#为了方便后续管理,添加hadoop用户,并设置密码
adduser hadoop
passwd hadoop
#hadoop用户赋权(加sudo可以执行root的操作)
#给sudoers文件读写权
chmod u+w /etc/sudoers
#赋权
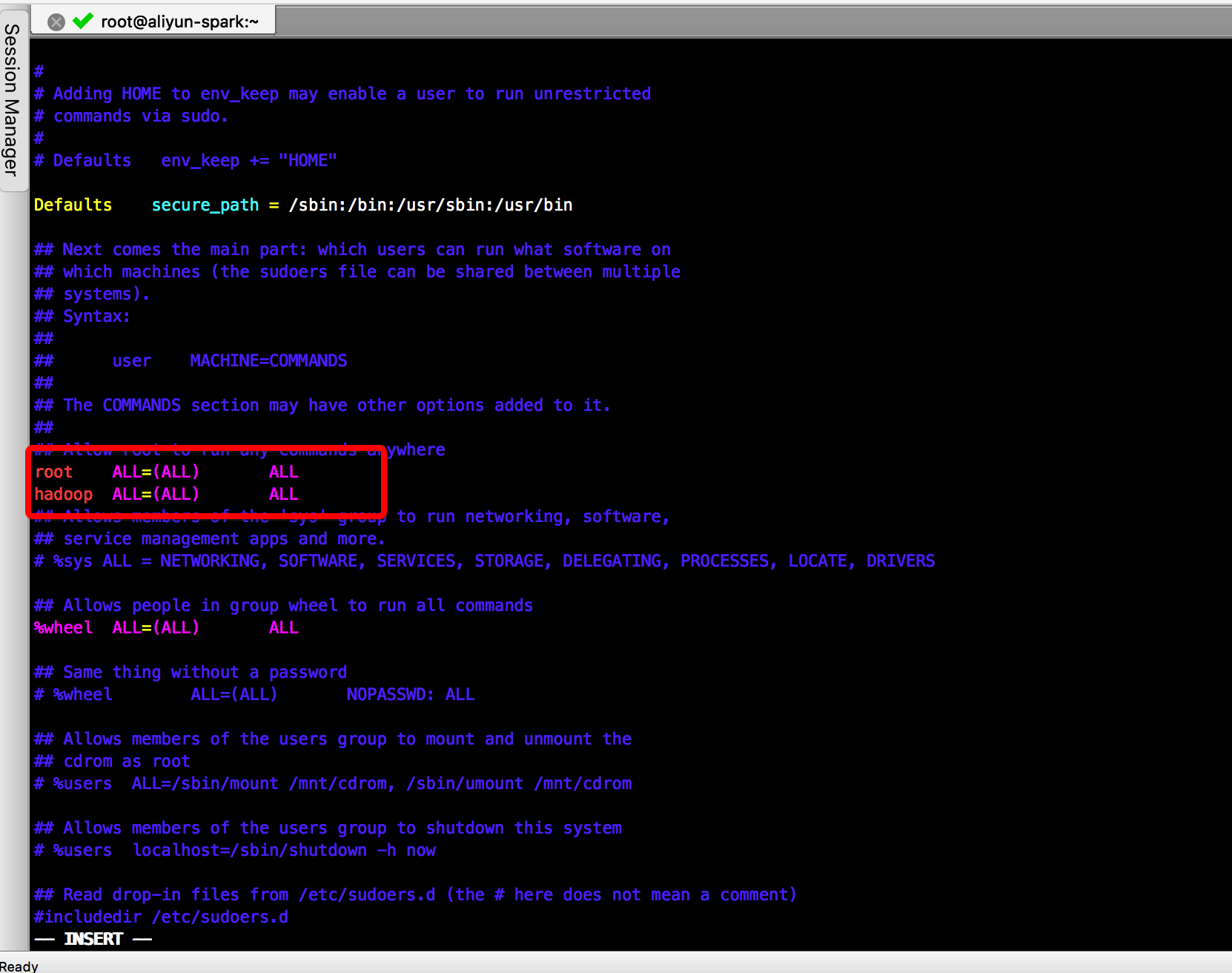
vim /etc/sudoers
#在root ALL = (ALL) ALL 下添加 hadoop ALL=(ALL) ALL 并保存
#为了安全撤销写权限
chmod u-w /etc/sudoers
用户赋权
hadoop依赖1.7+的jdk 如果是3.0+版本的hadoop依赖1.8+的idk,安装jdk
#安装jdk 这边我通过ftp把jdk1.8 tar包传到服务器
#进入相应目录解压
cd /usr/local/tools
tar -zxvf jdk-8u171-linux-x64.tar.gz
#配置环境变量
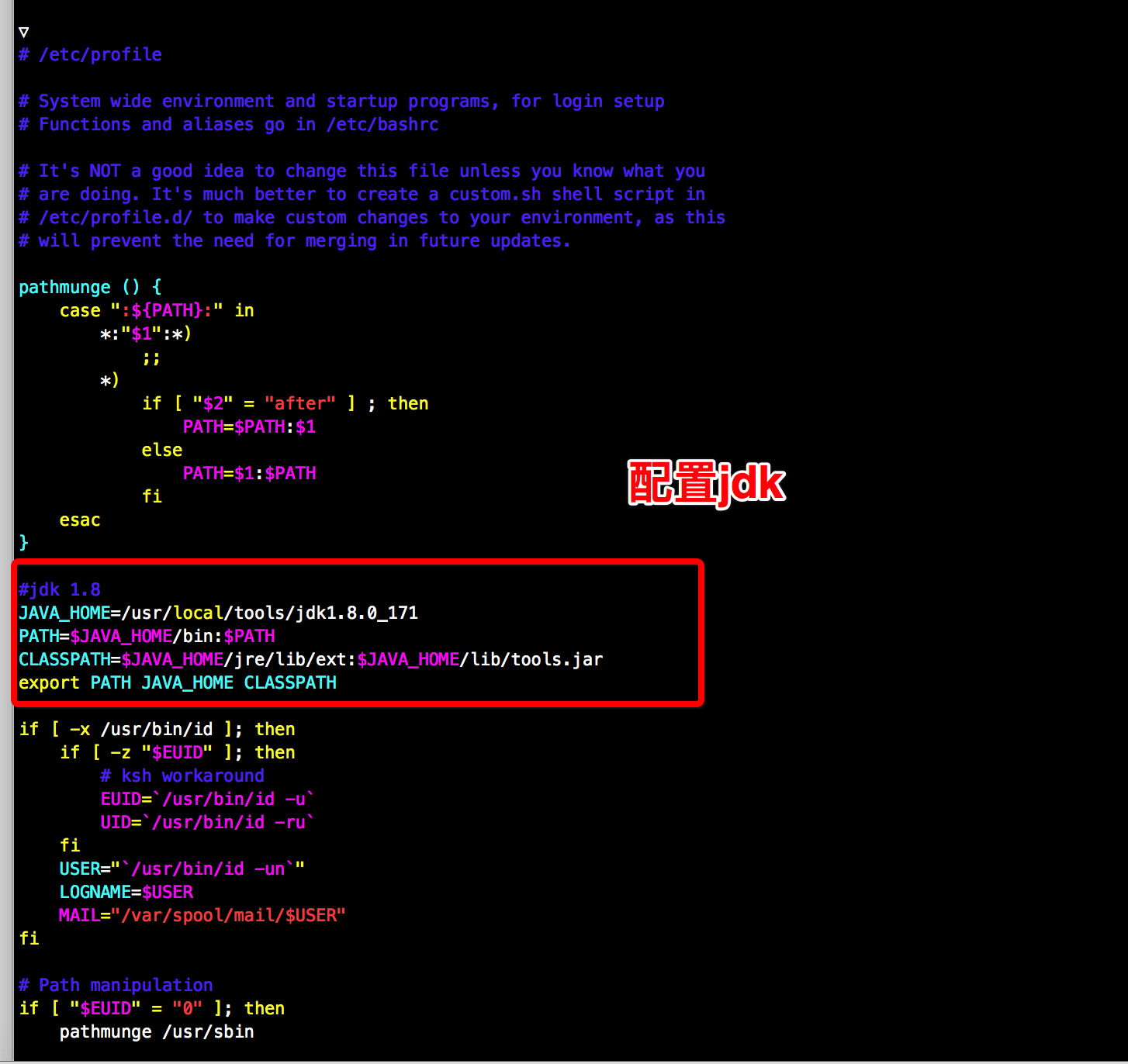
sudo vim /etc/profile
#文件中添加
JAVA_HOME=/usr/local/tools/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
#保存
source /etc/profile
#查看是否安装成功
java -version
配置jdk
配置SSH
#进入要安装的目录并获取
cd usr/local/tolls
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
#解压
tar xzvf hadoop-2.7.3.tar.gz
#ssh的配置和认证
#测试是否已经可以免密登录 首次的话需点击yes
ssh localhost
#不可以的话执行以下步骤
#查看是否已安装ssh 出现sshd字样说明已安装
ps -e | grep ssh
#如果没有安装
yum install openssh-server
#进入 用户的根目录 生成秘钥
ssh-keygen -t rsa #按三次回车
#传到authorized_keys中
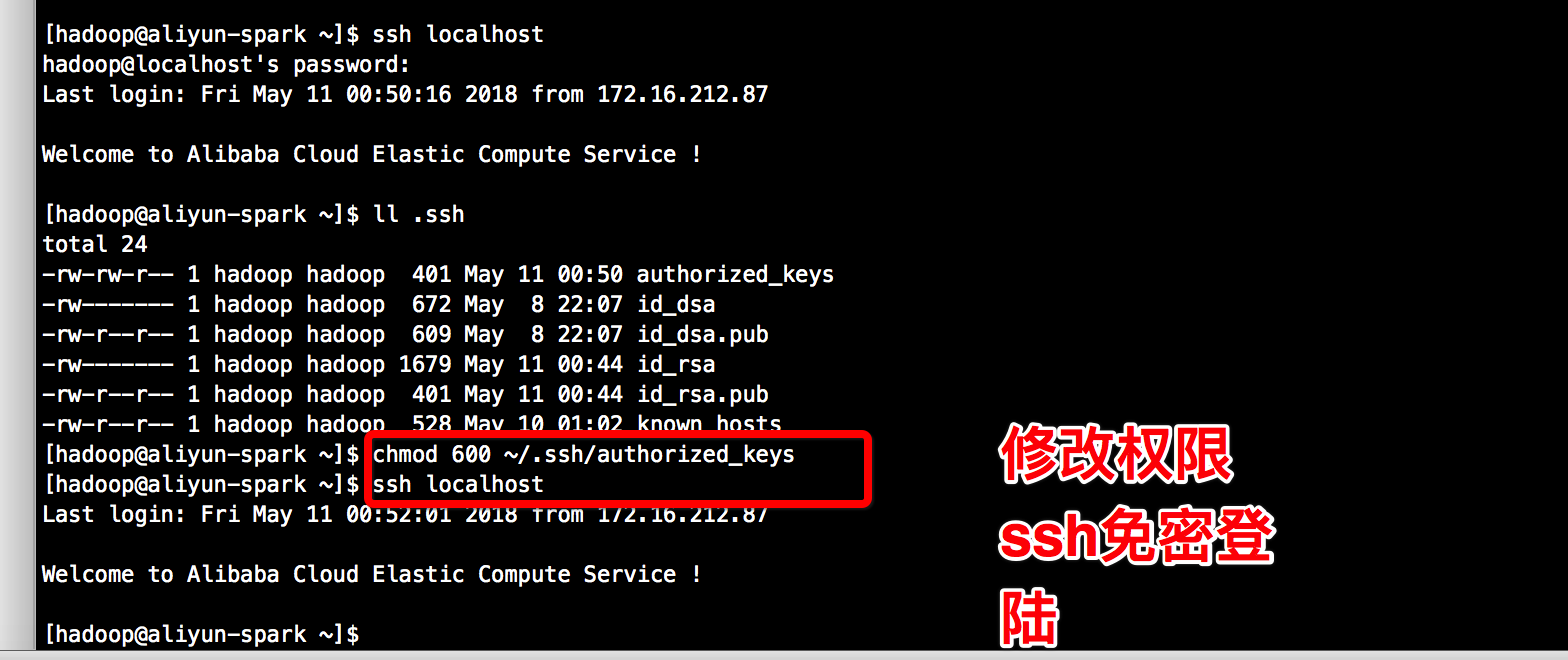
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#测试 如果还是不可以更改下权限$ chmod 600 ~/.ssh/authorized_keys
ssh localhost
#ssh localhost免密且出现Welcome字样说明ssh配置成功
免密登陆
配置haddop环境变量
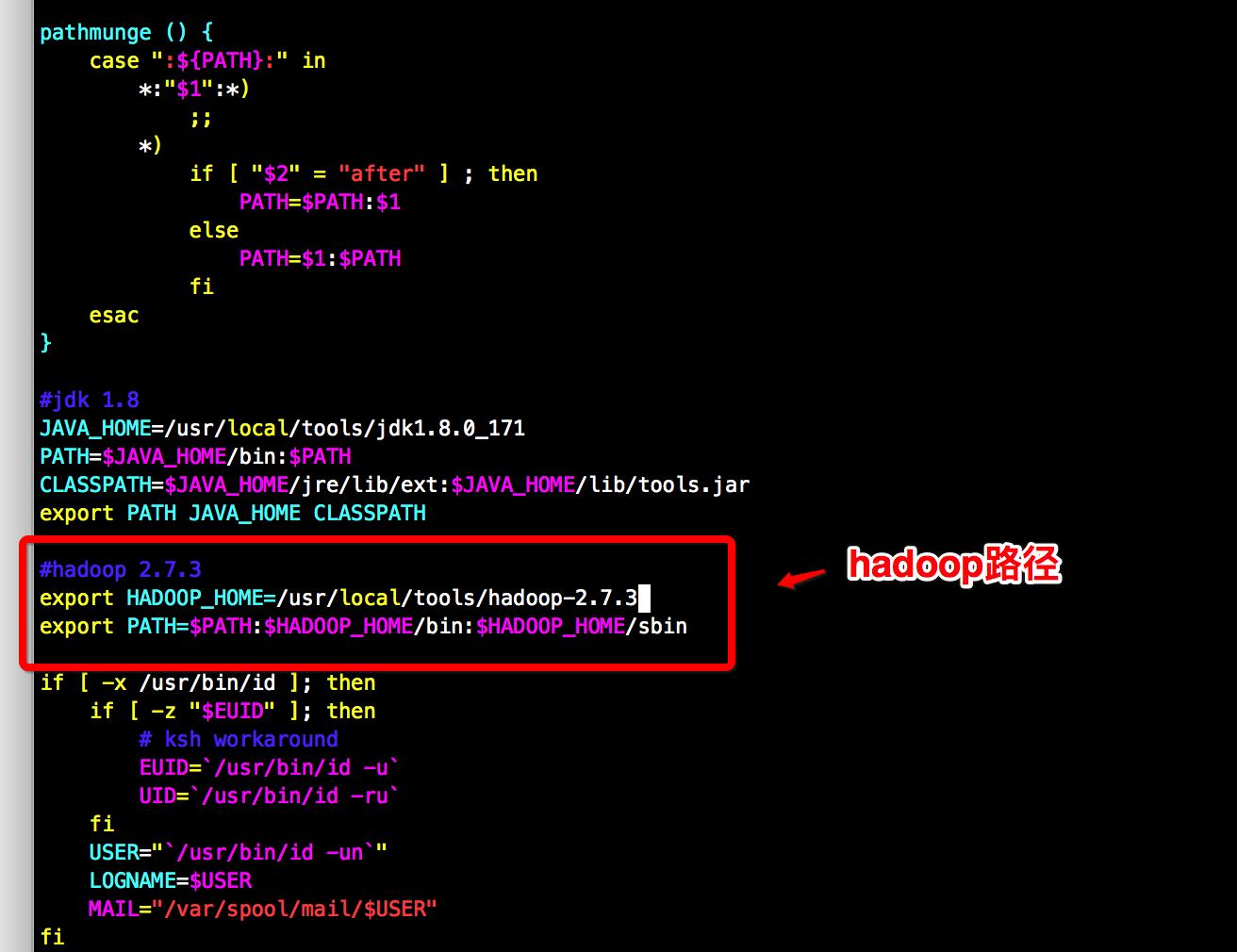
#类似配置jdk, sudo /etc/profile 添加 并 source /etc/profile 使其立即生效
export HADOOP_HOME=/usr/local/tools/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#检测是否安装配置成功
hadoop version
配置hadoop环境变量
配置hadoopjdk环境 修改hadoop-env.sh
#查看文件
sudo vim /usr/local/tools/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
#在最后一行添加
export JAVA_HOME=/usr/local/tools/jdk1.8.0_171
接下来需要配置四个配置文件(1,2为hdfs相关 3,4为yarn相关,注意备份防止配错)
1.core-site.xml
2.hdfs-site.xml
3.mapred-site.xml
4.yarn-site.xml

修改的配置文件
#进入hadoop-2.7.3/etc/hadoop目录
#配置core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
</configuration>
#配置hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
#配置mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
#配置yarn-site.xm
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
