm825.com'}
weapon_url = "http://gamehelper.gm825.com/wzry/equip/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8"
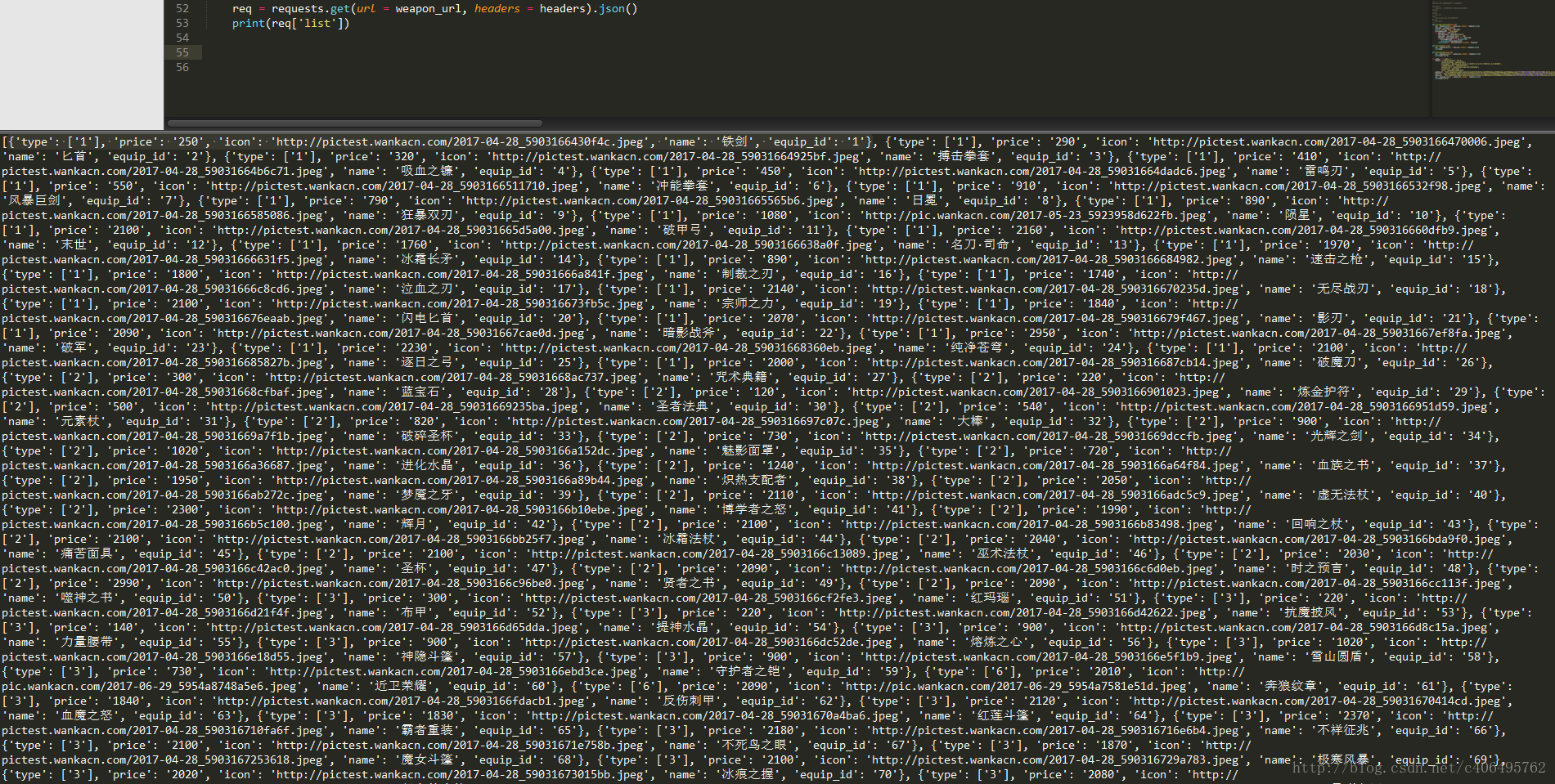
req = requests.get(url = weapon_url, headers = headers).json()
print(req['list'])这样我们就轻松得到了各个装备的信息:
到这里,我们就可以整合代码了,首先通过获取每个英雄的ID,然后根据每个英雄的ID,再获得英雄的详细信息,包括推荐出装,最后通过推荐的装备ID,找到装备的信息并打印出来。
根据实现效果,自己编写代码试一试如何?《王者荣耀》出装小助手,运行效果如图所示:




