写在前面
这是Scrapy学习的基础部分,大部分内容来自于官方文档的个人解读,不太适合那些想在30分钟以内学会Scrapy的人学习,但是如果你在看那些xx分钟入门Scrapy的时候存在疑问,可以翻看这篇查查相关内容。如果感觉我写的有任何不对的地方,欢迎提出疑问,我会及时回复的。
scrapy.spiders.Spider
scrapy.spiders.Spider是Scrapy框架最核心部分之一,定义了如何爬取网站和获取结构化信息等。
查看源码发现Spider定义了from_crawler, sest_crawler, start_requests, make_requests_from_url, parse, update_settings, handles_request, close等function,而在官方文档规定了自定义的爬虫必须继承Spider类,要有至少以下几个模块:
-
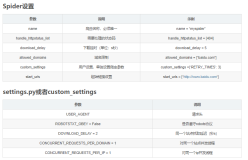
name: 必须,没有他scrapy crawl 找不到入口 -
allowed_domains:可选,如果你怕从知乎爬到果壳,请可以定义一个字符串的list,并且OffsiteMiddleware
处于开启状态 -
start_urls:一个URLs list,爬虫的起点网页 -
custom_settings:仅在爬虫运行时覆盖来自settings的设置,低手不知道怎么玩 -
logger: 一个日志记录者,以后再debug的时候再说吧 -
from_crawler:这是Scrapy 用于创建自定义爬虫的类方法(class method),目前你不需要对他动手,这个方法会设置(set)crawler和settings -
settings:运行爬虫时的配置,是Settings的实例,低手不会玩 -
crawler:在类初始化后由from_crawler设置,链接到绑定的spider的Crawler类,涉及到Crawler API ,低手用不来。 -
start_requests():当start_urls有URLS即不为空时,会调用start_requests(),接着它会继续调用make_requests_from_url去Request每一个url。所以我们可以不用定义start_urls,而在这里自定义一个start_requests,使用其他Request,如FormRequest然后callbck(反馈)给自定义的parse。注:start_requests在爬虫运行只会执行一次。 -
make_requests_from_url(url):前面说过,这个方法接收urls,返回reponse, 返回的response会默认(callback)传递给parse。 -
parse(response):如果没有自定义start_requests(),那么必须定义这个函数,并且在里面定义网页数据提取方法,十分重要哦。 -
log(message[, level, component]):和上面的logger差不多,debug时候再仔细研究吧 -
closed(reason):在爬虫关闭的时候调用,不太懂也不会用,这里先占位
Link Extractors(链接提取器)是一类用来从返回网页中提取符合要求的链接
Rule有以下几个参数
- link_extractor为LinkExtractor,用于定义需要提取的链接。
- callback参数:当link_extractor获取到链接时参数所指定的值作为回调函数。注:不能使用parse作为回调函数。
- follow:指定了根据该规则从response提取的链接是否需要跟进。callback为None,默认值为true。
- process_links:主要用来过滤由link_extractor获取到的链接。
- process_request:主要用来过滤在rule中提取到的request。
官方提供的例子:
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
def start_requests(self):
yield scrapy.Request('http://www.example.com/1.html', self.parse)
yield scrapy.Request('http://www.example.com/2.html', self.parse)
yield scrapy.Request('http://www.example.com/3.html', self.parse)
def parse(self, response):
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)