上回说到糗事百科段子的分析,今天对另外一张表,也就是用户信息表的分析。
数据预处理
- 导入数据
import pandas as pd
import pymongo
import jieba.analyse
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
client = pymongo.MongoClient('localhost',port = 27017)
qiushi = client['qiushi']
qiushi_info = qiushi['qiushi_info']
data1 = pd.DataFrame(list(qiushi_info.find()))
qiushi = client['qiushi']
user_info = qiushi['user_info']
data2 = pd.DataFrame(list(user_info.find()))
data1为段子信息,data2为用户信息,二个表都有用户url,我们可以将其merge。
- merge
all_data = pd.merge(data1,data2,on='user_url')
all_data

- 去重
由于有些高玩用户发过多个段子,所以这里需要去重,通过用户id获取唯一值。
data3 = all_data.drop_duplicates(['id'])
段子手星座分布
对于数字类的分析,上次已经讲过几个,我主要是对段子手的星座和地区感兴趣,今天就分析下,大家也可以每个维度都分析下。
xingzuo = data3.groupby('constellation').size()
plt.figure(figsize=(10,6),dpi=80)
labels = list(xingzuo.index)
sizes = list(xingzuo)
plt.xlabel('星座')
plt.ylabel('用户个数')
plt.title('糗事百科用户星座分布图')
plt.bar(range(len(sizes)),sizes,tick_label=labels,color='#99CC01',alpha=0.7)#alpha为透明度
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.6)
plt.legend(['用户个数'])
for x,y in zip(range(len(sizes)),sizes):
plt.text(x, y,y, ha='center', va= 'bottom')

除了不详的之外,天秤座用户最多,白羊座最少。
天秤座常常追求和平和谐的感觉,他们善于交谈,沟通能力极强是他们最大的优点。但他们最大的缺点,往往是犹豫不决。天秤座的人容易将自己的想法加诸到别人身上,天秤座的人要小心这点
白羊座就像小孩子一样,直率、热情、冲动,但也十分的自我为中心和孩子气
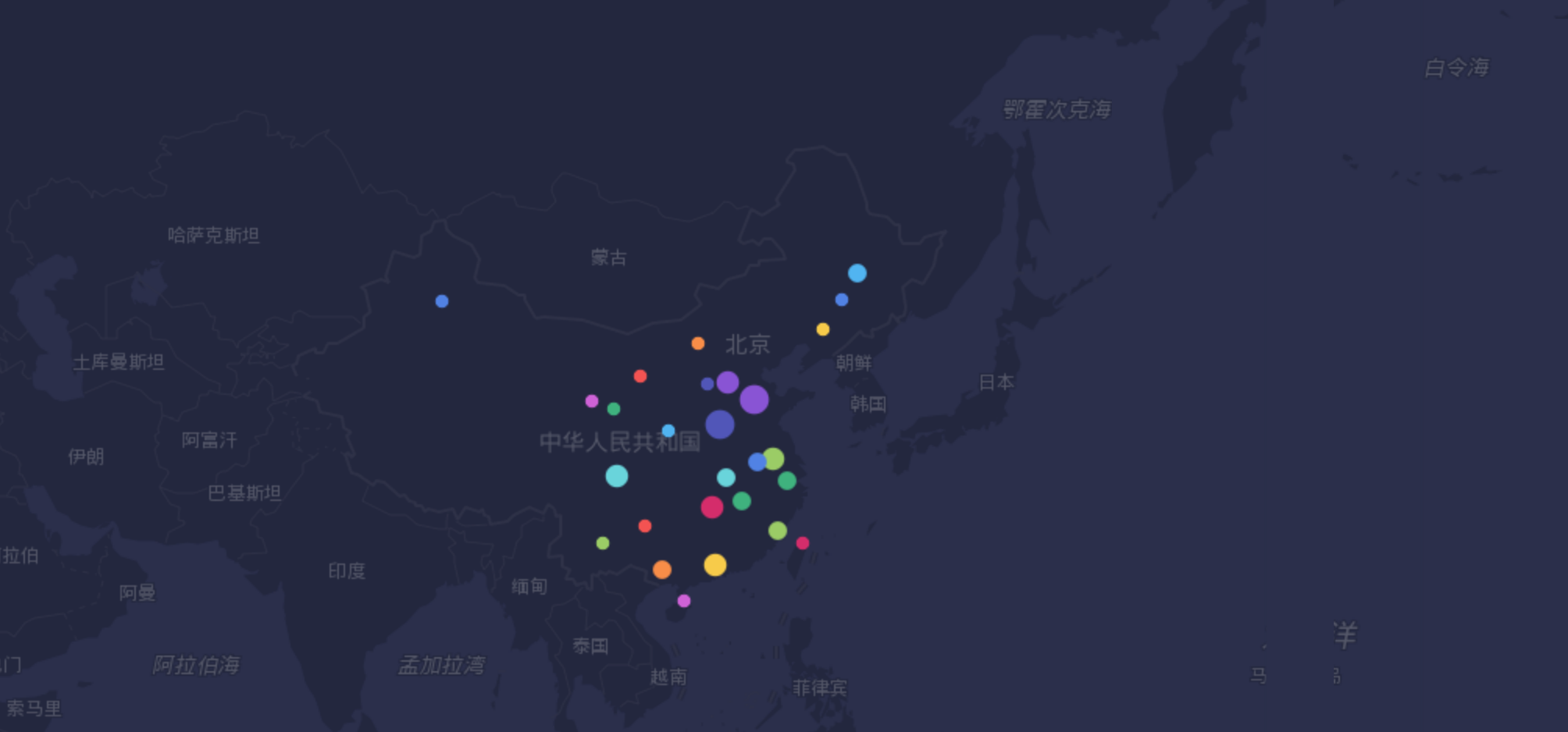
段子手地区分布
如图,数据是分省和市的,我们只提取省的数据,这部分可以在爬虫时进行处理。

list_1=[]
for i in range(0,273):
list_1.append(data3.iat[i,-6].split('· ')[0])
data3['province'] = list_1
data3

sheng = data3.groupby('province').size()
plt.figure(figsize=(20,6),dpi=80)
labels = list(sheng.index)
sizes = list(sheng)
plt.xlabel('省市')
plt.ylabel('用户个数')
plt.title('糗事百科用户省市分布图')
plt.bar(range(len(sizes)),sizes,tick_label=labels,color='#99CC01',alpha=0.7)#alpha为透明度
plt.grid(color='#95a5a6',linestyle='--', linewidth=1,axis='y',alpha=0.6)
plt.legend(['用户个数'])
for x,y in zip(range(len(sizes)),sizes):
plt.text(x, y,y, ha='center', va= 'bottom')

大家看看,哪个省盛产段子手。我们也可以调用百度api,获取省的经纬度,然后用BDP画出这样的地图。
总结
通过2个案例主要讲解了python数据分析的基本流程。
- 数据导入
- 数据预处理
- 数据整合
- 数据可视化