闲来无事,想看看拉勾上关于的Python的招聘信息
于是。。。爬下来呗
- 话不多说,直接开始
不对,首先还是说一下主要使用到的技术栈,这里我没有使用requests库,而是使用selenium爬的
- why ?
我喜欢呗~
- selenium爬虫原理
其实原理也没啥好说的,和平时爬虫的时候原理都是一样的,就是模拟浏览器上网呗
- 分析:
其实,拉勾网是非常好爬的,首先进入拉勾网(www.lagou.com),并搜索python 回车

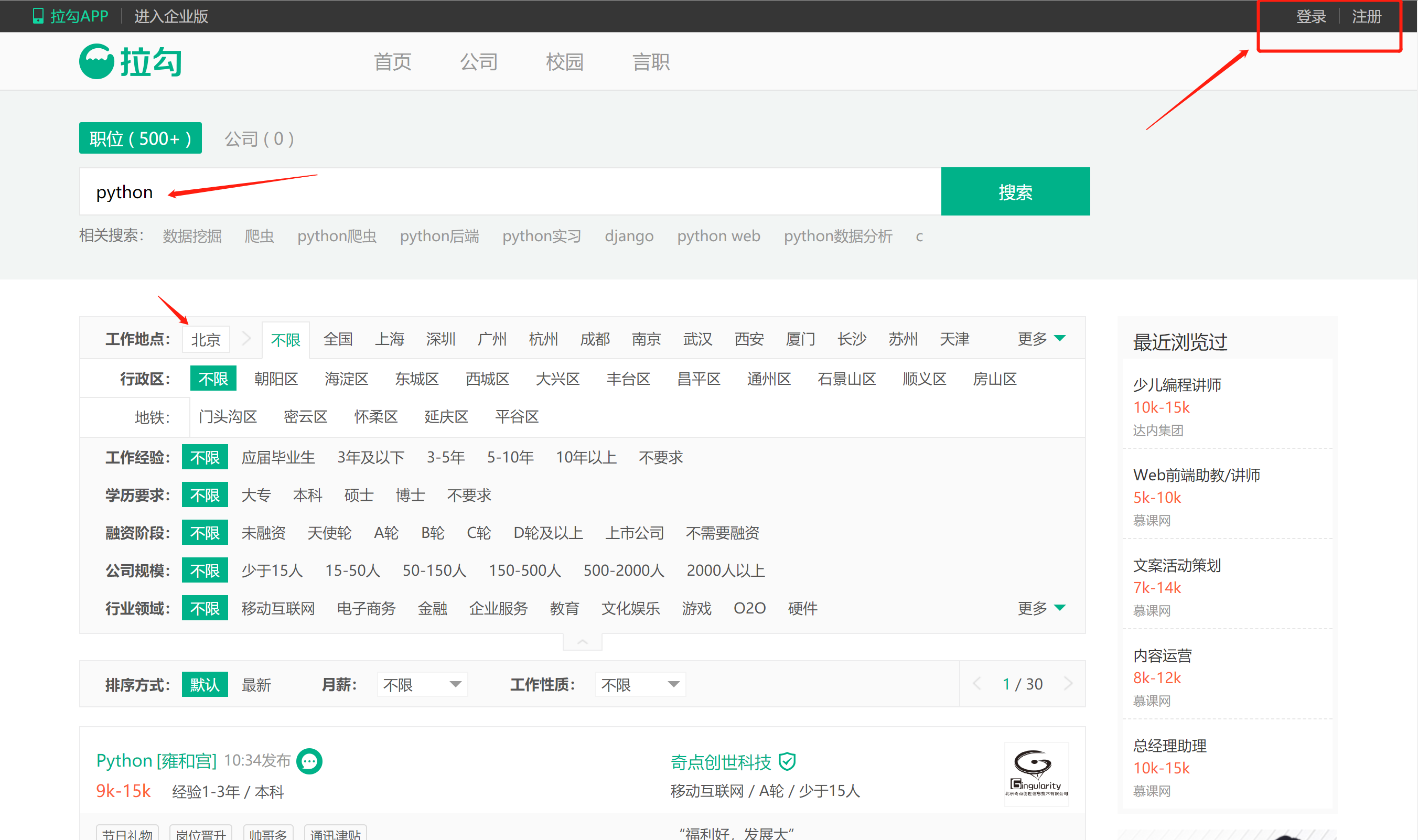
为什么说拉勾网好爬,原因之一在图中我已经标注出来了,就是不需要登录,原因之二请见下文
在chrome浏览器按f12,查看网页源码
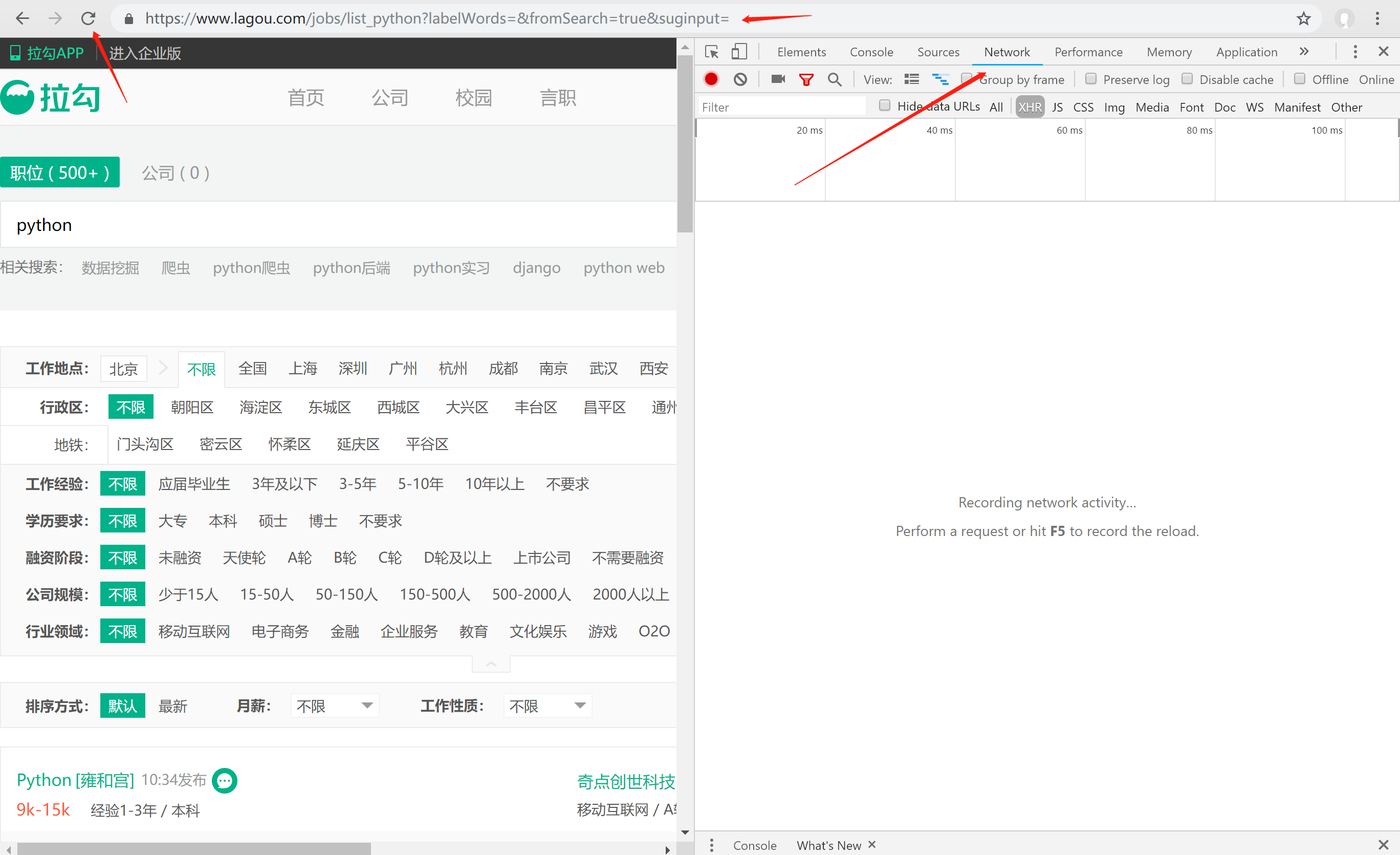
此时会发现,Network下什么都没有,那是因为没有请求,此时,需要再此刷新页面,就会有了
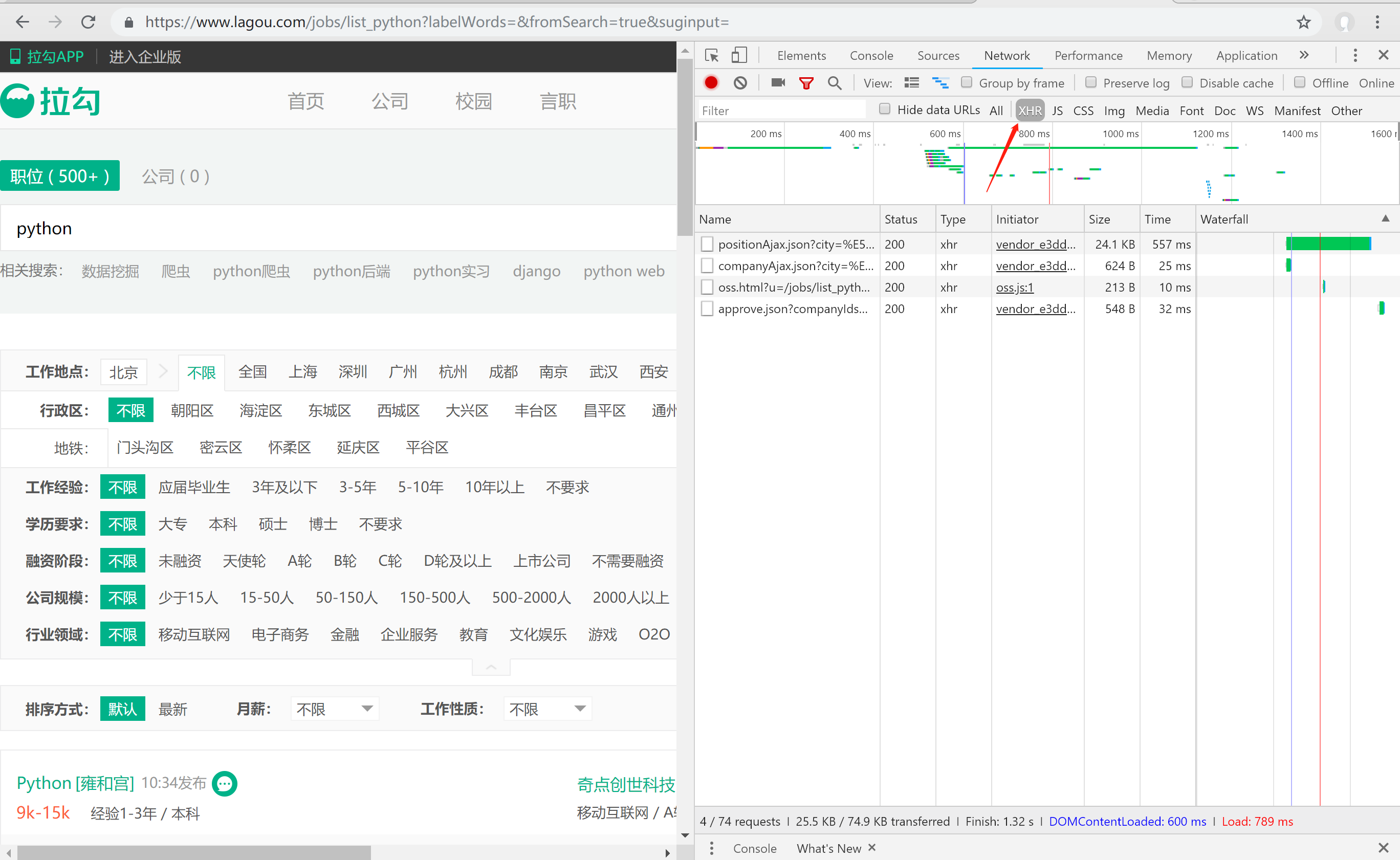
注意此时,我们选择箭头所指的位置,这里的数据是通过ajax发送过来的,这里就说一下,拉勾网容易爬的原因之二,因为所有的数据在ajax里都能找到,只需要爬去这里的json数据就行了,但是我没有这样做,因为不屑于(装)这么爬(B),开头就说了这次爬虫使用的是selenium,所以需要分析网页的html。因此,这里的数据不是重点,我们看网页