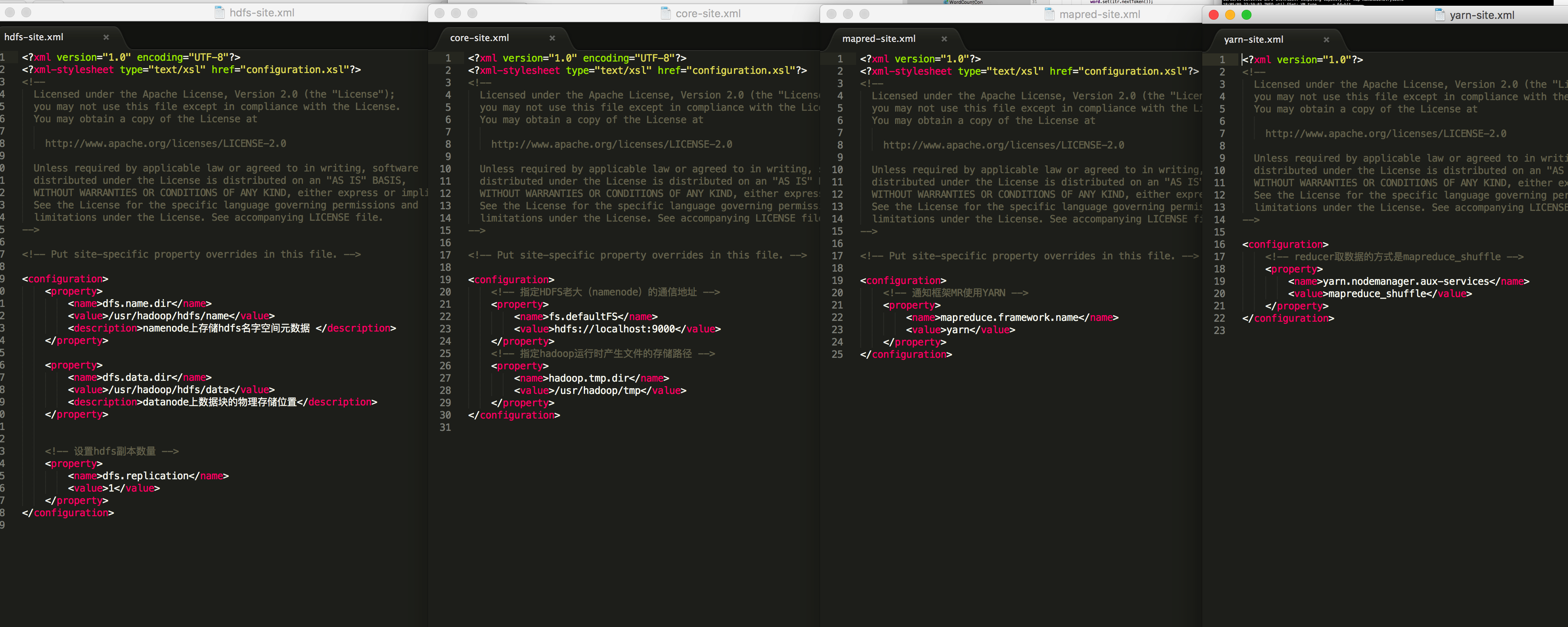
详细配置
启动hdfs
cd /usr/local/tools/hadoop-2.7.3
#第一次启动hdfs格式化 也可以进入bin目录直接执行hdfs namenode -format
#这边初始化的时候报了java.io.IOException: Cannot create directory /usr/hadoop/hdfs/name/current 的错,原因是hdfs设置存储元数据的地址没有写权限(可能因为不是root用户)
#解决方案 赋予写权 sudo chmod -R a+w /usr/hadoop/
./bin/hdfs namenode -format
#启动命令
#初次启动的时候报 /usr/local/tools/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-aliyun-spark.out: No such file or directory的错 这个时候mkdir logs 然后 sudo chmod -R a+w /usr/local/tools/hadoop-2.7.3/logs/ 即可
./sbin/start-dfs.sh
#停止
./sbin/stop-dfs.sh
#在网页打开 localhost:50070测试hdfs是否启动
#查看启动的相关进程
jps
出现这个界面说明hdfs启动成功
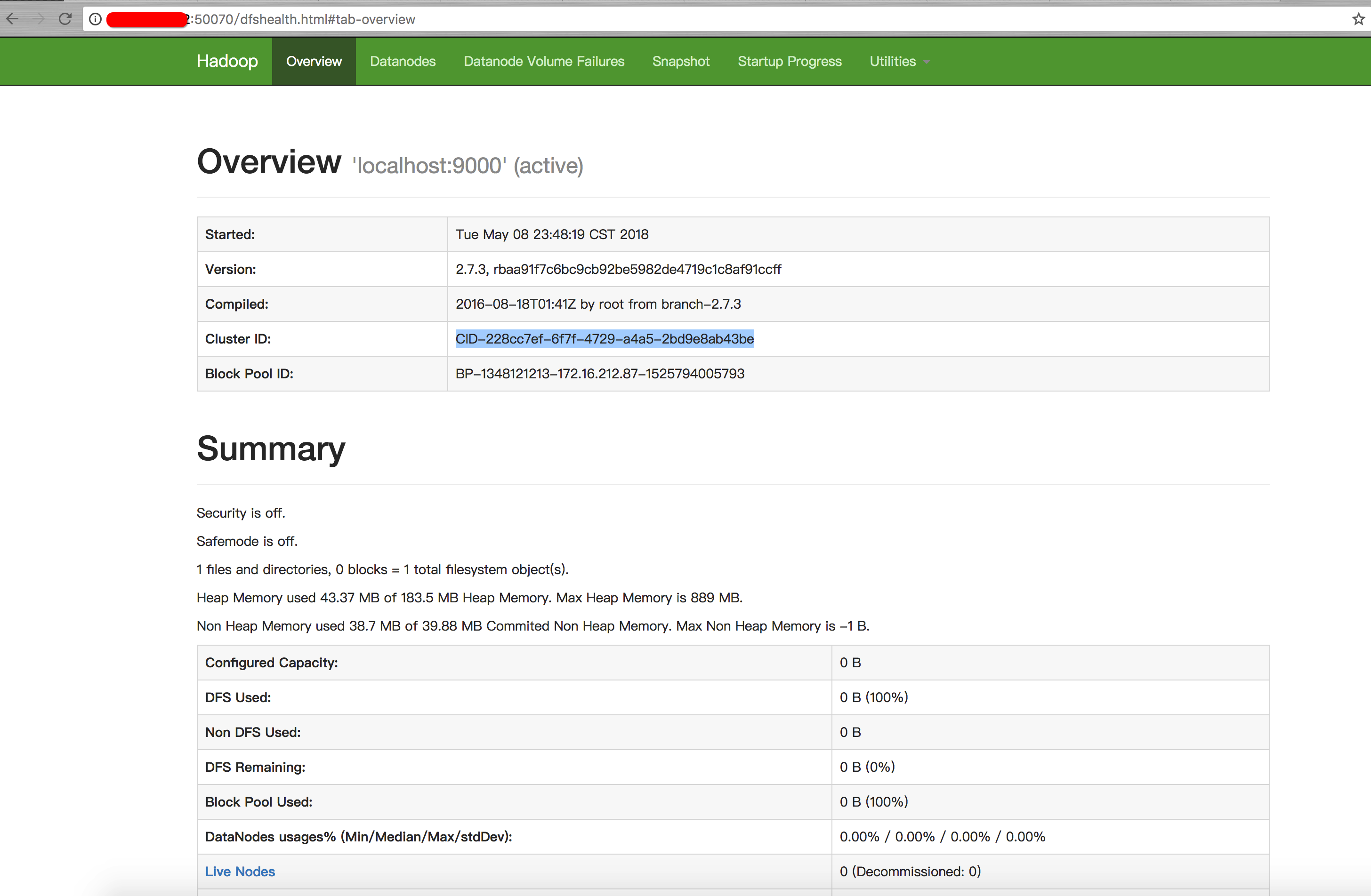
hdfs界面
启动yarn
cd /usr/local/tools/hadoop-2.7.3
#启动yarn
./sbin/start-yarn.sh
【
#启动如果报了hadoop@localhost's password: localhost: Permission denied, please try again.的错 解决方案
#先关闭yarn并修改当前用户密码
sudo passwd hadoop
#修改密码后 重新格式化namenode
./bin/hdfs namenode -format
#重启ssh之后再启动
sudo service ssh restart
