工作队列(work queue)是另外一种将工作推后执行的形式.他和其他形式都不相同.工作队列可以把工作推后,交由一个内核线程去执行,这个下半部分总是会在进程上下文中去执行.这样,通过工作队列执行的代码能占尽进程上下文的所有优势.最重要的是工作队列能允许重新调度甚至是休眠.
通常,在工作队列和软中断/tasklet中做出选择非常容易.如果推后执行的任务需要睡眠,那么就选择工作队列,如果不需要睡眠,就选择软中断或者是tasklet.实际上,工作队列可以使用内核线程特换,但是使用内核线程可能会出现一些问题,所以尽量使用工作队列.
如果需要一个可以重新调度的实体来执行你的下半部处理,你应该使用工作队列,他是唯一能在进程上下文中运行的下半部实现机制,也只有他才可以睡眠.如果不需要用一个内核线程来推后执行工作,那么就考虑使用tasklet.
(一):工作队列的实现
工作队列子系统是一个用于创建内核线程的接口.通过他创建的进程负责执行由内核其他部分排到队列里的任务.他创建的这些内核线程称为工作者线程.工作队队列可以让你的驱动程序创建一个专门的工作者线程来处理需要推后的工作.不过,工作队列子系统提供了一个缺省的工作者线程来处理这些工作.因此,工作队列最基本的表现形式,就转变成了一个把需要推后执行的任务交给特定的通用线程的这样一种接口.
缺省的工作者线程叫做events/n,这里n是处理器编号,每一个处理器对应一个线程.例如,单处理器的系统只有events/0这样一个线程,而双处理器系统就会多一个events/1线程.缺省的工作者线程会从多个地方得到被推后的工作.许多内核驱动程序都把下半部交给缺省的工作者线程去做.除非一个驱动程序或者是子系统必须建立一个属于他自己的内核线程,否则最好使用缺省线程.
1:表示线程的数据结构
工作者线程使用workqueue_struct结构表示:
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*
* 外部可见的工作队列抽象是每个CPU工作队列组成的数组
*/
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
该结构内部是一个由cpu_workqueue_struct结构组成的数组,它定义在kernel/workqueue.c中,数组中的每一项对应系统中的每一个处理器.由于系统中每个处理器对应一个工作者线程,所以对于给定的某台计算机来说,就是每个处理器,每个工作者线程对应一个这样的cpu_workqueue_struct结构体.cpu_qorkqueue_struct是kernel/qorkqueue.c中的核心数据结构.
/*
* The per-CPU workqueue (if single thread, we always use the first
* possible cpu).
*/
struct cpu_workqueue_struct {
spinlock_t lock; //锁保护这种结构
struct list_head worklist; //工作列表
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq; //关联工作队列结构
struct task_struct *thread; //关联线程
} ____cacheline_aligned;
注意,每个工作者线程类型关联一个自己的workqueue_struct.在该结构体里面,给每个线程分配一个cpu+qorkqueue_struct,因而也就是给每个处理器分配一个.因为每个处理器都有一个该类型的工作者线程.
2:表示工作的数据结构
所有的工作者线程都是用普通的内核线程实现的,他们都要执行worker_thread()函数.在他执行完以后,这个函数执行一个死循环并开始休眠.当有工作被插入到队列里面的时候,线程就会被唤醒,以便执行这些操作.当没有剩余的操作的时候,他又会继续休眠.
工作用linux/workqueue.h中定义的work_struct结构体表示:
struct work_struct {
atomic_long_t data;
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_STATIC 1 /* static initializer (debugobjects) */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
这些结构体被连接成链表,在每个处理器上的每种类型的队列都对应这样一个链表.比如,每个处理器上用于执行被推后的工作的那个通用线程就有这样的一个链表.当一个工作者线程被唤醒的时候,他会执行他的链表上的所有工作,工作被执行完毕,他就将相应的work_struct对象从链表中移走.当链表上不在有对象的时候,他就会继续休眠.
我们看一下worker_thread的执行流程,如下:
static int worker_thread(void *__cwq)
{
struct cpu_workqueue_struct *cwq = __cwq;
DEFINE_WAIT(wait);
if (cwq->wq->freezeable)
set_freezable();
for (;;) {
prepare_to_wait(&cwq->more_work, &wait, TASK_INTERRUPTIBLE);
if (!freezing(current) &&
!kthread_should_stop() &&
list_empty(&cwq->worklist))
schedule();
finish_wait(&cwq->more_work, &wait);
try_to_freeze();
if (kthread_should_stop())
break;
run_workqueue(cwq);
}
return 0;
}
该函数在死循环中完成了以下功能:
1:线程将自己设置为休眠状态(state被设成TASK_INTERRUPTIBLE),并把自己加入到等待队列中
2:如果工作链是空的,则线程调用schedule()函数进入休眠状态
3:如果链表中有对象,线程不会睡眠.相反,他将自己设置成
TAKS_RUNNING,脱离等待队列.
