scikit-learn(以下简称为sklearn)是用Python开发的机器学习库,其中包含大量机器学习算法、数据集,是数据挖掘方便的工具。本教程参考《Python机器学习及实战》、《scikit-learn机器学习》和sklearn的官方文档,详细讲解如何使用sklearn实现机器学习算法。首先,依旧讲讲写本系列教程的原因:第一,相比于直接编写各种算法,sklearn简单容易上手;第二,参考书籍有些部分讲解不细致,sklearn版本的更新,官方文档虽然齐全,但是是英文等等,希望通过编写这个教程,可以让读者轻松上手机器学习;第三,依旧是本人的学习记录过程。
本系列教程特点:
- 好学易用
- 案例实操多
哪些读者可以使用:
- 了解机器学习的基本术语
- 会Python语言
- 会numpy和pandas库的使用
sklearn小抄
在愉悦的做一个调包侠之前,老衲给予施主一份绝世宝典(sklearn小抄),之后你的任督二脉将会打开,在sklearn调包的路上所向披靡。首先上宝典,高清pdf请前往此处下载:
(链接:https://pan.baidu.com/s/12c0CIP6c6rgc4Y5zEnUJxA 密码:13au)。

数据导入
sklearn支持的数据格式有numpy数组和pandas的DataFrame格式,当然,sklearn也提供了一些数据集,通过下面代码可以导入数据集(具体数据集见后文)。
from sklearn import datasets
数据预处理
“garbage in garbage out”,一个好的模型很大程度上基于一个干净有效的源数据,所以在训练模型之前,需要针对已有数据进行清洗和处理。数据预处理的方法有很多:数据的缺失值清洗;数据标准化/中心化/归一化;哑编码;生成多项式特征等等,这个需要根据具体的数据进行相对应的处理。
模型选择
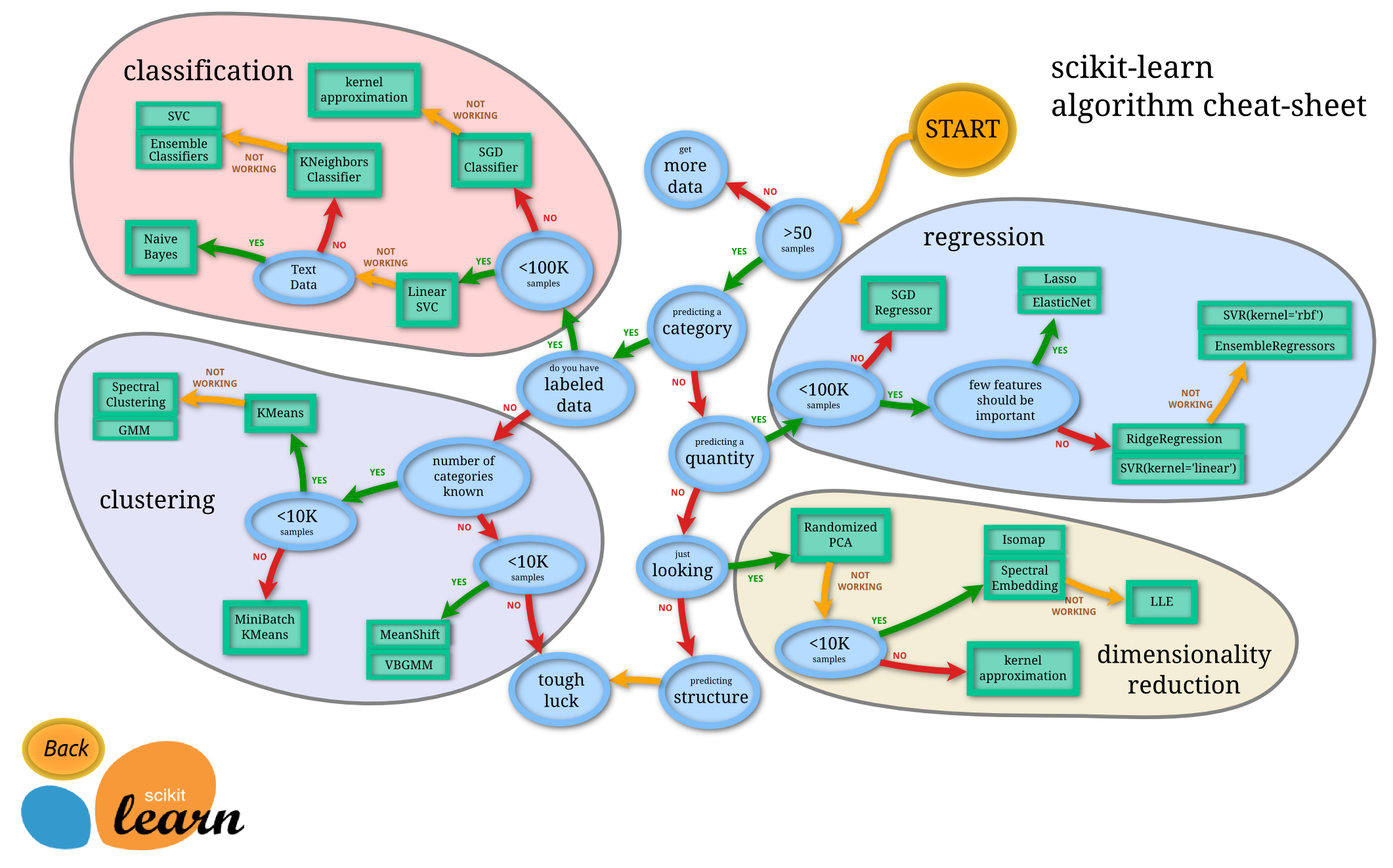
针对不同的问题需要选择不同的模型,有label标签且为离散值的为分类,有label标签且为连续值的是回归,无label的就要用无监督的方法了。但针对某个特定问题,如何选择算法了,可以看下图。
但很不幸的是:“没有免费的午餐定理”告诉我们,脱离具体问题去讨论选择什么算法更好是毫无意义的,在现实建模中,我们通过多个模型比较评估结果来选择最终模型。
模型训练
在模型训练前,需要将数据集切分为训练集和测试集(73开或者其它)。sklearn训练模型很简单,在具体实例中讲解。
模型测试
针对不同类模型,模型的评价指标都不同,具体可看小抄和sklearn.metrics模块。在模型测试中,我们常常使用交叉验证的方法。
模型优化
模型一般都是有很多参数的,如何选择最优的参数,可使用网格搜索和随机参数优化。
tips
针对各个过程的详细介绍,会在具体案例中讲解。