】
#在网页打开 localhost:8088查看yarn是否启动
#关闭yarn
./sbin/stop-yarn.sh
出现这个界面说明yarn启动成功
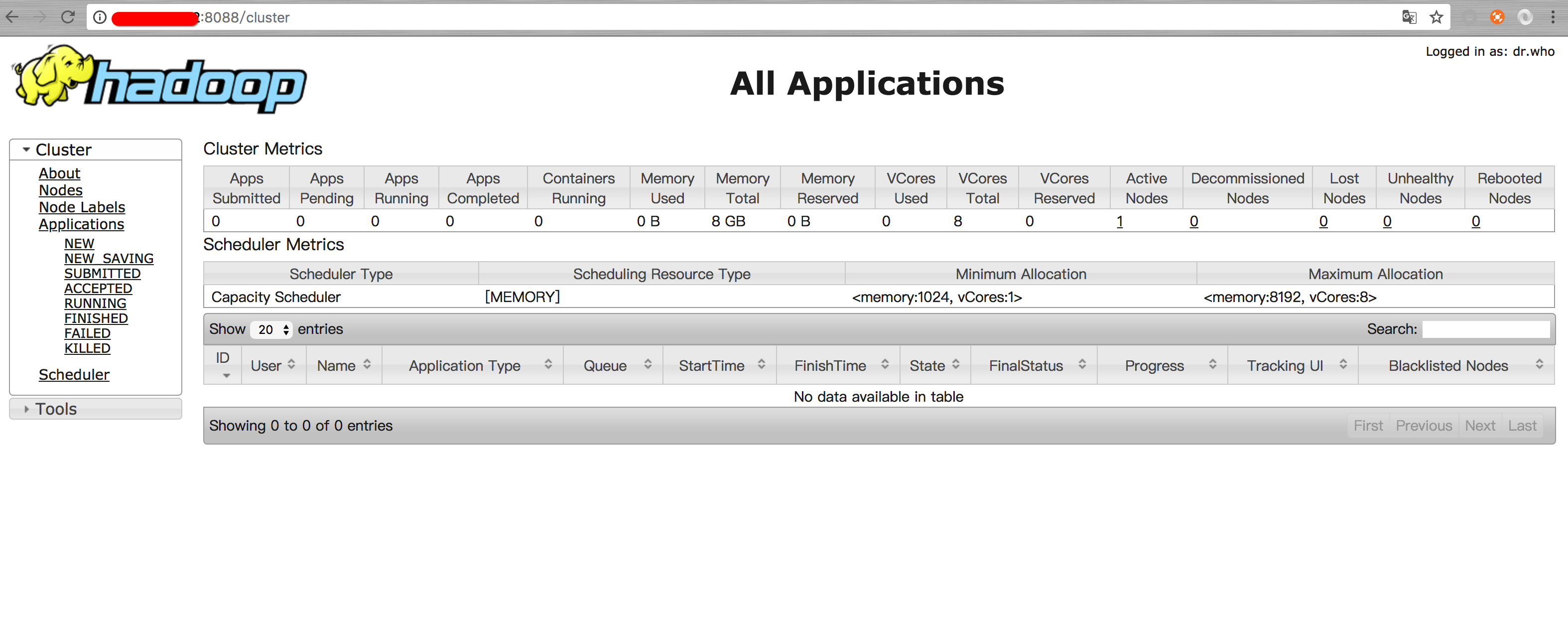
yarn界面
如果想一次性启动所有
cd /usr/local/tools/hadoop-2.7.3
./sbin/start-all.sh
本地测试worldcount
hadoop安装成功后,先直接使用linux文件系统做测试,不使用hadoop fs相关命令
#在hadoop-2.7.3文件夹中进入
cd share/hadoop/mapreduce/
#查看列表
ls
#查看hadoop-mapreduce-examples-2.7.3.jar 中的类 可以看到里面包含worldCount.class
jar tvf hadoop-mapreduce-examples-2.7.3.jar
#创建准备测试的数据
#在根目录下创建input目录
sudo mkdir -p dataLocal/input/
#赋予写权
sudo chmod -R a+w dataLocal/input/
#进入目录并填充数据 二次填充file2
cd dataLocal/input/
sudo echo "hello world, I am jungle. bye world" > file1.txt
sudo echo "hello hadoop. hello jungle. bye hadoop." > file2.txt
sudo echo "the great software is hadoop." >> file2.txt
#计数file2
#执行前需把input文件传到hdfs
#查看hdfs当前文件
hdfs dfs -ls /
#创建input文件夹
hadoop fs -mkdir -p /input
#本地文件推送到hdfs的input目录下
hdfs dfs -put dataLocal/input/file2.txt /input
#如果要计数所有txt文件可
#hdfs dfs -put dataLocal/input/*.txt /input