4:如果链表非空,调用run_workqueue()函数执行被推后的工作.
下一步,由run_workqueu()函数来完成推后执行的工作:
static void run_workqueue(struct cpu_workqueue_struct *cwq)
{
spin_lock_irq(&cwq->lock);
while (!list_empty(&cwq->worklist)) {
struct work_struct *work = list_entry(cwq->worklist.next,
struct work_struct, entry);
work_func_t f = work->func;
#ifdef CONFIG_LOCKDEP
/*
* It is permissible to free the struct work_struct
* from inside the function that is called from it,
* this we need to take into account for lockdep too.
* To avoid bogus "held lock freed" warnings as well
* as problems when looking into work->lockdep_map,
* make a copy and use that here.
*/
struct lockdep_map lockdep_map = work->lockdep_map;
#endif
trace_workqueue_execution(cwq->thread, work);
debug_work_deactivate(work);
cwq->current_work = work;
list_del_init(cwq->worklist.next);
spin_unlock_irq(&cwq->lock);
BUG_ON(get_wq_data(work) != cwq);
work_clear_pending(work);
lock_map_acquire(&cwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
f(work);
lock_map_release(&lockdep_map);
lock_map_release(&cwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
printk(KERN_ERR "BUG: workqueue leaked lock or atomic: "
"%s/0x%08x/%d\n",
current->comm, preempt_count(),
task_pid_nr(current));
printk(KERN_ERR " last function: ");
print_symbol("%s\n", (unsigned long)f);
debug_show_held_locks(current);
dump_stack();
}
spin_lock_irq(&cwq->lock);
cwq->current_work = NULL;
}
spin_unlock_irq(&cwq->lock);
}
该函数循环遍历连表上每个待处理的工作,执行链表每个节点上的workqueue_struct中的func成员函数:
1:当链表不为空的时候,选取下一个链表对象
2:获取我们希望执行的函数func及其参数data
3:把该节点从链表上解下来,将待处理标志位pending清零
4:调用函数
5:重复执行
3:工作队列实现工作的总结
下面一个图展示了这些数据结构之间的关系:
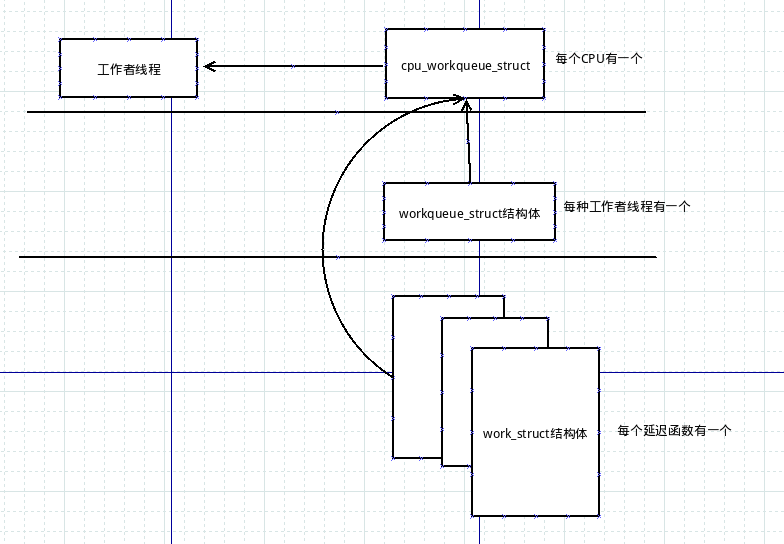
位于最高一层的是工作者线程.系统中允许有多种类型的工作者线程存在.对于指定的一个类型,系统上每个CPU上都有一个该类的工作者线程.内核中有些部分可以根据需要来创建工作者线程,而在默认情况下,内核只有event这一种类型的工作者线程.每一个工作者线程都由一个cpu_workqueue_struct结构体表示.而workqueue_struct结构体则表示给定类型的所有工作者线程.
例如,除系统默认的通用events工作者类型之外,我们自己加了一种falcon工作者类型,并且使用的是一个拥有四个处理器的计算机.那么,系统中现在有四个events类型的线程(因而也有四个cpu_workqueue_struct结构体)和另外四个falcon类型的线程(另外还有四个cpu_qorkqueue_struct结构体).同时,有一个对应的event类型的workqueue_struct和一个对应的falcon类型的workqueue_struct.
你的驱动程序创建这些需要推后执行的工作.他们用work_struct来表示.这个结构体中最重要的是一个指针,他指向一个函数,而正是该函数负责处理需要推后执行的具体任务.工作会被提交给某个具体的工作者线程.
默认情况下,现在大部分驱动程序都是使用的默认工作者线程.
(二):使用工作队列
首先我们先看一下如何使用缺省的工作队列.
1:创建推后的工作
首先需要做的就是实际创建一些需要推后完成的工作.可以通过DECLARE_WORK在编译的时候静态的创建该结构体:
DECLARE_WORK(name,void(*func)(void *),void *data);这样就会静态的创建一个名为name,处理函数为func,参数为data的work_struct结构体.同样,也可以在运行的时候通过指针创建一个工作.
