这篇文章是《图解算法》一书的摘抄总结。
原书标题是《Grokking Algorithms》,grok是中文“意会”的意思,韦伯斯特的解释是“to understand profoundly and intuitively ”,英语的原意是强调深入直观地理解。有意思的是,今年的最后一天,2017年12月31日,还会出版另一本Grokking书,《Grokking Deep Learning》(图解深度学习),哈哈,到时候也看看。
第1章 算法简介
二分查找
一般而言,对于包含n 个元素的列表,用二分查找最多需要log2(n) 步,而简单查找最多需要n 步。
二分查找算法如下:
def binary_search(list, item):
low = 0 (以下2行)low和high用于跟踪要在其中查找的列表部分
high = len(list)—1
while low <= high: ←-------------只要范围没有缩小到只包含一个元素,
mid = (low + high) / 2 ←-------------就检查中间的元素
guess = list[mid]
if guess == item: ←-------------找到了元素
return mid
if guess > item: ←-------------猜的数字大了
high = mid - 1
else: ←---------------------------猜的数字小了
low = mid + 1
return None ←--------------------没有指定的元素
my_list = [1, 3, 5, 7, 9] ←------------来测试一下!
print binary_search(my_list, 3) # => 1 ←--------------------别忘了索引从0开始,第二个位置的索引为1
print binary_search(my_list, -1) # => None ←--------------------在Python中,None表示空,它意味着没有找到指定的元素
习题
1.1 假设有一个包含128个名字的有序列表,你要使用二分查找在其中查找一个名字,请 问最多需要几步才能找到?
1.2 上面列表的长度翻倍后,最多需要几步?
最多需要猜测的次数与列表长度相同,这被称为线性时间 (linear time)。二分查找的运行时间为对数时间 (或log时间)。
大O表示法
大O表示法指出了最糟情况下的运行时间。线性算法的运行时间为O (n ),对数算法的运行时间为O (log n )。
常见的大O运行时间(由快到慢):
- O (log n ),也叫对数时间 ,这样的算法包括二分查找。
- O (n ),也叫线性时间 ,这样的算法包括简单查找。
- O (n * log n ),这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。
- O (n 2 ),这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。
- O (n !),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。
一些总结:
- 算法的速度指的并非时间,而是操作数的增速。
- 谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
- 算法的运行时间用大O表示法表示。
- O (log n )比O (n )快,当需要搜索的元素越多时,前者比后者快得越多。
练习
使用大O表示法给出下述各种情形的运行时间。
1.3 在电话簿中根据名字查找电话号码。
1.4 在电话簿中根据电话号码找人。(提示:你必须查找整个电话簿。)
1.5 阅读电话簿中每个人的电话号码。
1.6 阅读电话簿中姓名以A打头的人的电话号码。这个问题比较棘手,它涉及第4章的概念。答案可能让你感到惊讶!
第1章总结:
- 二分查找的速度比简单查找快得多。
- O (log n )比O (n )快。需要搜索的元素越多,前者比后者就快得越多。
- 算法运行时间并不以秒为单位。
- 算法运行时间是从其增速的角度度量的。
- 算法运行时间用大O表示法表示。
第2章 选择排序
数组和链表
数组的元素存储在内存中相连的位置。
链表中的元素可存储在内存的任何地方。
链表的优势在插入元素方面,但进行跳跃读取元素效率低,数组的优势在于读取效率高。
练习
2.1 假设你要编写一个记账的应用程序。
你每天都将所有的支出记录下来,并在月底统计支出,算算当月花了多少钱。因此,你执行的插入操作很多,但读取操作很少。该使用数组还是链表呢?
