
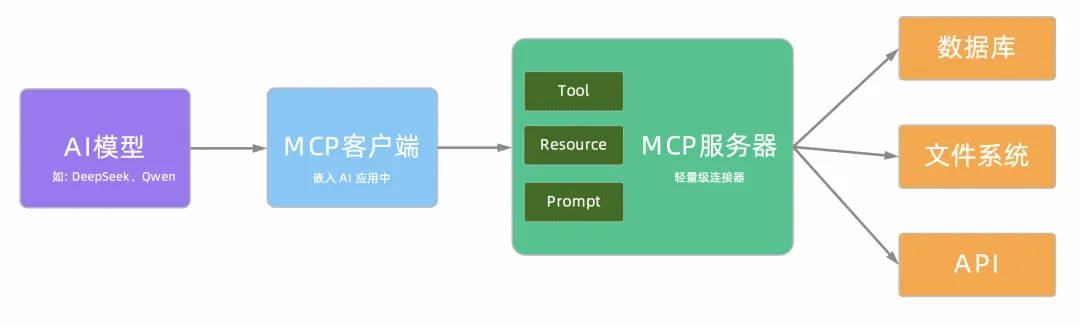
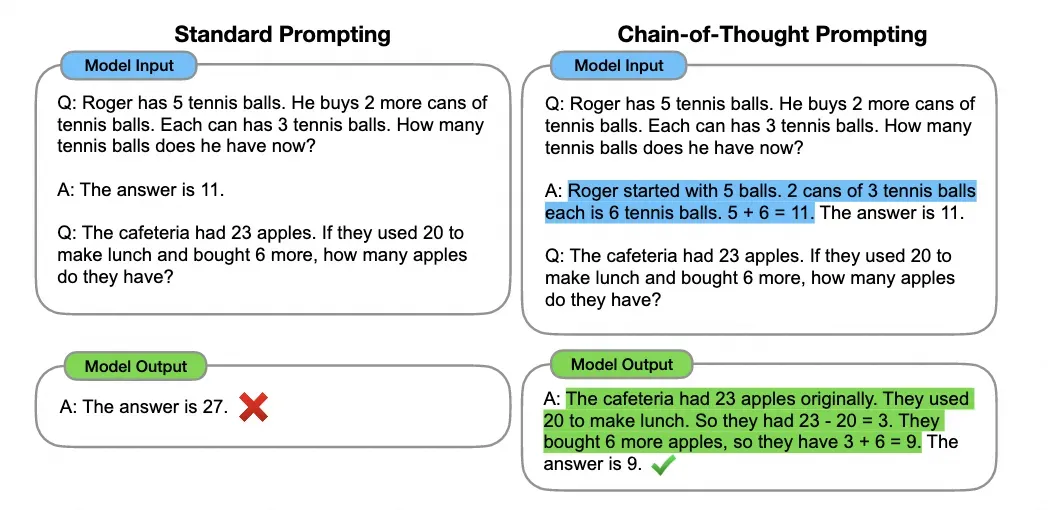
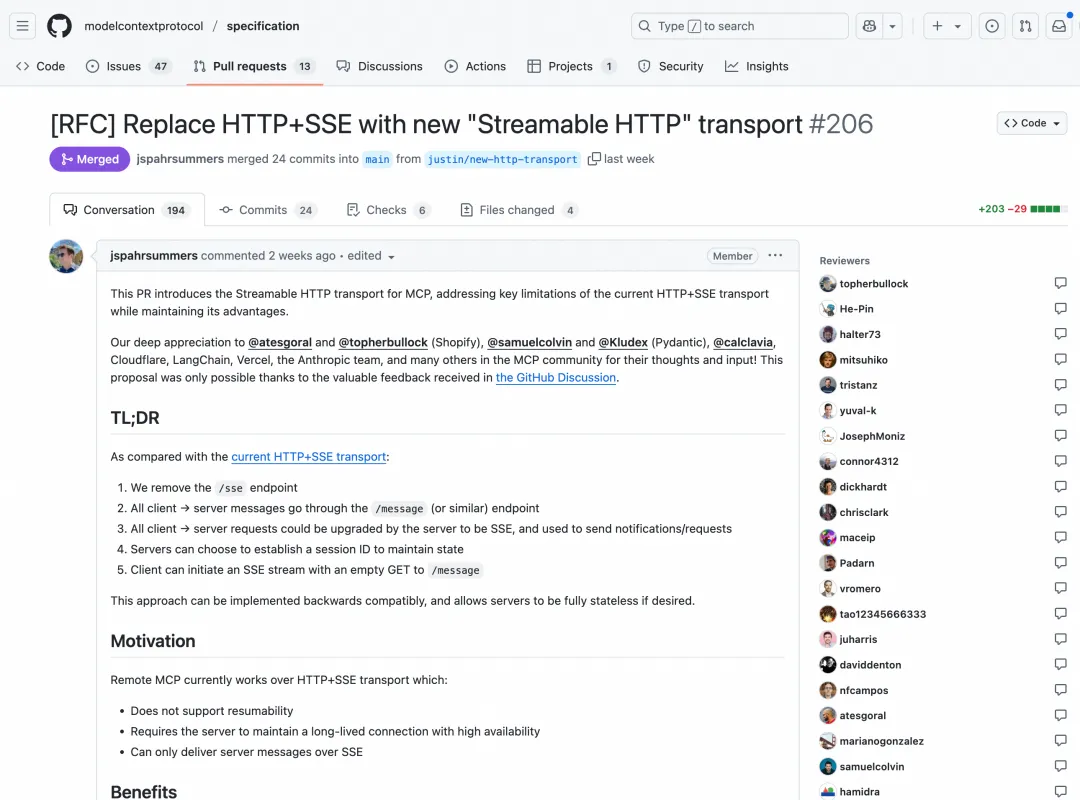
