urllib是Python自带的标准库,无需安装,直接可以用。
提供了如下功能:
- 网页请求
- 响应获取
- 代理和cookie设置
- 异常处理
- URL解析
爬虫所需要的功能,基本上在urllib中都能找到,学习这个标准库,可以更加深入的理解后面更加便利的requests库。
urllib库
urlopen 语法
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
#url:访问的网址
#data:额外的数据,如header,form data
用法
# request:GET
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
# request: POST
# http测试:http://httpbin.org/
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())
# 超时设置
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read())
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
响应
# 响应类型
import urllib.open
response = urllib.request.urlopen('https:///www.python.org')
print(type(response))
# 状态码, 响应头
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
Request
声明一个request对象,该对象可以包括header等信息,然后用urlopen打开。
# 简单例子
import urllib.request
request = urllib.request.Requests('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
# 增加header
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
'Host':'httpbin.org'
}
# 构造POST表格
dict = {
'name':'Germey'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data=data,headers=headers,method='POST')
response = request.urlopen(req)
print(response.read()).decode('utf-8')
# 或者随后增加header
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {
'name':'Germey'
}
req = request.Request(url=url,data=data,method='POST')
req.add_hader('User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
Handler:处理更加复杂的页面
官方说明
代理
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http':'http://127.0.0.1:9743'
'https':'https://127.0.0.1.9743'
})
opener = urllib.request.build_openner(proxy_handler)
response = opener.open('http://www.baidu.com')
print(response.read())
Cookie:客户端用于记录用户身份,维持登录信息
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
# 保存cooki为文本
import http.cookiejar, urllib.request
filename = "cookie.txt"
# 保存类型有很多种
## 类型1
cookie = http.cookiejar.MozillaCookieJar(filename)
## 类型2
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
# 使用相应的方法读取
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
异常处理
捕获异常,保证程序稳定运行
# 访问不存在的页面
from urllib import request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason)
# 先捕获子类错误
from urllib imort request, error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print("Request Successfully')
# 判断原因
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
URL解析
主要是一个工具模块,可用于为爬虫提供URL。
urlparse:拆分URL
urlib.parse.urlparse(urlstring,scheme='', allow_fragments=True)
# scheme: 协议类型
# 是否忽略’#‘部分
举个例子
from urllib import urlparse
result = urlparse("https://edu.hellobi.com/course/157/play/lesson/2580")
result
##ParseResult(scheme='https', netloc='edu.hellobi.com', path='/course/157/play/lesson/2580', params='', query='', fragment='')
urlunparse:拼接URL,为urlparse的反向操作
from urllib.parse import urlunparse
data = ['http','www.baidu.com','index.html','user','a=6','comment']
print(urlunparse(data))
urljoin:拼接两个URL
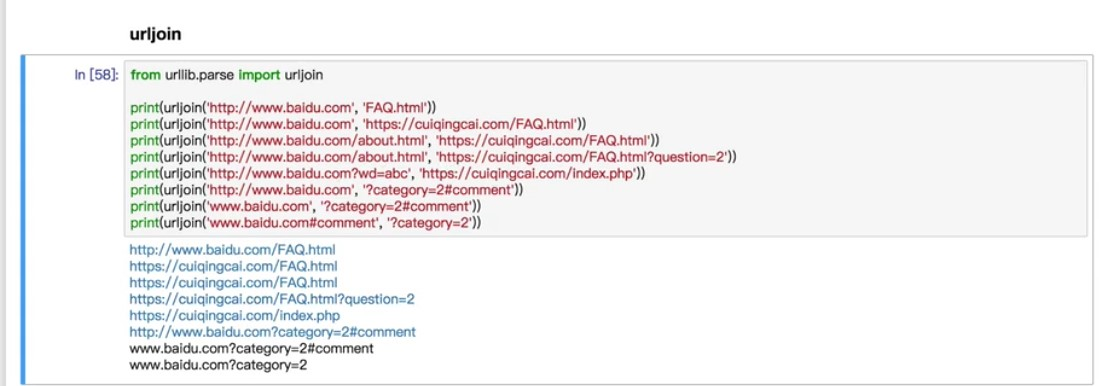
urljoin
urlencode:字典对象转换成GET请求对象
from urllib.parse import urlencode
params = {
'name':'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)
最后还有一个robotparse,解析网站允许爬取的部分。

