微信登录界面
微信网页版使用了UUID含义是通用唯一识别码来保证二维码的唯一性。
先用一个伪造的appid获得uuid。
params = {
'appid': 'wx782c26e4c19acffb',
'fun': 'new',
'lang': 'zh_CN',
'_': int(time.time()),
}
不伪造的话,会有400错误,拿不到uuid。
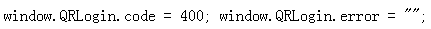
二维码在网页源代码也是查不到的,这时就需要uuid了。
url = 'https://login.weixin.qq.com/qrcode/' + uuid
微信的登录需要多次请求数据,并根据返回的数据进行提取。
扫码成功的返回如果是200,证明扫码成功。
然后需要模拟微信的初始化同步过程。
同步完成之后,打印通信录。
微信确实复杂!这么做的话不留下cookie,提高了安全性。web QQ的原理也差不多,毕竟一家做的。
import os
import re
import time
import sys
import subprocess
import requests
import xml.dom.minidom
import json
session = requests.session()
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 5.1; rv:33.0) Gecko/20100101 Firefox/33.0'
}
QRImgPath = os.path.split(os.path.realpath(__file__))[0] + os.sep + 'webWeixinQr.jpg'
uuid = ''
tip = 0
base_uri = ''
redirect_uri = ''
skey = ''
wxsid = ''
wxuin = ''
pass_ticket = ''
deviceId = 'e000000000000000'
BaseRequest = {}
ContactList = []
My = []
SyncKey = ''
def getUUID():
global uuid,session
url = 'https://login.weixin.qq.com/jslogin'
params = {
'appid': 'wx782c26e4c19acffb',
'fun': 'new',
'lang': 'zh_CN',
'_': int(time.time()),
}
response = session.get(url, params=params)
data = response.content.decode('utf-8')
# print(data) >>> window.QRLogin.code = 200; window.QRLogin.uuid = "oZwt_bFfRg==";
regx = r'window.QRLogin.code = (\d+); window.QRLogin.uuid = "(\S+?)"'
pm = re.search(regx, data)
code = pm.group(1)
uuid = pm.group(2)
if code == '200':
return True
return False
def showQRImage():
global tip
url = 'https://login.weixin.qq.com/qrcode/' + uuid
params = {
't': 'webwx',
'_': int(time.time()),
}
response = session.get(url, params=params)
tip = 1
with open(QRImgPath, 'wb') as f:
f.write(response.content)
f.close()
if sys.platform.find('darwin') >= 0:
subprocess.call(['open', QRImgPath])
elif sys.platform.find('linux') >= 0:
subprocess.call(['xdg-open', QRImgPath])
else:
os.startfile(QRImgPath)
print('请使用微信扫描二维码以登录')
def waitForLogin():
global tip, base_uri, redirect_uri
url = 'https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login?tip=%s&uuid=%s&_=%s' % (
tip, uuid, int(time.time()))
response = session.get(url)
data = response.content.decode('utf-8')
# print(data)
# window.code=500;
regx = r'window.code=(\d+);'
pm = re.search(regx, data)
code = pm.group(1)
if code == '201': # 已扫描
print('成功扫描,请在手机上点击确认以登录')
tip = 0
elif code == '200': # 已登录
print('正在登录...')