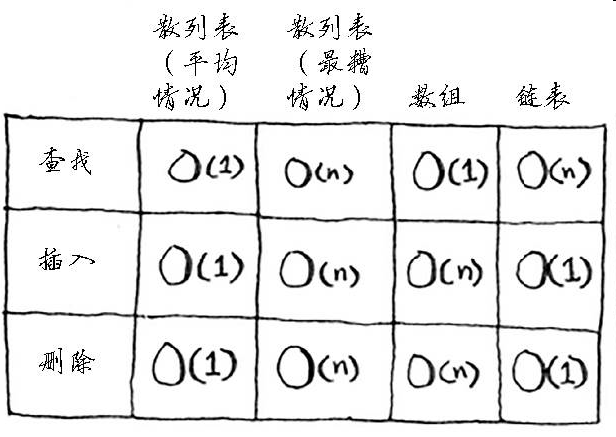
下面是常见数组和链表操作的运行时间。
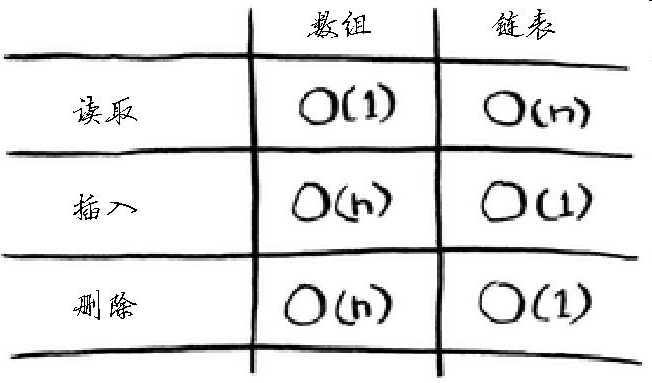
有两种访问方式:随机访问 和顺序访问 。顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。随机访问意味着可直接跳到第十个元素。本书经常说数组的读取速度更快,这是因为它们支持随机访问。很多情况都要求能够随机访问,因此数组用得很多。
练习
2.2 假设你要为饭店创建一个接受顾客点菜单的应用程序。这个应用程序存储一系列点菜单。服务员添加点菜单,而厨师取出点菜单并制作菜肴。这是一个点菜单队列:服务员在队尾添加点菜单,厨师取出队列开头的点菜单并制作菜肴。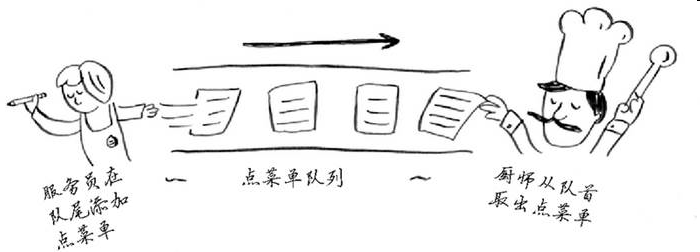
你使用数组还是链表来实现这个队列呢?(提示:链表擅长插入和删除,而数组擅长随机访问。在这个应用程序中,你要执行的是哪些操作呢?)
2.3 我们来做一个思考实验。假设Facebook记录一系列用户名,每当有用户试图登录Facebook时,都查找其用户名,如果找到就允许用户登录。由于经常有用户登录Facebook,因此需要执行大量的用户名查找操作。假设Facebook使用二分查找算法,而这种算法要求能够随机访问——立即获取中间的用户名。考虑到这一点,应使用数组还是链表来存储用户名呢?
2.4 经常有用户在Facebook注册。假设你已决定使用数组来存储用户名,在插入方面数组有何缺点呢?具体地说,在数组中添加新用户将出现什么情况?
2.5 实际上,Facebook存储用户信息时使用的既不是数组也不是链表。假设Facebook使用的是一种混合数据:链表数组。这个数组包含26个元素,每个元素都指向一个链表。例如,该数组的第一个元素指向的链表包含所有以A打头的用户名,第二个元素指向的链表包含所有以B打头的用户名,以此类推。
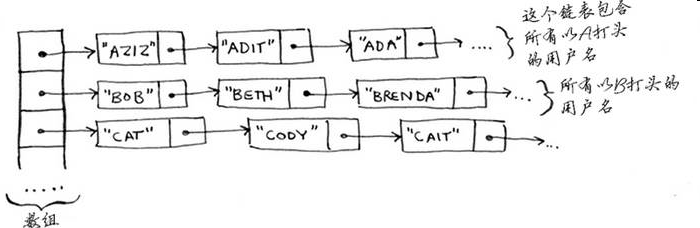
假设Adit B在Facebook注册,而你需要将其加入前述数据结构中。因此,你访问数组的第一个元素,再访问该元素指向的链表,并将Adit B添加到这个链表末尾。现在假设你要查找Zakhir H。因此你访问第26个元素,再在它指向的链表(该链表包含所有以z打头的用户名)中查找Zakhir H。
请问,相比于数组和链表,这种混合数据结构的查找和插入速度更慢还是更快?你不必给出大O运行时间,只需指出这种新数据结构的查找和插入速度更快还是更慢。
选择排序
将数组元素按从小到大的顺序排列。先编写一个用于找出数组中最小元素的函数。
def findSmallest(arr):
smallest = arr[0] ←------存储最小的值
smallest_index = 0 ←------存储最小元素的索引
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
使用这个函数来编写选择排序算法。
def selectionSort(arr): ←------对数组进行排序
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr) ←------找出数组中最小的元素,并将其加入到新数组中
newArr.append(arr.pop(smallest))
return newArr
print selectionSort([5, 3, 6, 2, 10])
第2章总结:
- 计算机内存犹如一大堆抽屉。
- 需要存储多个元素时,可使用数组或链表。
- 数组的元素都在一起。
- 链表的元素是分开的,其中每个元素都存储了下一个元素的地址。
- 数组的读取速度很快。
- 链表的插入和删除速度很快。
- 在同一个数组中,所有元素的类型都必须相同(都为int、double等)。
第3章 递归
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件 (base case)和递归条件 (recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
def countdown(i):
print i
if i <= 0: ←------基线条件
return
else: ←------递归条件
countdown(i-1)
调用栈:调用另一个函数时,当前函数暂停并处于未完成状态。这个栈用于存储多个函数的变量,被称为调用栈 。
练习
3.1 根据下面的调用栈,你可获得哪些信息?