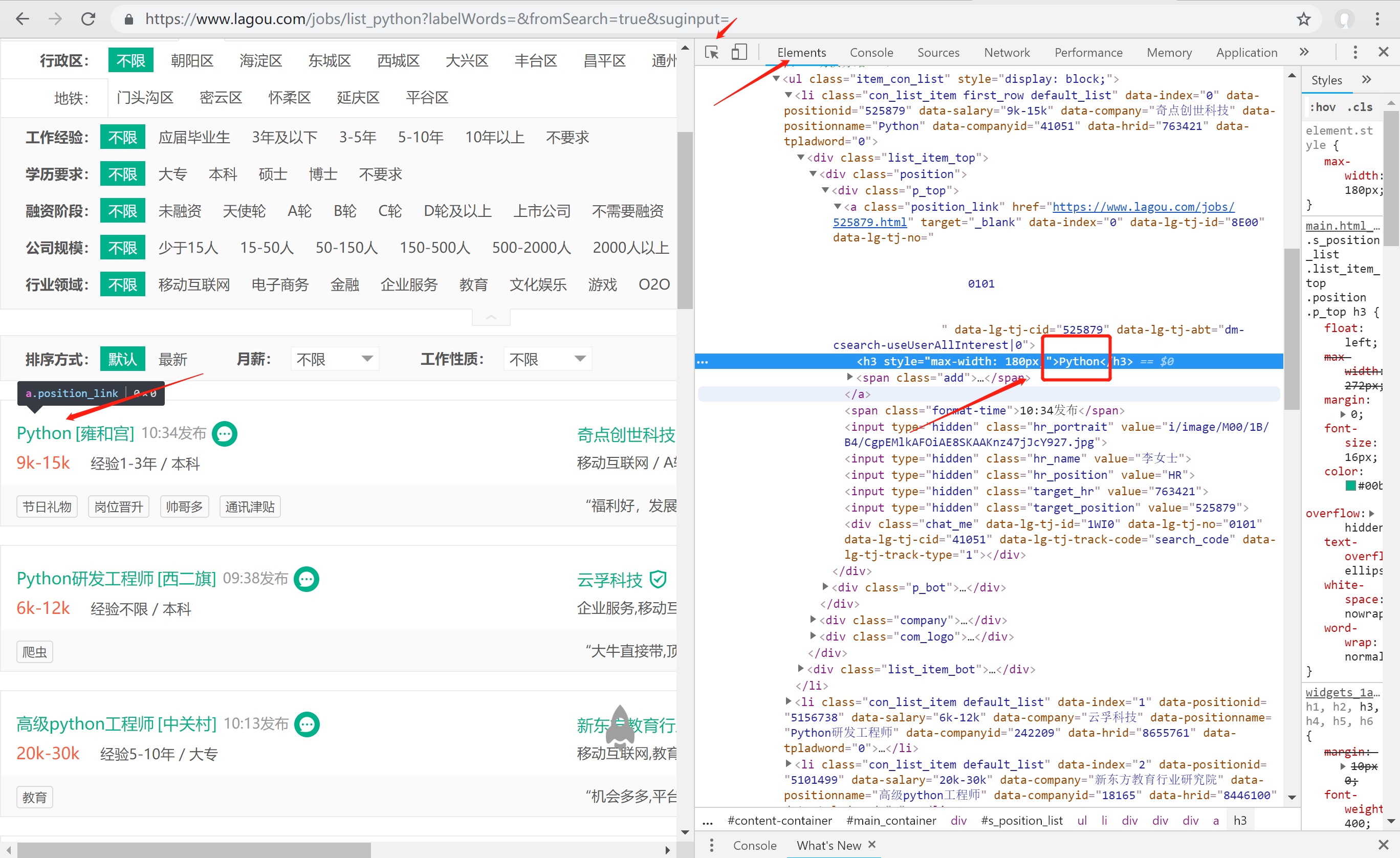
点击Elements,查看网页源码,再点击左上角的小箭头(我标注的红色小箭头)所指的按钮,再选中网页中的元素,即可快速定位到该元素所在的源码位置,到此时,其实我们已经找到想爬数据的所在位置了,在代码中使用selenium自带的xpath解析出来就可以了,接下来就是代码实现了
- 话不多说直接上源码:
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class Lagou(object):
def __init__(self, search_name):
self.start_url = "https://www.lagou.com/jobs/list_{}?px=default&city=%E5%8C%97%E4%BA%AC#filterBox"
self.search_name = search_name
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.driver = webdriver.Chrome(chrome_options=self.chrome_options)
self.content_header = ["positionName", "businessZones", "CreateTime", "companyShortName", "salary", "workYear"]
