
“回归”与“树”
在讲解树回归之前,我们看看回归和树巧妙结合的原因。
线性回归的弊端
- 线性回归需要拟合所有样本点,在特征多且特征关系复杂时,构建全局模型的想法就显得太难。
- 实际生活中,问题很大程度上不是线性的,而是非线性的,所以线性回归的很容易欠拟合。
传统决策树弊端与改进
决策树可以解决数据的非线性问题,而且直观易懂,是否可以通过决策树来实现回归任务?
我们来回顾下之前讲过的决策树方法,其在划分子集的时候使用的方法是信息增益(我们也叫ID3方法),其方法只针对标称型(离散型)数据有效,很难用于回归;而且ID3算法切分过于迅速,容易过拟合,例如:一个特征有4个值,数据就会被切为四份,切分过后的特征在后面的过程中不再起作用。
CART(分类回归树)算法可以解决掉ID3的问题,该算法可用于分类和回归。我们来看看针对ID3算法的问题,CART算法是怎样解决的。
- 信息增益无法切分连续型数据,如何计算连续型数据的混乱程度?其实,连续型的数据计算混乱程度很简单,根本不需要信息熵的理论。我们只需要计算平方误差的总值即可(先计算数据的均值,然后计算每条数据到均值的差值,进行平方求和)。
- ID3方法切分太快,CART算法采用二元切分。
回归树
基于CART算法,当叶节点是分类值,就会是分类算法;如果是常数值(也就是回归需要预测的值),就可以实现回归算法。这里的常数值的求解很简单,就是该划分数据的均值。
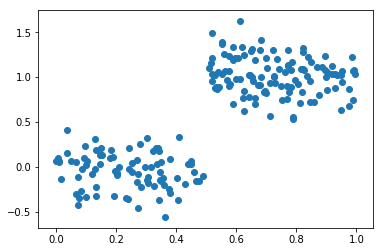
数据情况
首先,利用代码带入数据,数据情况如图所示。
from numpy import *
def loadDataSet(filename):
dataMat = []
fr = open(filename)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine))
dataMat.append(fltLine)
return dataMat
代码
其实CART算法直观(代码却比较多。。。),其实只用做两件事:切分数据和构造树。我们以这个数据为例:首先切分数据,找到一个中心点(平方误差的总值最小),这样就完成了划分(左下和右上),然后构造树(求左下和右上的均值为叶子节点)。我们来看代码:
def regLeaf(dataSet):
return mean(dataSet[:,-1])
def regErr(dataSet):
return var(dataSet[:,-1]) * shape(dataSet)[0]
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
tolS = ops[0];tolN = ops[1]
if len(set(dataSet[:,-1].T.tolist()[0])) == 1:
return None, leafType(dataSet)
m,n = shape(dataSet)
S = errType(dataSet)
bestS = inf; bestIndex = 0;bestValue = 0
for featIndex in range(n-1):
for splitVal in set((dataSet[:,featIndex].T.tolist())[0]):
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
newS = errType(mat0) + errType(mat1)
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
if (S - bestS) < tolS:
return None, leafType(dataSet)
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
return None, leafType(dataSet)
return bestIndex, bestValue
def binSplitDataSet(dataSet, feature, value):
mat0 = dataSet[nonzero(dataSet[:, feature] > value)[0], :]
mat1 = dataSet[nonzero(dataSet[:, feature] <= value)[0], :]
return mat0,mat1
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
if feat == None: return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
看下结果,和我想的是一致的。

模型树
回归树的叶节点是常数值,而模型树的叶节点是一个回归方程。
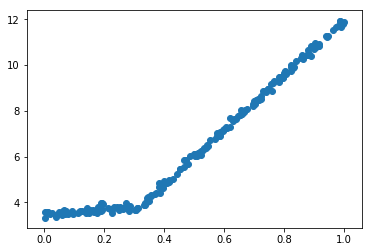
数据情况
读入数据进行可视化,你会发现,这种数据如果用回归树拟合效果不好,如果切分为两段,每段是一个回归方程,就可以很好的对数据进行拟合。
代码
前面的代码大部分是不变的,只需要少量修改就可以完成模型树。
def modelLeaf(dataSet):
ws, X, Y = linearSolve(dataSet)
return ws
def modelErr(dataSet):
ws, X, Y = linearSolve(dataSet)
yHat = X * ws
return sum(power(Y - yHat, 2))
def linearSolve(dataSet):
m, n = shape(dataSet)
X = mat(ones((m, n)))
Y = mat(ones((m, 1)))
X[:, 1: n] = dataSet[:, 0: n-1]
Y = dataSet[:, -1]
xTx = X.T * X
if linalg.det(xTx) == 0.0:
raise NameError('错误')
ws = xTx.I * (X.T * Y)
return ws, X, Y
结果如图所示:

算法优缺点
- 优点:可对复杂数据进行建模
- 缺点:容易过拟合