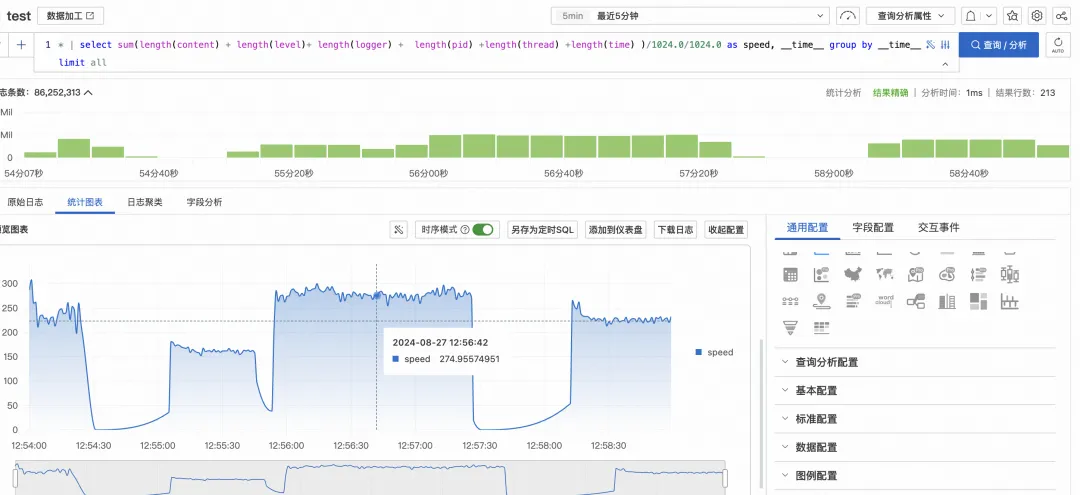
如何0代码将存量 API 适配 MCP 协议?




















你好,我是AI助理
可以解答问题、推荐解决方案等