def get_content_list(self): # 提取数据
li_list = self.driver.find_elements_by_xpath('//li[contains(@class, "con_list_item")]')
content_list = []
for li in li_list:
item_list = []
item_list.append(li.find_element_by_tag_name("h3").text)
item_list.append(li.find_element_by_tag_name("em").text)
item_list.append(li.find_elements_by_xpath(".//span[@class='format-time']")[0].text)
item_list.append(li.find_elements_by_xpath(".//div[@class='company_name']")[0].text)
item_list.append(li.find_elements_by_xpath(".//span[@class='money']")[0].text)
item_list.append(li.find_elements_by_xpath(".//div[@class='li_b_l']")[0].text)
# print(item_list)
content_list.append(item_list)
# 下一页
next_url = self.driver.find_elements_by_xpath("//span[@class='pager_next ']")
next_url = next_url[0] if len(next_url) > 0 else None
return content_list, next_url
def save_content_list(self, content_list):
with open(self.search_name + "_data.csv", "a", encoding='utf-8') as f:
for content in content_list:
print(content)
for item in content:
if isinstance(item, str):
if ',' in item:
item.replace(",", "|")
f.write(item + ",")
f.write('\n')
def run(self):
# 发送请求
self.driver.get(self.start_url.format(self.search_name))
# 提取数据
content_list, next_url = self.get_content_list()
# 保存数据
self.save_content_list(content_list)
# 翻页
while next_url is not None:
next_url.click()
time.sleep(6)
content_list, next_url = self.get_content_list()
self.save_content_list(content_list)
if __name__ == '__main__':
lagou = Lagou("python")
lagou.run()
# 翻页
因为大多数时候,我们爬数据都是有目的的,在这里,我将数据转化成了csv格式保存的,只需要按需修改即可啦。
源码中,是将爬去下来的数据保存在文件中,这个文件被保存在当前的项目路径下,亦可按需修改
另外,我在最后又将源码进行修改,通过分析网页的url,发现搜索关键词可以在url中修改,因此这里使用了format将其扣出,只需要在实例化对象的时候,传入想搜索的关键词即可爬取到相关的职位
写在最后:
通过这次爬虫,虽然很慢。但是不得不承认,selenium更像是在模拟人真实的操作浏览器查看网页,因此此种方法不易被反爬虫发现,但是是真的慢(用requests爬去json数据,450条同样的数据大概只需要30秒,而我用这种方案足足花了5分钟)
另外,selenium还有很多其他玩法,感兴趣的朋友,不妨开发脑洞,玩一下
好吧,暂时就说这么多,有空再聊,peace~
微信公众号:TechBoard
个人博客:www.limiao.tech
