在认识爬虫中我给自己设定一个目标就是学习模拟登录。但是目前的知乎、豆瓣都要输入验证码,本以为可爱的简书是不会的,结果他居然要滑动图块解锁。但是学技术总要先会一点简单的呀,于是我就拿我自己的个人网站xuzhougent.top开刀了。由于阿里云服务器6-17号到期了,一时半会我也没有续期的打算,所以估计你们看的时候,这个域名已经打不开了。
背景知识
这个部分其实打算放在最后作为补充阅读的,但是作为一个懒人深知大家会直接翻到后面看重点,但是我觉得这一部分对于理解代码更加重要,所以我就自作主张提前了。
1. Request objects
Scrapy使用Request和Response对象爬取网站。通常而言,Request从spiders从产生,到Downloader时执行request返回Reponse对象。Response返回到发出request的爬虫里。先看下源码中Request类:
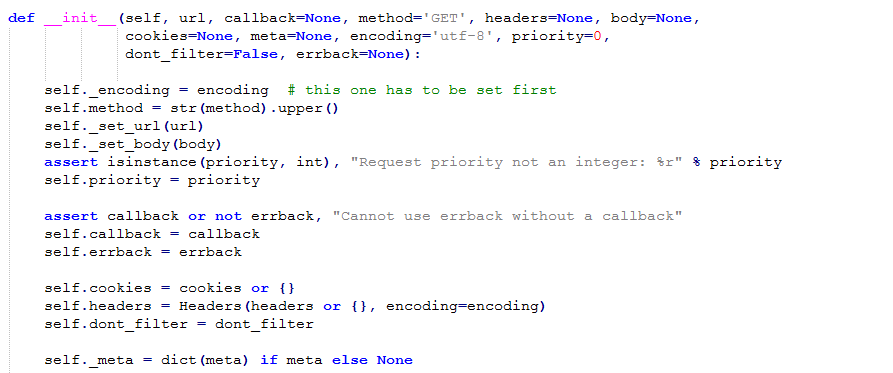
简单解释下里面的各个参数:
- url: 请求的地址
- callback:指定用来解析当前request产生的reponse的parse
- method: http方法,默认是'GET'
- meta:一个Python字典(dict),用于初始Request.meta值。起始为空,由不同的Scrapy组件进行填充注:HTTP.meta包含本次HTTP请求的Header信息,比如用户的IP地址和用户Agent
- body: 请求主体,不太懂,并且只能通过replace方法进行修改。待编辑
- headers:本次请求的headers,一般是浏览器信息
- cookies: 请求的cookies。模拟登陆的重要成员。
- encoding(string):编码方式,默认为'utf-8'。如果解析得到的item是乱码的,说明这个网站可能是其他编码方式,似乎京东是gbk的。
- priority(int): 请求的优先度,目前用不到
- dont_filter(boolean):因为scrapy会默认过滤掉重复的request,如果你需要对一个网站发起多次request,那么请设为False
- errback: scrapy会无视掉一些404等错误返回,如果你需要对这些错误返回进行爬取(比如说腾讯的公益404页面),你可以指定一个parse。
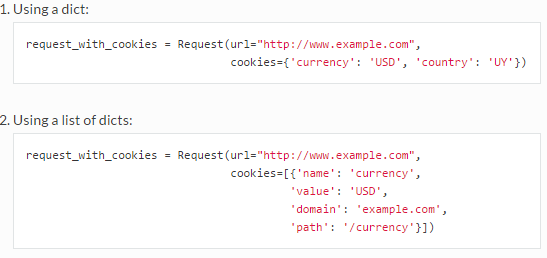
Cookie是http消息头中的一种属性,简单说明下,大致有以下内容:
- Cookie名字(Name)Cookie的值(Value)
- Cookie的过期时间(Expires/Max-Age)
- Cookie作用路径(Path)
- Cookie所在域名(Domain),使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
用法如下:
2.模拟登陆的重点scrapy.http.FormRequest(url[, formdata, ...])
