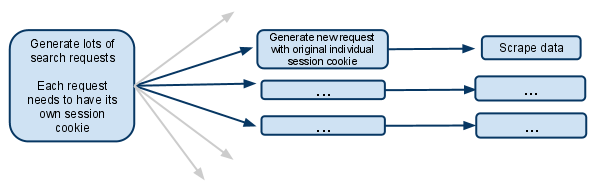
我在Python爬虫基础-模拟登陆曾经谈过Cookies和Session。那么如何我想使用Scrapy进行模拟登陆,那么肯定要逃不过Cookies和Session。这篇文章主要为了解决下图这个问题,即如何管理为每一个独立的请求保留其对应的cookies。
图片来自互联网
幸运的是官方文档给了解决方案。
Multiple cookie sessions per spider
There is support for keeping multiple cookie sessions per spider by using the cookiejar
Request meta key. By default it uses a single cookie jar (session), but you can pass an identifier to use different ones.
官方给出的例子:
for i, url in enumerate(urls):
yield scrapy.Request(url, meta={'cookiejar': i},
callback=self.parse_page)
##请记住,cookjar元键(meta key)不会一直保留。你需要在后续请求重进行传递。 例如:
Keep in mind that the cookiejar meta key is not “sticky”.
You need to keep passing it along on subsequent requests. For example:
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)