regx = r'window.redirect_uri="(\S+?)";'
pm = re.search(regx, data)
redirect_uri = pm.group(1) + '&fun=new'
base_uri = redirect_uri[:redirect_uri.rfind('/')]
# closeQRImage
if sys.platform.find('darwin') >= 0: # for OSX with Preview
os.system("osascript -e 'quit app \"Preview\"'")
elif code == '408': # 超时
pass
# elif code == '400' or code == '500':
return code
def login():
global skey, wxsid, wxuin, pass_ticket, BaseRequest
response = session.get(redirect_uri)
data = response.content.decode('utf-8')
# print(data)
'''
<error>
<ret>0</ret>
<message>OK</message>
<skey>xxx</skey>
<wxsid>xxx</wxsid>
<wxuin>xxx</wxuin>
<pass_ticket>xxx</pass_ticket>
<isgrayscale>1</isgrayscale>
</error>
'''
xml.dom
doc = xml.dom.minidom.parseString(data)
root = doc.documentElement
for node in root.childNodes:
if node.nodeName == 'skey':
skey = node.childNodes[0].data
elif node.nodeName == 'wxsid':
wxsid = node.childNodes[0].data
elif node.nodeName == 'wxuin':
wxuin = node.childNodes[0].data
elif node.nodeName == 'pass_ticket':
pass_ticket = node.childNodes[0].data
# print('skey: %s, wxsid: %s, wxuin: %s, pass_ticket: %s' % (skey, wxsid,
# wxuin, pass_ticket))
if not all((skey, wxsid, wxuin, pass_ticket)):
return False
BaseRequest = {
'Uin': int(wxuin),
'Sid': wxsid,
'Skey': skey,
'DeviceID': deviceId,
}
return True
def webwxinit():
url = base_uri + \
'/webwxinit?pass_ticket=%s&skey=%s&r=%s' % (
pass_ticket, skey, int(time.time()))
params = {
'BaseRequest': BaseRequest
}
h = headers
h['ContentType'] = 'application/json; charset=UTF-8'
response = session.post(url, data=json.dumps(params), headers=h)
data = response.content.decode('utf-8')
#print(data)
global ContactList, My, SyncKey
dic = json.loads(data)
ContactList = dic['ContactList']
My = dic['User']
SyncKeyList = []
for item in dic['SyncKey']['List']:
SyncKeyList.append('%s_%s' % (item['Key'], item['Val']))
SyncKey = '|'.join(SyncKeyList)
ErrMsg = dic['BaseResponse']['ErrMsg']
Ret = dic['BaseResponse']['Ret']
if Ret != 0:
return False
return True
def webwxgetcontact():
url = base_uri + \
'/webwxgetcontact?pass_ticket=%s&skey=%s&r=%s' % (
pass_ticket, skey, int(time.time()))
h = headers
h['ContentType'] = 'application/json; charset=UTF-8'
response = session.get(url, headers=h)
data = response.content.decode('utf-8')
# print(data)
dic = json.loads(data)
MemberList = dic['MemberList']
# 倒序遍历,不然删除的时候出问题..
SpecialUsers = ["newsapp", "fmessage", "filehelper", "weibo", "qqmail", "tmessage", "qmessage", "qqsync", "floatbottle", "lbsapp", "shakeapp", "medianote", "qqfriend", "readerapp", "blogapp", "facebookapp", "masssendapp",
"meishiapp", "feedsapp", "voip", "blogappweixin", "weixin", "brandsessionholder", "weixinreminder", "wxid_novlwrv3lqwv11", "gh_22b87fa7cb3c", "officialaccounts", "notification_messages", "wxitil", "userexperience_alarm"]
for i in range(len(MemberList) - 1, -1, -1):
Member = MemberList[i]
if Member['VerifyFlag'] & 8 != 0: # 公众号/服务号
MemberList.remove(Member)
elif Member['UserName'] in SpecialUsers: # 特殊账号
MemberList.remove(Member)
elif Member['UserName'].find('@@') != -1: # 群聊
MemberList.remove(Member)
elif Member['UserName'] == My['UserName']: # 自己
MemberList.remove(Member)
return MemberList
def main():
if not getUUID():
print('获取uuid失败')
return
showQRImage()
time.sleep(1)
while waitForLogin() != '200':
pass
os.remove(QRImgPath)
if not login():
print('登录失败')
return
#登录完成, 下面查询好友
if not webwxinit():
print('初始化失败')
return
MemberList = webwxgetcontact()
print('通讯录共%s位好友' % len(MemberList))
for x in MemberList :
sex = '未知' if x['Sex'] == 0 else '男' if x['Sex'] == 1 else '女'
print('昵称:%s, 性别:%s, 备注:%s, 签名:%s' % (x['NickName'], sex, x['RemarkName'], x['Signature']))
if __name__ == '__main__':
print('开始')
main()