#如果缺省路径默认表示 user/{user_name}下 这边我output缺省默认放在了 /user/hadoop/下
hadoop jar /usr/local/tools/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input output
#如果报了There are 0 datanode(s) running and no node(s) are excluded in this operation.的异常,先jps查看datanode进程是否正在运行 且namenode的9000端口(core-site.xml文件中的fs.default.name节点配置,所有的DataNode都要通过这个端口连接NameNode)是否开启,防火墙是否允许 也有可能是两次格式化hadoop 导致没有datenode 解决方案 找到hdfs-site.xml设置的dfs.name.dir的路径/usr/hadoop/hdfs/name 删除下面的current文件夹 之后重新格式化hadoop namenode -format 重启下hdfs和yarn
#jps继续查看datenode是否启动 如果仍未启动 可能是因为datanode的clusterID 和 namenode的clusterID(第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变) 总之就是得让datanode启动
#查看输出的output
hadoop dfs -ls ./output
#查看内部输出worldcount MapReduce后的结果
hadoop dfs -cat ./output/*
hadoop dfs -cat ./output20180509230557/*
#删除hdfs文件 假设删除/inputfile1
hadoop dfs -rmr /inputfile1
#如果想计算dataLocal/input/目录下所有文件的wordcount
hdfs dfs -put dataLocal/input/*.txt /input
hadoop fs、hadoop dfs、hdfs dfs区别
hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。