前面讲的基础的Request,scrapy还在此基础上定义了一个FormRequest用于向表格发起request,除了Request基本功能外,还定义了一个非常重要的类方法 from_response(response[,formname=None,formnumber=0,formdata=None,formxpath=None,formcss=None,clickdata=None, dont_click=False, ...])。老规矩,先解释一下各个参数:
- response: 用于在responses找到填写的web登录表单
- formname: 非必须,要填写web登录表单的名称
- formxpath和formcss:非必须,都是用来在responses定位web登录表单
- formnumbe:非必须,假如web登录表单有多个,用int指定其中一个。0表示第一个
- clickdata(dict): 查找控制点击的属性如(<input type="submit">)。默认使用web表单第一个可以点击元素。
- dont_click(boolean):假如这个web表单使用js控制,输入完自动提交,不需要点击,那么设置为false。
实战使用
没想到模拟登陆的背景知识写了那么多,如果你没看背景知识直接跳到这里,没有关系,那么下面代码有任何不懂的都可以在上面找到解释。
步骤一:
通过开发者工具找到要request的URL以及要填写的表单内容。我的网站比较好找就定义了一个login,填写的数据有4个。以前看到一个方法就是输入错误的登录账号密码进行查找,而且打开Preserver log以免登陆成功后login被覆盖掉。其中csrf_token是防止跨站工具的信息,需要在获取网页后查找
得到。
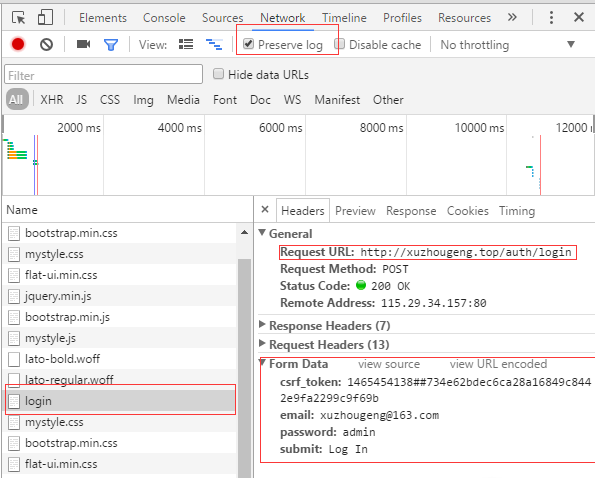
步骤二:思路整理
所谓爬虫就是模拟人去查看网页,所有写任何代码前,我们都先要想自己是如何做的,然后在编写代码让爬虫也模仿我们。
- 打开登录页面
- 输入账号密码
- 页面重定向到目标页面
步骤三:写代码
由于前面的背景知识铺垫很多,所以接下来就直接上代码了:
# -- coding: utf-8 --
import scrapy
from scrapy.http import Request, FormRequest
class LoginSpider(scrapy.Spider):
name = "login"
allowed_domains = ["xuzhougeng.top"]
#向登录页发起请求,得到下一步需要的response
def start_requests(self):
return [Request('http://xuzhougeng.top/auth/login', callback=self.post_login)]
## 首先查看一下自己的状态,需要sign in。所以填写好表单,用FormRequest.from_response提交,这时候网页会返回一个重定向的response给我们,我们用after_login处理
def post_login(self, response):
sign_in = response.xpath('//*[@id="navbar-collapse-01"]/ul[2]/li/a/text()').extract()[0]
print(sign_in)
csrf = response.css('div > input::attr(value)').extract_first()
return FormRequest.from_response(response,formdata=
{'csrf_token':csrf,
'email':'admin@admin.com',
'password':'password',
'remember_me':'y',
'submit:':'Log In'
},callback=self.after_login)
### 检查登录状态
def after_login(self, response):
sign_out = response.css('#signin_icon > a::text').extract()
print sign_out
下面是cmd的运行结果。

这篇主要是初步学习模拟登陆,所以很多的基础知识,下面我想去试试登陆豆瓣和知乎,以及简书了,估计又要学很多东西。可能要学习一下Linux的网络编程去。