INIT_WORK(struct work_struct *work,void(*func)(void *),void *data);
这会动态的初始化一个由work指向的工作,处理函数为func,参数为data.
2:工作队列处理函数
工作队列处理函数的原型为:
void work_handler(void *data);这个函数会由一个工作者线程执行,因此,函数会运行在进程上下文中.默认情况下,允许相应中断,并且不持有任何锁.如果需要,函数可以睡眠.需要注意的是,尽管操作处理函数运行在进程上下文中,但他不能访问用户空间,因为内核线程在用户空间没有相关的内存映射.通常在发生系统调用的时候,内核会代表用户空间的进程运行,此时才能访问用户空间.也只有此时他才会映射用户空间的内存.
在工作队列和内核其他部分之间使用锁机制就像在其他的进程上下文中使用锁机制一样方便.
3:对工作进行调度
现在工作已经被创建,我们可以调度他了.想要把给定工作的处理函数提交给缺省的events工作线程,只需调用:
schedule_work(&work);work马上就会被调度,一旦其所在的工作者线程被唤醒,他就会被执行.
如果想要他等待一定的时间之后再运行,那么就可以调度他在指定时间执行:
schedule_delayed_work(&work,delay);此时,&work指向的work_struct直到delayz指定的时钟节拍用完后才会执行.
4:刷新操作
排入队列的工作会在工作者线程下一次被唤醒的时候执行.有时,在继续下一步工作之前,你必须保证一些操作已经执行完毕了.这一点对于模块来说就很重要,在卸载之前,他就有可能需要调用下面的函数.而在内核的其他部分,为了防止竞争条件的出现,也可能需要确保不再有待处理的工作.
出于以上目的,内核准备了一个用于刷新指定工作队列的函数:
void flush_scheduled_work(void);这个函数可以取消任何与work_struct相关的挂起工作.
5: 创建新的工作队列
如果缺省的队列不能满足你的要求,你应该创建一个新的工作队列和与之相应的工作者线程.创建一个新的任务队列和与之相关的工作者线程,你只需要调用一个简单的函数:
struct workqueue_struct *create_workqueue(const char *name);name参数用于该内核线程的命名.比如缺省的events队列的创建就调用的是:
truct workqueue_struct *keventd_wq;
kevent_wq = create_workqueue("events");这样就会创建所有的工作者线程(系统的每个处理器都会有一个),并且做好所有开始处理工作之前的准备工作.
创建一个新的工作的时候,无需考虑工作队列的类型.在创建之后,可以调用下面列举的函数.这些函数于schedule_work()和schedule_delayed_work()相近,唯一的区别就在于他们针对给定的工作队列而不是缺省的events队列进行操作.
int queue_work(struct workqueue_struct *wq,struct work_struct *work)
int queue_delayed_work(struct workqueue_struct *wq,struct work_struct *work,unsigned long delay)最后,调用下面的函数刷新指定的工作队列.
flush_workqueue(struct workqueue_struct *wq);该函数与flush_scheduled_work()作用相同,只是他在返回前等待清空的是给定的队列.
5:下半部机制的选择
下面是三种下半部接口的比较:

对于一般的驱动开发来说,可以考虑推后执行的工作,需不需要休眠,如果需要休眠,则使用工作队列;如果不需要,最好使用tasklet.
6:在下半部之间加锁
使用tasklet的一个好处在于,他自己负责执行的序列化保障:两个相同类型的tasklet不允许同时执行,即使在不同的处理器上也不行.tasklet之间的同步(也就是两个不同类型的tasklet
共享同一数据的时候)需要正确使用锁机制.
如果一个进程上下文和一个下半部共享数据,在访问这些数据之前,你需要禁止下半部的处理并得到锁的使用权.做这些是为了本地和SMP的保护,并且防止死锁的出现.
如果一个中断上下文和一个下半部共享数据,在访问数据之前,你需要禁止中断并得到锁的使用权.所做的这些也是为了本地和SMP的保护并且防止死锁的出现.
所有在工作队列中被共享的数据也需要使用锁机制.
7:禁止下半部
一般单纯禁止下半部的处理是不够的.为了保证共享数据的安全,更常见的做法是,先得到一个锁然后再禁止下半部的处理.驱动程序中通常使用的都是这种方法.
如果需要禁止所有的下半部处理(就是所有的软中断和所有的tasklet),可以调用local_bh_disable()函数.允许下半部进行处理,可以调用local_bh_enable()函数.
函数通过preempt_count为每个进程维护一个计数器,当计数为0的时候,下半部才能被处理.因为下半部的处理已经被禁止,所以local_bh_enable()还需要检查所有
现存的待处理的下半部并执行他们.
这些函数并不能禁止工作队列的执行,因为工作队列是在进程上下文中运行的.不会涉及异步执行的问题,所以也就没有必要禁止他们执行.