本地测试worldcount
hadoop安装成功后,先直接使用linux文件系统做测试,不使用hadoop fs相关命令
#在hadoop-2.7.3文件夹中进入
cd share/hadoop/mapreduce/
#查看列表
ls
#查看hadoop-mapreduce-examples-2.7.3.jar 中的类 可以看到里面包含worldCount.class
jar tvf hadoop-mapreduce-examples-2.7.3.jar
#创建准备测试的数据
#在根目录下创建input目录
sudo mkdir -p dataLocal/input/
#赋予写权
sudo chmod -R a+w dataLocal/input/
#进入目录并填充数据 二次填充file2
cd dataLocal/input/
sudo echo "hello world, I am jungle. bye world" > file1.txt
sudo echo "hello hadoop. hello jungle. bye hadoop." > file2.txt
sudo echo "the great software is hadoop." >> file2.txt
#计数file2
#执行前需把input文件传到hdfs
#查看hdfs当前文件
hdfs dfs -ls /
#创建input文件夹
hadoop fs -mkdir -p /input
#本地文件推送到hdfs的input目录下
hdfs dfs -put dataLocal/input/file2.txt /input
#如果要计数所有txt文件可
#hdfs dfs -put dataLocal/input/*.txt /input
#如果缺省路径默认表示 user/{user_name}下 这边我output缺省默认放在了 /user/hadoop/下
hadoop jar /usr/local/tools/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input output