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择。
练习
3.2 假设你编写了一个递归函数,但不小心导致它没完没了地运行。正如你看到的,对于每次函数调用,计算机都将为其在栈中分配内存。递归函数没完没了地运行时,将给栈带来什么影响?
第3章总结:
- 递归指的是调用自己的函数。
- 每个递归函数都有两个条件:基线条件和递归条件。
- 栈有两种操作:压入和弹出。
- 所有函数调用都进入调用栈。
- 调用栈可能很长,这将占用大量的内存。
第4章 快速排序
分而治之D&C的工作原理:
(1) 找出简单的基线条件;
(2) 确定如何缩小问题的规模,使其符合基线条件。
练习
4.1 请编写前述sum 函数的代码。
4.2 编写一个递归函数来计算列表包含的元素数。
4.3 找出列表中最大的数字。
4.4 还记得第1章介绍的二分查找吗?它也是一种分而治之算法。你能找出二分查找算法的基线条件和递归条件吗?
快速排序
def quicksort(array):
if len(array) < 2:
return array ←------基线条件:为空或只包含一个元素的数组是“有序”的
else:
pivot = array[0] ←------递归条件
less = [i for i in array[1:] if i <= pivot] ←------由所有小于基准值的元素组成的子数组
greater = [i for i in array[1:] if i > pivot] ←------由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print quicksort([10, 5, 2, 3])
练习
使用大O表示法时,下面各种操作都需要多长时间?
4.5 打印数组中每个元素的值。
4.6 将数组中每个元素的值都乘以2。
4.7 只将数组中第一个元素的值乘以2。
4.8 根据数组包含的元素创建一个乘法表,即如果数组为[2, 3, 7, 8, 10],首先将每个元素 都乘以2,再将每个元素都乘以3,然后将每个元素都乘以7,以此类推。
第4章总结:
- D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或只包含一个元素的数组。
- 实现快速排序时,请随机地选择用作基准值的元素。快速排序的平均运行时间为O (n log n )。
- 大O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因所在。
- 比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,O (log n )的速度比O (n )快得多。
第5章 散列表
散列表适合用于:
- 仿真映射关系;
- 防止重复;
- 缓存/记住数据,以免服务器再通过处理来生成它们。
第5章总结:
- 你可以结合散列函数和数组来创建散列表。
- 冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。
- 散列表的查找、插入和删除速度都非常快。
- 散列表适合用于仿真映射关系。
- 一旦填装因子超过0.7,就该调整散列表的长度。
- 散列表可用于缓存数据(例如,在Web服务器上)。
- 散列表非常适合用于防止重复。
第6章 广度优先搜索
广度优先搜索的最终代码如下。
def search(name):
search_queue = deque()
search_queue += graph[name]
searched = [] ←------------------------------这个数组用于记录检查过的人
while search_queue:
person = search_queue.popleft()
if person not in searched: ←----------仅当这个人没检查过时才检查
if person_is_seller(person):
print person + " is a mango seller!"
return True
else:
search_queue += graph[person]
searched.append(person) ←------将这个人标记为检查过
return False
search("you")
第6章总结:
广度优先搜索指出是否有从A到B的路径。
如果有,广度优先搜索将找出最短路径。
面临类似于寻找最短路径的问题时,可尝试使用图来创建模型,再使用广度优先搜索来解决问题。
有向图中的边为箭头,箭头的方向指定了关系的方向。
无向图中的边不带箭头,其中的关系是双向的。
队列是先进先出(FIFO)的。
栈是后进先出(LIFO)的。
第7章 狄克斯特拉算法
要计算非加权图中的最短路径,可使用广度优先搜索 。要计算加权图中的最短路径,可使用狄克斯特拉算法 。
node = find_lowest_cost_node(costs) ←------在未处理的节点中找出开销最小的节点
while node is not None: ←------这个while循环在所有节点都被处理过后结束
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys(): ←------遍历当前节点的所有邻居
new_cost = cost + neighbors[n]
if costs[n] > new_cost: ←------如果经当前节点前往该邻居更近,
costs[n] = new_cost ←------就更新该邻居的开销
parents[n] = node ←------同时将该邻居的父节点设置为当前节点
processed.append(node) ←------将当前节点标记为处理过
node = find_lowest_cost_node(costs) ←------找出接下来要处理的节点,并循环
第7章总结:
广度优先搜索用于在非加权图中查找最短路径。
狄克斯特拉算法用于在加权图中查找最短路径。
仅当权重为正时狄克斯特拉算法才管用。
如果图中包含负权边,请使用贝尔曼-福德算法。
第8章 贪婪算法
贪婪算法寻找局部最优解,企图以这种方式获得全局最优解。
对于NP完全问题,还没有找到快速解决方案。
面临NP完全问题时,最佳的做法是使用近似算法。
贪婪算法易于实现、运行速度快,是不错的近似算法。