为什么我们要让爬虫模拟登陆呢?
- 有些内容只有登陆才能进行爬取,如知乎,不登录的主页只能看到注册和登陆 ;
- 你想爬取自己的个人信息
有什么方法呢?
cookie
在互联网发展的早期,由于大家的服务器都不是太好,所以服务端不会记住你的个人信息,这会增加服务器的压力。因此早期的连接都是一次性的,服务器在不会记得你什么时候来过,也不知道你做了什么。但是随着服务器的升级换代,淘宝这类网站需要记住你的个人信息,这样你下次访问的时候可以继续上次的工作。但是http协议依旧保持了无状态的特性,cookies应运而生。cookies在访问服务器后会记录在浏览器上,这样就可以在客户端下次访问的时候想起它是谁了。HTTP持久连接
在没有持久连接之前,为获取每一个URL指定的资源都必须建立一个独立额TCP连接,一方面加重了HTTP服务器的负担;另一方面由于服务器不会记住客服端,导致我们需要每一个请求都要执行登录操作。但是有了HTTP持久连接后,我们对同一个主机的多次请求会使用同一个TCP连接。因此登录后就可以保持这类状态进行请求操作。
实现方法!
针对方法1,我们只要从在浏览器获取cookie,然后带着cookie进行访问就行了,如下:
-
利用chrome的开发者工具获取cookies
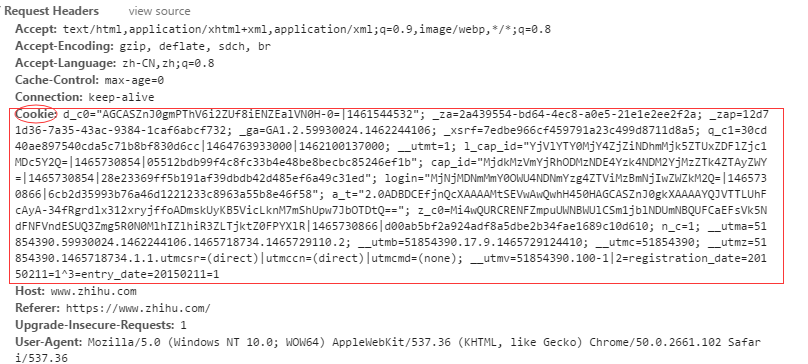 获取cookies
获取cookies 填写cookies
cookies = {'cookie':'红框部分'}带cookies发起请求:
html = requests.get(url,cookies=cookies).content
针对方法2,我们使用requests的Session类进行持久连接,就直接上代码了哦
#导入必要的库
import requests
from bs4 import BeautifulSoup
url = 'https://www.zhihu.com/#signin'
session = requests.Session() #实例化Session
wb_data = session.get(url).text
soup = BeautifulSoup(wb_data,'lxml')
# 填写登录表单
xsrf = soup.select('input[value]')[-1].get('value')
data = {
'_xsrf': xsrf,
'password': 'your password',
'remember_me': 'true',
'email': 'your email'
}
# 提交表单
log_post =session.post('http://www.zhihu.com/login/email', data=data)
url = 'https://www.zhihu.com/'
test = session.get(url)
wb_data = BeautifulSoup(test.text, 'lxml')
# 检验是否成功登录
wb_data.select('#feed-0 > div.feed-item-inner > div.feed-main > div.feed-content > h2 > a')
结语
HTTP持久链接和Cookies其实没有冲突,虽然我说是两种方法,但是你可以在使用cookies免提交表单登陆的时使用Session,这样只需要第一次get的时候带上cookies,剩余操作就不需要cookies了。
但是我使用cookies发现还是不能变成登陆状态,我也是很忧伤。但是你可以在模拟登陆后,然后取得cookies信息,用获得的cookies登陆,不过这就失去用cookie免登陆的价值了。
当我用jupyter notebook发现无法使用cookie让服务器认识我,当我用命令行时候,同样的代码反而没有问题,我无奈了。