#如果报了There are 0 datanode(s) running and no node(s) are excluded in this operation.的异常,先jps查看datanode进程是否正在运行 且namenode的9000端口(core-site.xml文件中的fs.default.name节点配置,所有的DataNode都要通过这个端口连接NameNode)是否开启,防火墙是否允许 也有可能是两次格式化hadoop 导致没有datenode 解决方案 找到hdfs-site.xml设置的dfs.name.dir的路径/usr/hadoop/hdfs/name 删除下面的current文件夹 之后重新格式化hadoop namenode -format 重启下hdfs和yarn
#jps继续查看datenode是否启动 如果仍未启动 可能是因为datanode的clusterID 和 namenode的clusterID(第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变) 总之就是得让datanode启动
#查看输出的output
hadoop dfs -ls ./output
#查看内部输出worldcount MapReduce后的结果
hadoop dfs -cat ./output/*
hadoop dfs -cat ./output20180509230557/*
#删除hdfs文件 假设删除/inputfile1
hadoop dfs -rmr /inputfile1
#如果想计算dataLocal/input/目录下所有文件的wordcount
hdfs dfs -put dataLocal/input/*.txt /input
hadoop fs、hadoop dfs、hdfs dfs区别
hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。
下面用idea编写wordcount程序
1.mac本地运行wordcount(localohost),前提是本机装有hadoop(mac安装步骤与在linux上大致相同)
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Created by LJW on 2018/5/9.
