
天下武功,唯快不破。今天就正式讲解如何通过《sklearn小抄》武林秘籍,成为一代宗师调包侠。欲练此功,必先自宫;就算自宫,未必成功;若不自宫,也能成功。传说江湖(机器学习领域)有两大派别:一是学术派,该派资历高,家境好,多为名门世家(学历高,数学好),重基础(数学推导和理论知识);一是实践派,以找人切磋为主(实践为主),多在切磋中提升能力。《机器学习实战》系列为学术派,《sklearn调包侠》系列为实践派,该系列会简单讲解原理,多引用于《机器学习实战》系列的算法讲解(必要的内力),然后在实操中完成各机器学习算法。
tips:在本篇中会按小抄详细过一遍,之后就可能会随意一些。
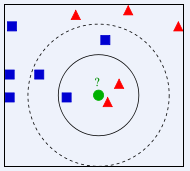
KNN算法原理
计算测试样本与每个训练样本的距离,取前k个距离最小的训练样本,最后选择这k个样本中出现最多的分类,作为测试样本的分类。
如图所示,绿色的为测试样本,当k取3时,该样本就属于红色类;当k取5时,就属于蓝色类了。所以k值的选择很大程度影响着该算法的结果,通常k的取值不大于20。
实战——糖尿病预测
数据导入
本数据可在kaggle中进行下载,读者可以去我的百度云链接进行下载。
(链接:https://pan.baidu.com/s/1gqaGuQ9kWZFfc-SXbYFDkA 密码:lxfx)
该数据为csv格式文件,我们通过pandas读入:
import numpy as np
import pandas as pd
data = pd.read_csv('data/pima-indians-diabetes/diabetes.csv')
data.head()
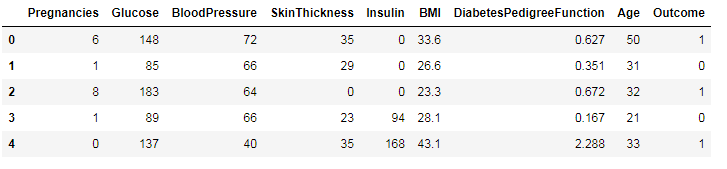
我们简单看下各字段的意思:
- Pregnancies:怀孕的次数
- Glucose:血浆葡萄糖浓度
- BloodPressure:舒张压
- SkinThickness:肱三头肌皮肤皱皱厚度
- Insulin: 胰岛素
- BMI:身体质量指数
- Dia....:糖尿病血统指数
- Age:年龄
- Outcone:是否糖尿病,1为是
我们把数据划分为特征和label,前8列为特征,最后一列为label。
X = data.iloc[:, 0:8]
Y = data.iloc[:, 8]
切分数据集
在模型训练前,需要将数据集切分为训练集和测试集(73开或者其它),这里选择82开,使用sklearn中model_selection模块中的train_test_split方法。
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=22)
这里的test_size为测试集的比例,random_state为随机种子,这里可设置任意数字,保证下次运行同样可以选择出对应的训练集和测试集。
数据预处理
这里没有对数据进行预处理。
模型训练与评估
KNN算法使用sklearn.neighbors模块中的KNeighborsClassifier方法。常用的参数如下:
- n_neighbors,整数,也就是k值。
- weights,默认为‘uniform’;这个参数可以针对不同的邻居指定不同的权重,也就是说,越近可以权重越高,默认是一样的权重。‘distance’可以设置不同权重。
在sklearn.neighbors还有一个变种KNN算法,为RadiusNeighborsClassifier算法,可以使用一定半径的点来取代距离最近的k个点。
接下来,我们通过设置weight和RadiusNeighborsClassifier,对算法进行比较。
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
model1 = KNeighborsClassifier(n_neighbors=2)
model1.fit(X_train, Y_train)
score1 = model1.score(X_test, Y_test)
model2 = KNeighborsClassifier(n_neighbors=2, weights='distance')
model2.fit(X_train, Y_train)
score2 = model2.score(X_test, Y_test)
model3 = RadiusNeighborsClassifier(n_neighbors=2, radius=500.0)
model3.fit(X_train, Y_train)
score3 = model3.score(X_test, Y_test)
print(score1, score2, score3)
#result
#0.714285714286 0.701298701299 0.649350649351
可以看出默认情况的KNN算法结果最好。
交叉验证
通过上述结果可以看出:默认情况的KNN算法结果最好。这个判断准确么?答案是不准确,因为我们只是随机分配了一次训练和测试样本,可能下次随机选择训练和测试样本,结果就不一样了。这里的方法为:交叉验证。我们把数据集划分为10折,每次用9折训练,1折测试,就会有10次结果,求十次的平均即可。当然,可以设置cv的值,选择不同的折数。
from sklearn.model_selection import cross_val_score
result1 = cross_val_score(model1, X, Y, cv=10)
result2 = cross_val_score(model2, X, Y, cv=10)
result3 = cross_val_score(model3, X, Y, cv=10)
print(result1.mean(), result2.mean(), result3.mean())
# result
# 0.712235133288 0.67966507177 0.64976076555
可以看出,还是默认情况的KNN算法结果最好。
模型调优
无模型调优。