* 本地运行wordCount
*/
public class WordCount {
/**
* 用户自定义map函数,对以<key, value>为输入的结果文件进行处理
* Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。
* 通过在map方法中添加两句把key值和value值输出到控制台的代码
* ,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。
* 然后StringTokenizer类将每一行拆分成为一个个的单词
* ,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。 每行数据调用一次 Tokenizer:单词分词器
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//由于该例子未用到key的参数,所以该处key的类型就简单指定为Object
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
/**
* 用户自定义reduce函数,如果有多个热度测,则每个reduce处理自己对应的map结果数据
* Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。
* Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,
* 所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
*/
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
try {
Job job = Job.getInstance(conf, "word count");
//如果不是本地 使用setJarByClass指定所在class文件
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//原文件目录 待计算
String path1 = "hdfs://localhost:9000/input";
//正常情况输出路径每次都要删除再通过计算填充 为方便测试每次输出到一个新的路径
String path2 = "hdfs://localhost:9000/output" + new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
FileInputFormat.addInputPath(job,new Path(path1));
// if(fs.exists(path2)) {
// fs.delete(path2, true);
// System.out.println("存在此输出路径,已删除!!!");
// }
//输出文件目录 计算之后的输出目录
String time = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true) ;
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
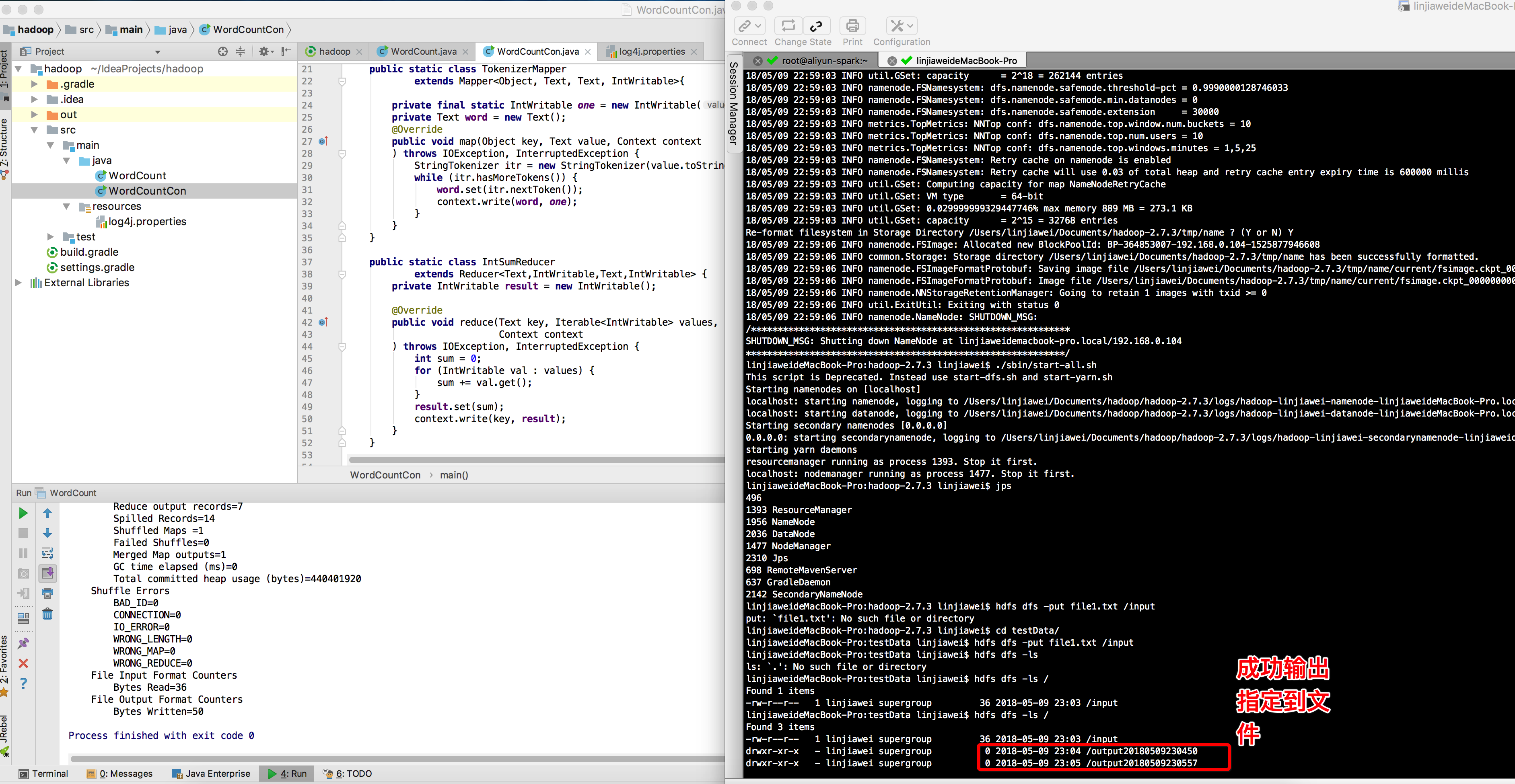
后续遇到的坑
博主在阿里云hadoop启动了很长一段时间后,发现突然就关闭不了服务了
网上查询可能有以下原因
①hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux默认会每隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和hadoop-hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程(最常见)
②环境变量 $HADOOP_PID_DIR 在你启动hadoop后改变了
③用另外的用户身份执行stop-all
目测我的是因为第一个原因,解决方案
①ps -ef | grep java | grep hadoop 查找hadoop的所有相关进程,再次jps查看只剩jps。
②修改$HADOOP_HOME/conf/hadoop-env.sh里边,去掉export HADOOP_PID_DIR=/var/hadoop/pids的#号,创建/var/hadoop/pids或者你自己指定目录





